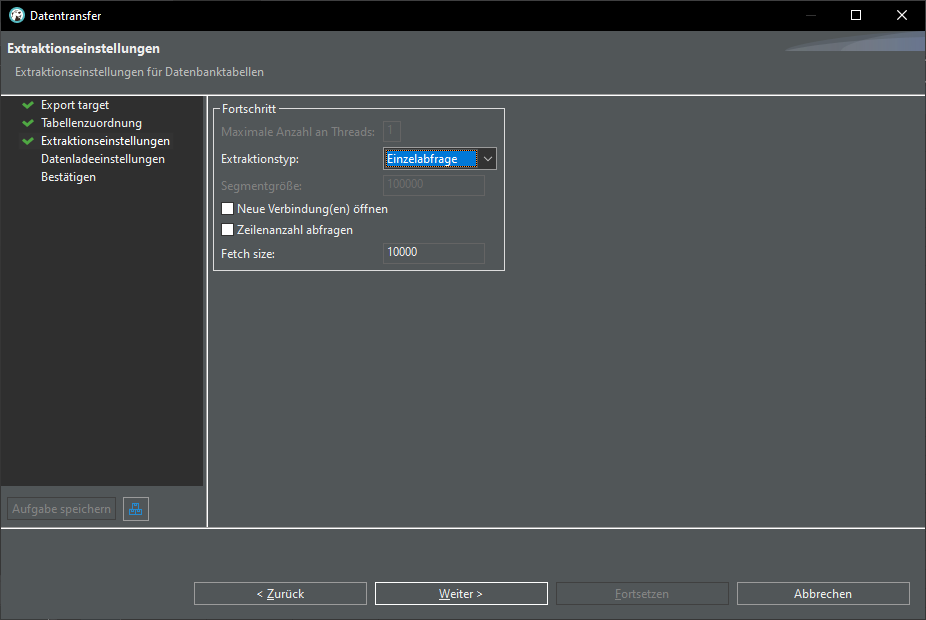
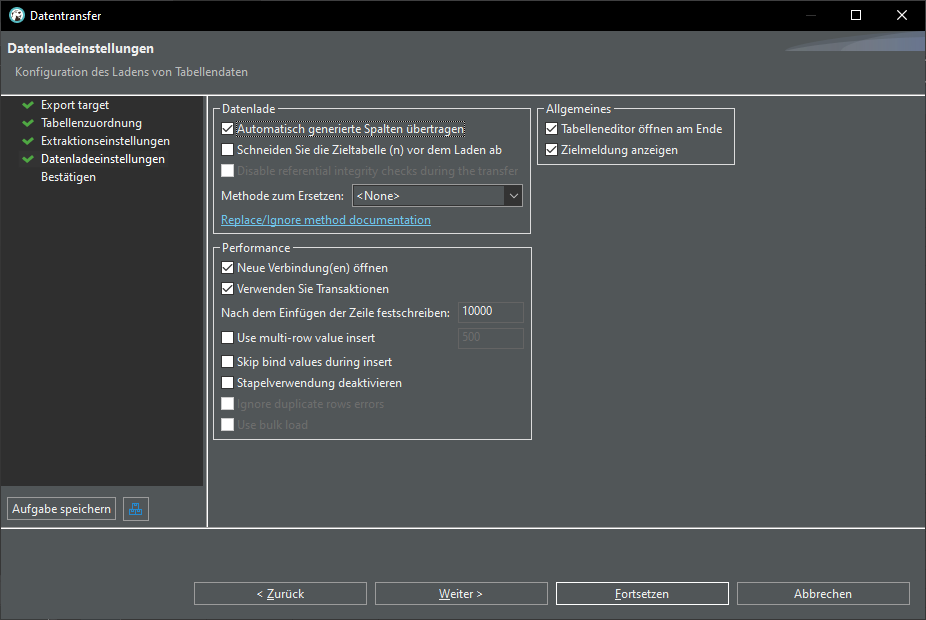
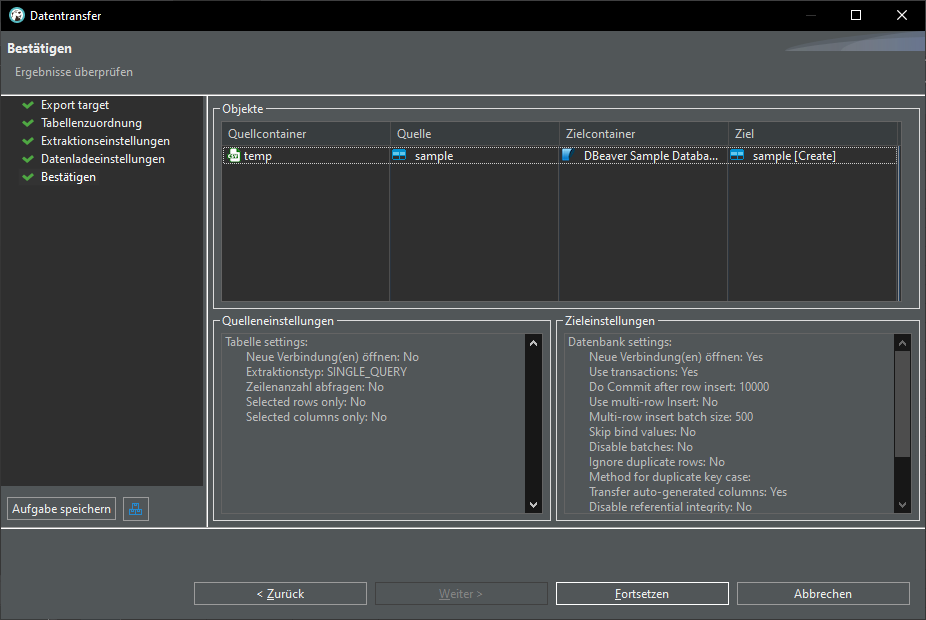
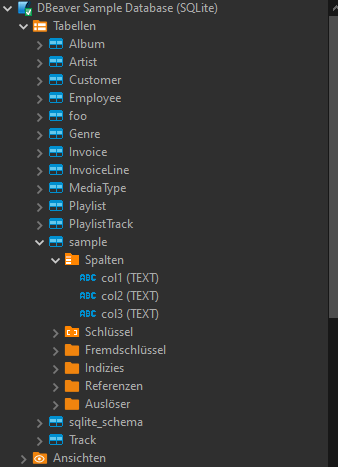
There are many ways to work with data, here is a quick walkthrough how to transfer data from an Excel file into a database.
