Es muss das Formular mit der Bestell-Nr. 224 (CITES Bescheinigung; im Shop unter Verschiedene Vordrucke, Artenschutz) des Wilhelm Köhler Verlags bedruckt werden.
Wir benötigen zwei PDFs: Eines mit dem Formular und den Formularfeldern und eines nur mit den Formularfeldern, um es auf das Formular zu drucken.
Der Verlag bietet leider keine PDFs an, daher habe ich mir angesehen, ob ich mit vertretbarem Aufwand das Formular nachbauen kann.
Zur PDF Bearbeitung verwende ich Adobe Acrobat Pro.
Der perfekte Scan als Vorlage
Formular als PDF scannen. Anschließend auf einem zweiten Formular ausdrucken und neu scannen, bis Ausdruck und Formular übereinstimmen.
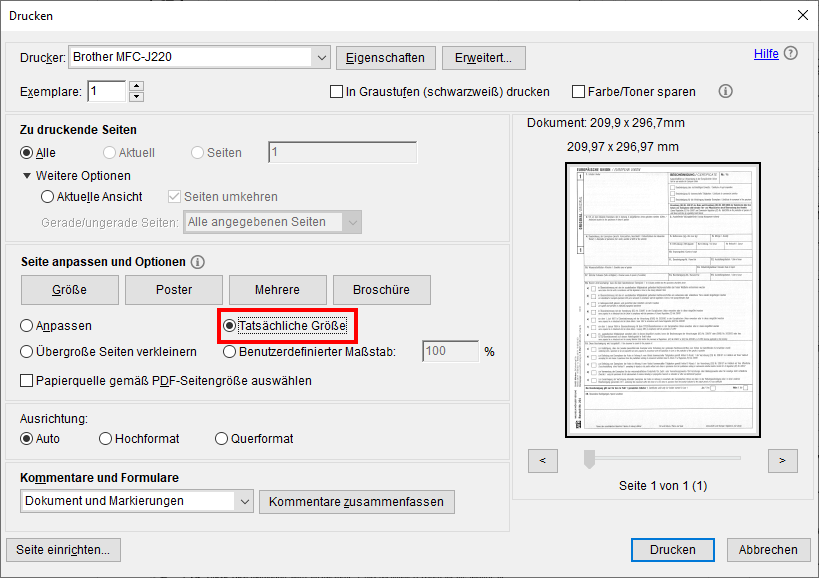
Dabei ist es wichtig, die "Tatsächliche Größe" beim Druck auszuwählen. Voreingestellt ist "Übergroße Seiten verkleinern", was das Druckergebnis verzerrt.
Formularfelder setzen
Das PDF mit dem Scan in Adobe Acrobat Pro öffnen.
Aus den Tools "Formular vorbereiten" auswählen:
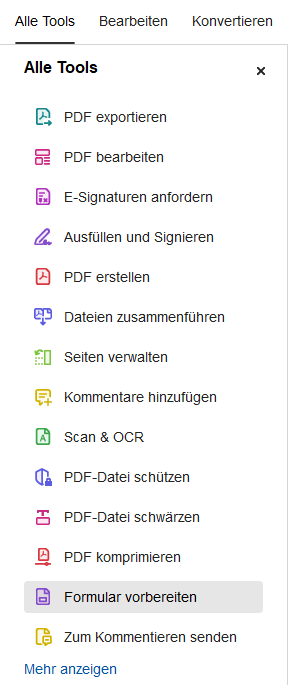
Adobe konnte keine Formularfelder identifizieren:
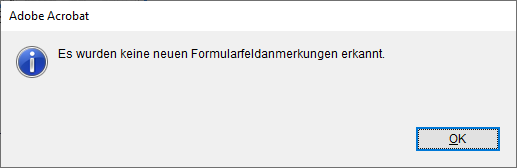
Wir setzen die Felder per Hand, und richten sie anschließend aus, zB mehrere Textfelder am linken bzw. rechten Rand auswählen und in den Eigenschaften unter Position Links, bzw. Rechts, gleich setzen, Breite anpassen etc.
Einige Felder können mehrzeilig sein, das wird in den Eigenschaften unter Optionen aktiviert.
Bei den Kontrollkästchen wird die Randfarbe auf "Keine Farbe" gesetzt und der Kontrollkästchenstil auf "Kreuz".