Excel-File -> CSV-File -> DBeaver -> PostgreSQL
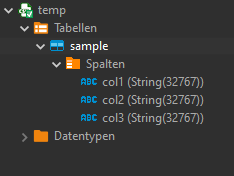
Excel file
We have a simple Excel file:
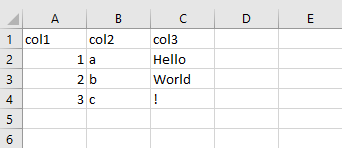
with a simple sample data structure:
Excel file conversion
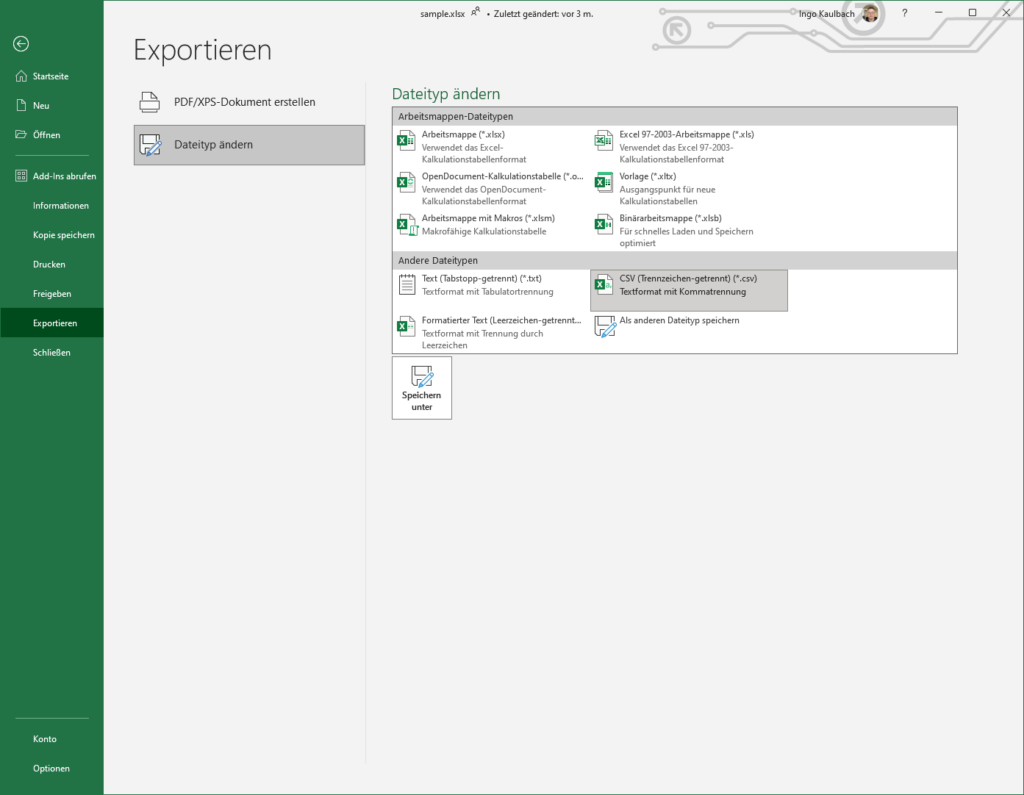
We need to convert the Excel file into a .csv (Comma Seperated Values) file.
Just open the file -> Datei -> Exportieren > Dateityp ändern -> CSV and save as sample.csv
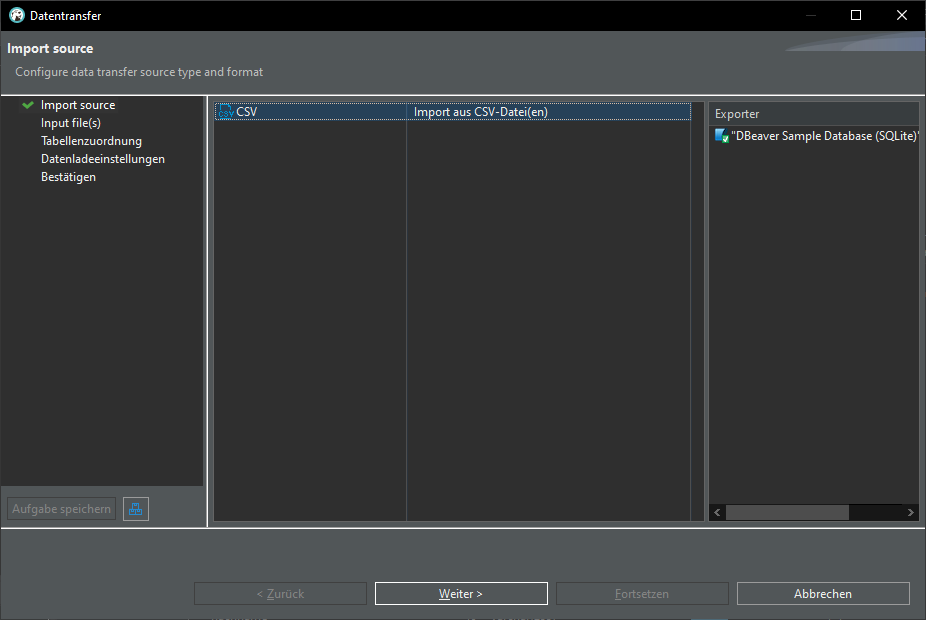
Import from CSV
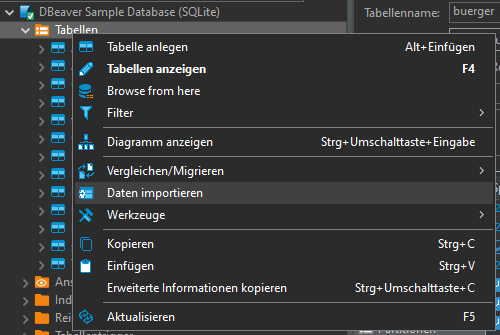
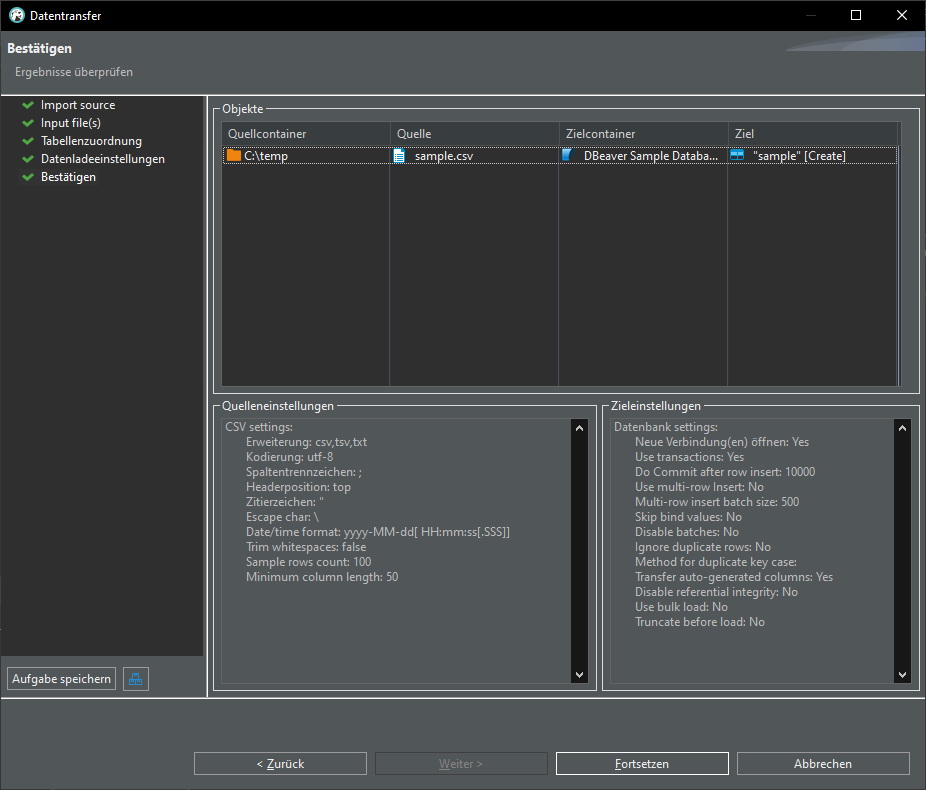
In DBeaver:
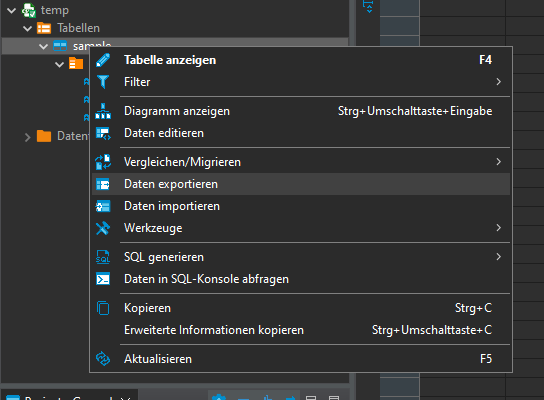
Open Database connection -> database -> schema -> Rightclick -> Data import:
Import from CSV:
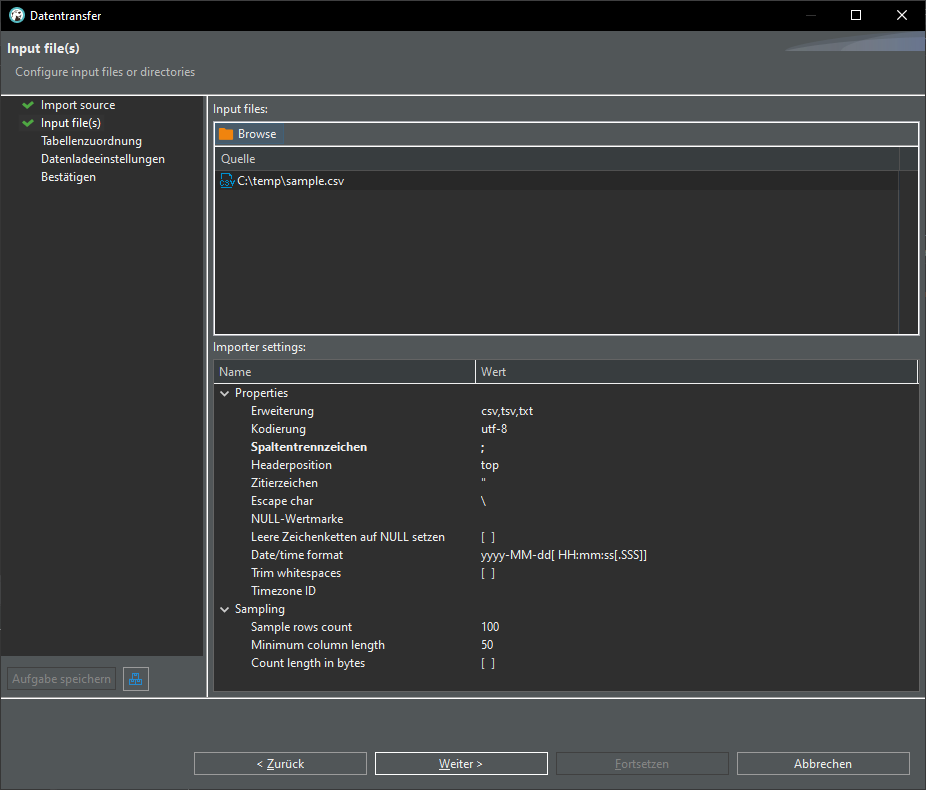
Change delimiter (Spaltentrennzeichen) from , to ;
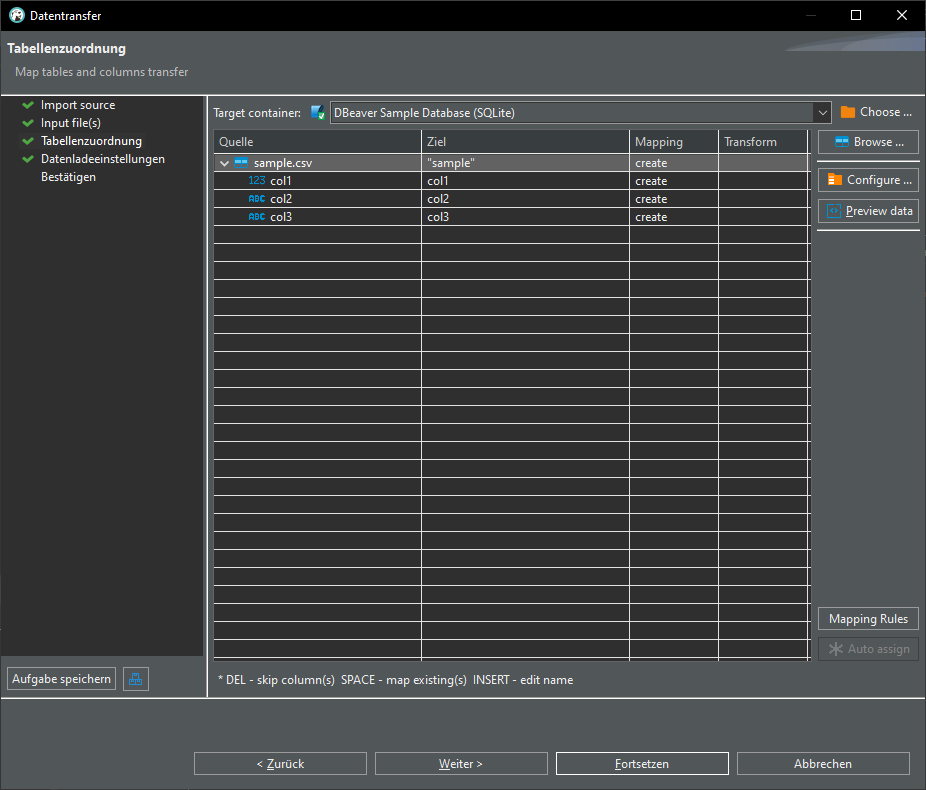
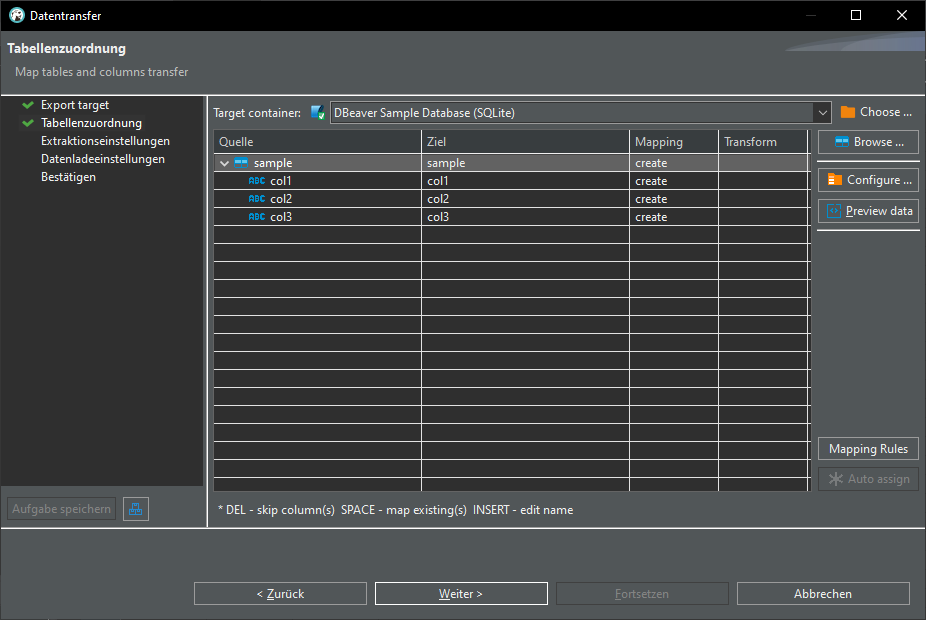
click "Auto assign", change target to "sample"
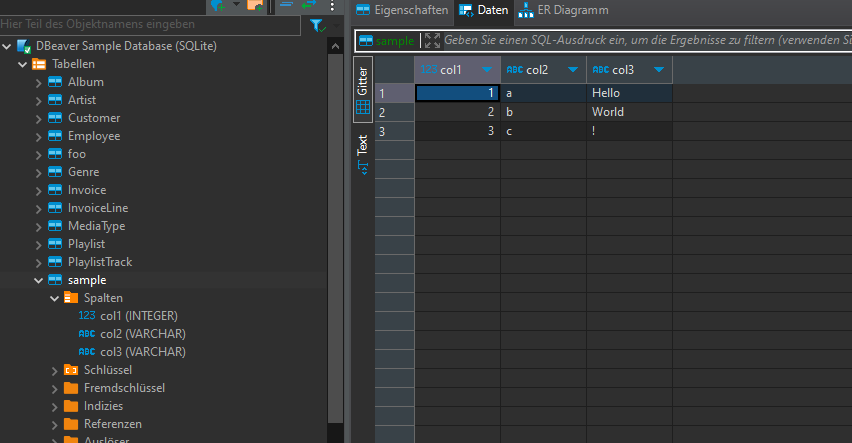
TADA! We have a new table "sample" in our database:
Create CSV connection