Alle Formularelemente sind im Text Schriftgrad: "Auto"
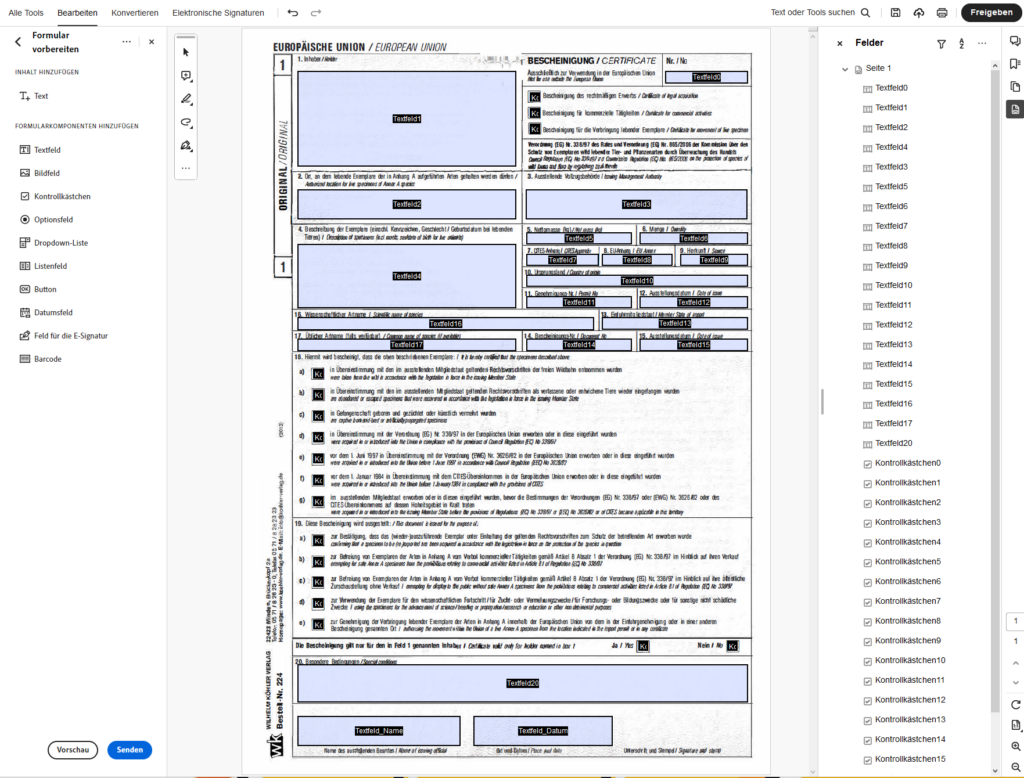
Das so bearbeitete PDF wird mit Daten befüllt und von mehreren Mitarbeitern auf Formulare gedruckt, bis die Positionierung der Felder verifiziert ist. Dabei ist wichtig, die "Tatsächliche Größe" beim Druck auszuwählen.
Bei einigen Ausdrucken war grade im unteren Bereich eine leichte Verschiebung zu sehen. Vermutlich war das Formular nicht immer 100%ig grade eingelegt, aber bei ganz genauer Betrachtung stellte sich auch heraus, dass der Scan ganz leicht schief ist.
Scan to PDF
Dass im Hintergrund ein gescanntes Formular verwendet wird, gefällt mir nicht so gut, zB sieht es an einigen Stellen "fleckig" aus, was von dem besonderen Papier des Formulars herrührt. Daher habe ich den Versuch gestartet, aus dem Scan ein PDF zu generieren.
Der erste Versuch schlug grundlegend fehl, da das Programm nicht mit den hochkant stehenden Schriften (unten links, "Bestell-Nr. 224" etc.) zurecht kommt. Daher muss der Scan vorbereitet werden, indem diese Schrift entfernt wird, zumal wir sie auch nicht benötigen.
Scan vorbereiten
Mit dem Tool PDF24 Creator habe ich das Bild aus dem PDF extrahiert und eine TIFF-Datei erhalten.
Die Datei öffne ich mit Paint.net, füge eine weitere Ebene hinzu, die in den Hintergrund kommt, diese wird weiß aufgefüllt.
Die Schrift wird entfernt.
Mit dem Zauberstab-Tool wird so viel wie möglich entfernt, da einiges "Rauschen" im Hintergrund ist. Dazu stelle ich die Toleranz auf einen niedrigen Wert und aktiviere "Globale Auswahl" in der oberen Leiste. Dies ermöglicht es dem Zauberstab, alle passenden Pixel im gesamten Bild auszuwählen, nicht nur zusammenhängende Bereiche.
Als png speichern.
Scan to Docx
In Adobe Acrobat Pro ein PDF aus der png-Datei erstellen.
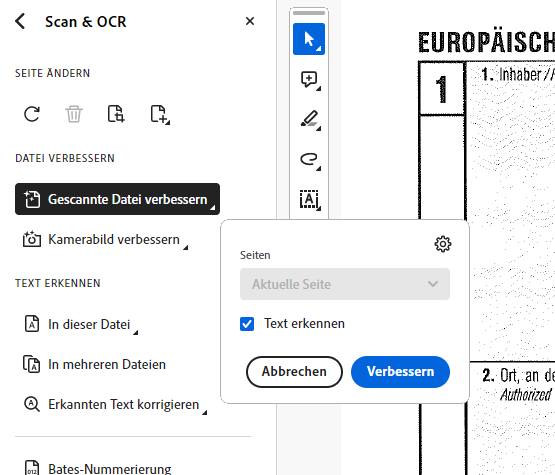
Aus dem Alle Tools Menu Scan & OCR auswählen. Gescannte Datei verbessern. Und dann Text erkennen -> In dieser Datei.
Speichern unter: Konvertieren in "Windows Word (*.docx)"
Docx to PDF
In Adobe Acrobat Pro ein PDF aus der docx-Datei erstellen.
Der erste Versuch sah bei mir schon ganz gut aus:

Fazit
Leider war es dann so, dass ich bei späteren Versuchen schlechtere Ergebnisse erzielt habe. Warum die Ergebnisse teilweise sehr voneinander abweichen konnte ich nicht herausfinden.
Das Vorgehen, um von einem analogen Formular einen digitalen Klon zu erzeugen, funktioniert grundsätzlich. Allerdings war es auch sehr zeitaufwändig und am Ende frustrierend, da ich nicht nachvollziehen konnte, warum auf einmal die PDFs immer schlechter wurden.
Jetzt ist erstmal Ende meiner Motivation und des Budgets.