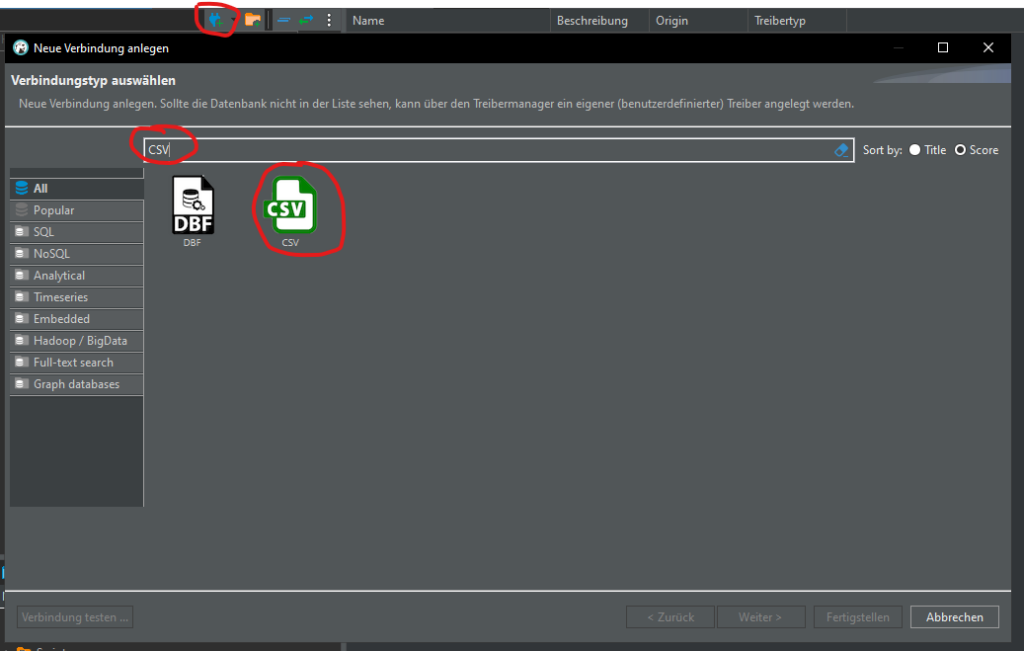
Let's try another way. Delete table "sample" and create a connection to the CSV file:
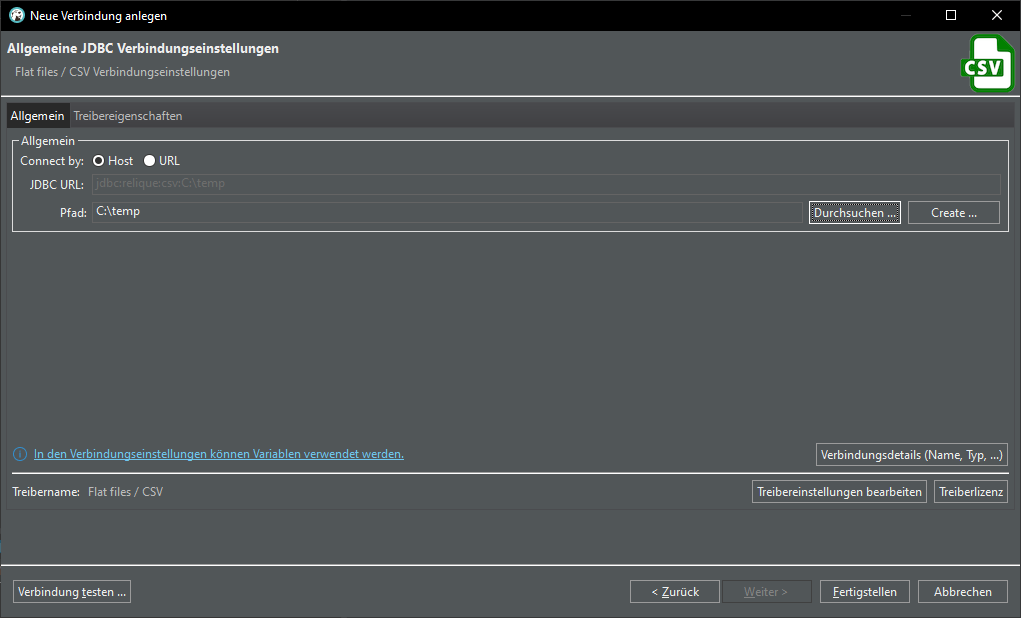
Click Browse… and select the folder where your csv file is that you saved from Excel. You’re selecting a folder here, not a file. The connection will load ALL csv files in that folder. Click Finish.
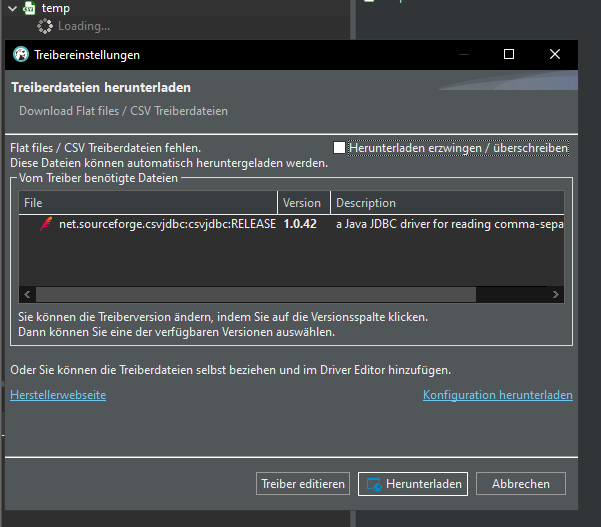
Download the driver, if using for the very first time:
You will now see a new connection; this connection is set up exactly like a regular connection. Each csv file in your folder will be set up as a table with columns.
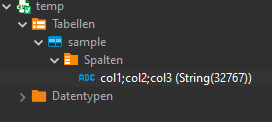
But there is a problem with the columns, it's just one, not three:
Doublecheck delimiter, but it is already set to ;
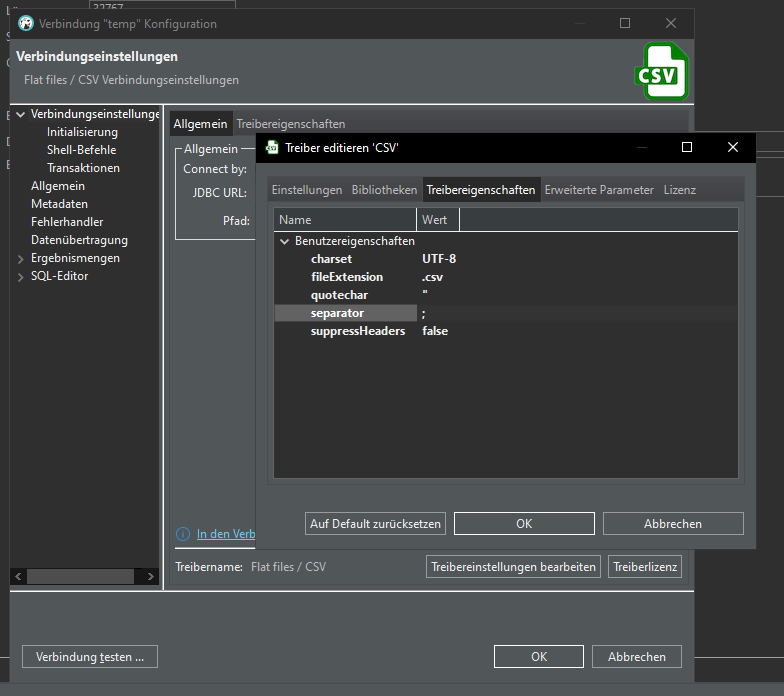
Ah, in driver details we have to set the separator from , to ;
Looks better now:
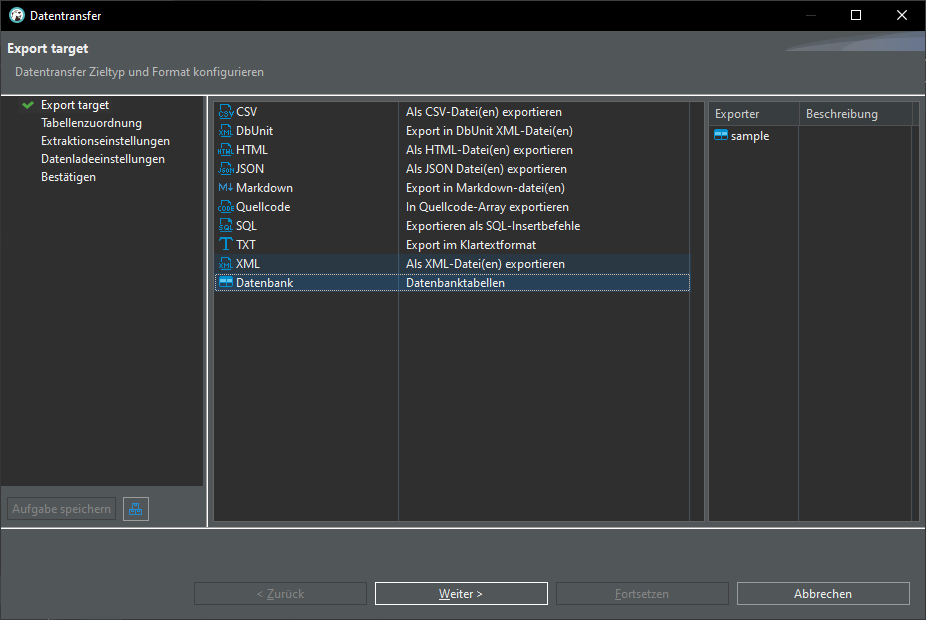
Export CSV data into database:
Once again we have our sample table in our database:
Die Sourcen des DBFSample finden sich wie immer im GitHub.
Das DBFSample ist ein PoC um eine DBF Datei mit Java verarbeiten zu können.
Im Projekt haben wir einige DBF Dateien erhalten, deren Daten wir importieren/verarbeiten müssen. Das soll nicht meine Aufgabe sein, aber ich möchte für den Fall vorbereitet sein, dass ich dabei unterstützen darf.
Ich brauche also erstmal nur verstehen, was eine DBF Datei ist und wie ich grundlegend damit arbeiten kann.
Was ist eine DBF Datei
Eine DBF-Datei ist eine Standarddatenbankdatei, die von dBASE, einer Datenbankverwaltungssystemanwendung, verwendet wird. Es organisiert Daten in mehreren Datensätzen mit Feldern, die in einem Array-Datentyp gespeichert sind.
Aufgrund der frühzeitigen Einführung in der Datenbank und einer relativ einfachen Dateistruktur wurden DBF-Dateien allgemein als Standardspeicherformat für strukturierte Daten in kommerziellen Anwendungen akzeptiert.
https://datei.wiki/extension/dbf
Wie kann ich eine DBF Datei öffnen?
DBeaver
Da es sich um ein Datenbankformat handelt und ich grade das Tool DBeaver in meinen Arbeitsalltag eingeführt habe, lag es für mich nahe, die Datei mit DBeaver zu öffnen.
Dazu musste ich einen Treiber zu DBeaver hinzufügen um anschließend die Datei öffnen zu können. Ich konnte dann die Tabellenstruktur sehen, aber nicht auf die Tabelle zugreifen. Es gab eine Fehlermeldung, dass eine weitere Datei fehlen würde.
java.sql.SQLException: nl.knaw.dans.common.dbflib.CorruptedTableException: Could not find file 'C:\dev\tmp\adress.dbt' (or multiple matches for the file)
DBeaver Stack-Trace
Diese andere Datei gibt es nicht und sie ist auch nicht für den Zugriff erforderlich, wie der erfolgreiche Zugriff über die anderen Wege beweist.
Etwas ausführlicher hatte ich es im Artikel zu DBeaver geschrieben.
Excel
Excel öffnen, DBF Datei reinziehen, Daten ansehen. Fertig, so einfach kann es gehen.
Ich hatte mich allerdings durch die Bezeichnung Standarddatenbankdatei ablenken lassen, so dass ich zuerst die Wege über DBeaver und Java versucht hatte.
Java
Für den Zugriff mit Java habe ich die Bibliothek JavaDBF verwendet.
Die beiden Testklassen JavaDBFReaderTest und JavaDBFReaderWithFieldNamesTest waren schnell angepasst und eine weiter Klasse zum Auslesen aller Daten ReadItAll war dann auch problemlos möglich. Dabei ignoriere ich die Datentypen und lese einfach alles als Strings ein. Für den PoC reicht das.
DBF in PostgresDB speichern
Als Beispiel, wie ich mit den Daten weiterarbeiten kann, importiere ich sie in eine Postgres Datenbank.
Dazu lese ich zuerst die sample.dbf ein und erzeuge dann eine Tabelle sample mit allen Columns, die in sample.dbf vorhanden sind. Anschließend wird die Tabelle zeilenweise gefüllt.
Das meiste ist hardcodiert und die Spalten sind alles Text-Spalten, da ich die Datentypen aus der DBF Datei nicht auslese, aber für den PoC reicht das.
Bisher hatte ich auf meine Postgres Datenbank per PG-Admin zugegriffen.
Ein Kollege hat mir heute DBeaver als Datenbanktool empfohlen.
Installation
Die Installation der DBeaver Community Version war in meinem Fall einfach das ZIP-File herunterladen, und nach C:\Program Files\dbeaver entpacken.
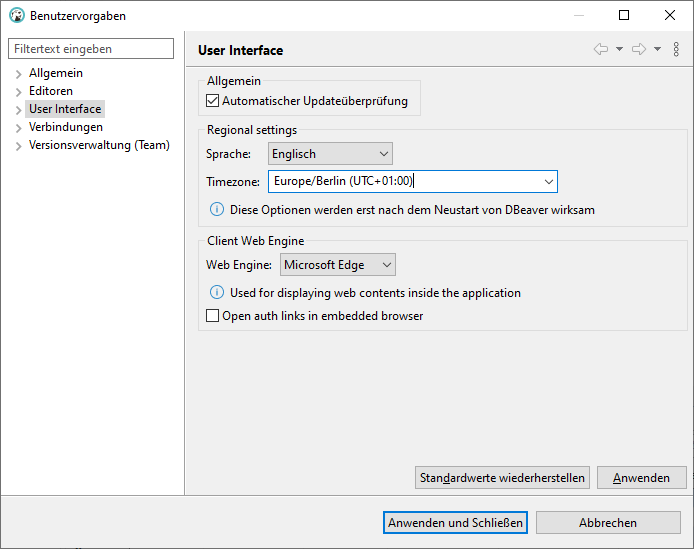
DBeaver erscheint in deutscher Lokalisation. Da aber die meisten Artikel über DBeaver auf Englisch sind, stelle ich auf Englisch um. Dazu auf Fenster -> Einstellungen gehen und im User Interface die Regional settings anpassen:
Im Unterpunkt User Interface -> Appearance stelle ich testweise das Theme auf Dark.
Meine Postgres Datenbank konnte ich mit den Verbindungsparametern anbinden, benötigte Treiber konnte DBeaver selbst nachladen.
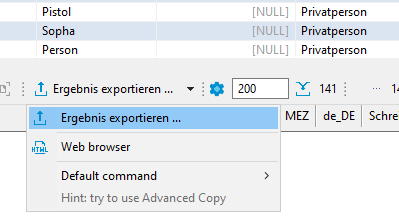
CSV Export
Für den CSV Export im Result-Tab auf "Ergebnis exportieren" klicken:
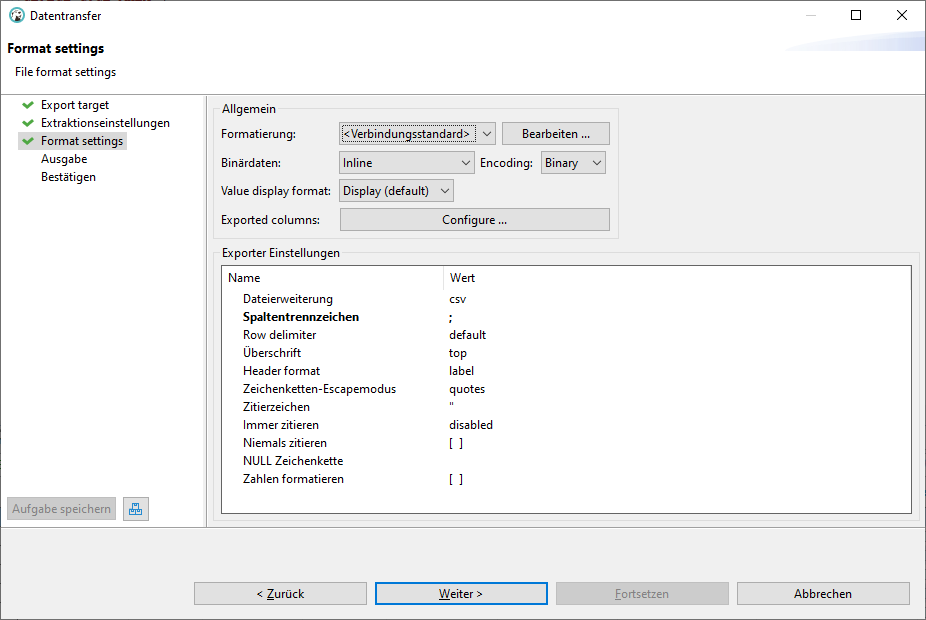
In den Format settings noch das Spaltentrennzeichen auf ";" für mein deutsches Excel ändern:
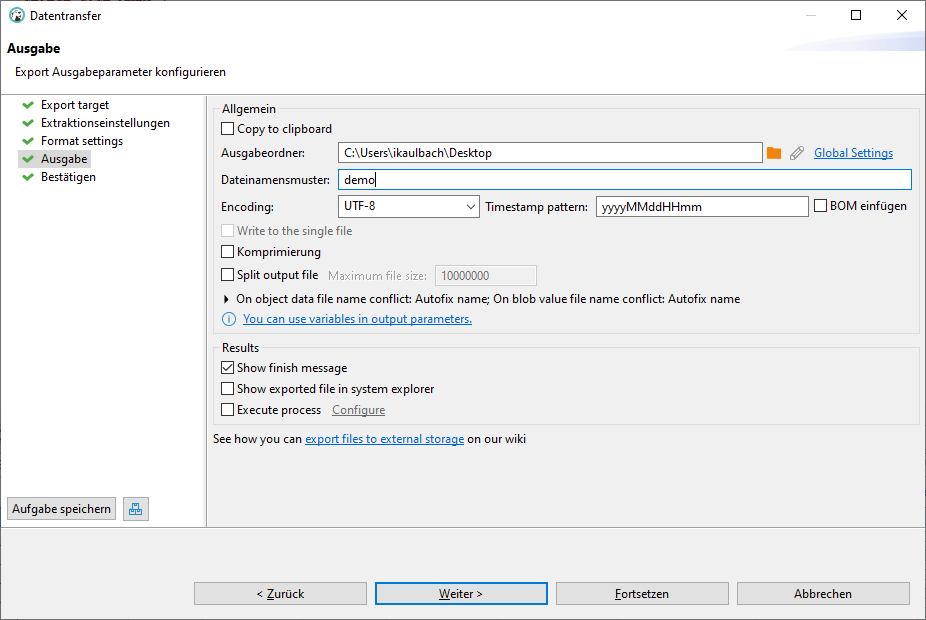
Im Ausgabetab den Ausgabeordner und Dateinamen, ohne Endung .csv, eingeben, Encoding auf UTF-8 belassen:
Trotz UTF-8 zeigt Excel die Umlaute nicht richtig an:
Die Ursache / Lösung konnte ich auf die Schnelle nicht finden. Zum Glück ist das grade nicht so wichtig, daher kann ich die Recherche vertragen.
dBase
Ich habe eine .dbf-Datei erhalten. Dabei handelt es sich anscheinend um einen dBase-Datenbank-Export. Diese Datei/Datenbank möchte ich mir mit DBeaver ansehen.
Dazu muss ich zuerst einen JDBC-Driver herunterladen. Nach kurzer Suche habe ich dieses Maven-Dependency gefunden, die ich in mein Maven Repository herunterlade:
download dans-dbf-lib-1.0.0-beta-10.jar (e.g. from sourceforge)
in Drivers location, Local folder (in Windows: C:\Users\user\AppData\Roaming\DBeaverData\drivers) create the \drivers\dbf directory. NB 'drivers' must be created under drivers, so ...\DBeaverData\drivers\drivers\...
put dans-dbf-lib-1.0.0-beta-10.jar in this folder
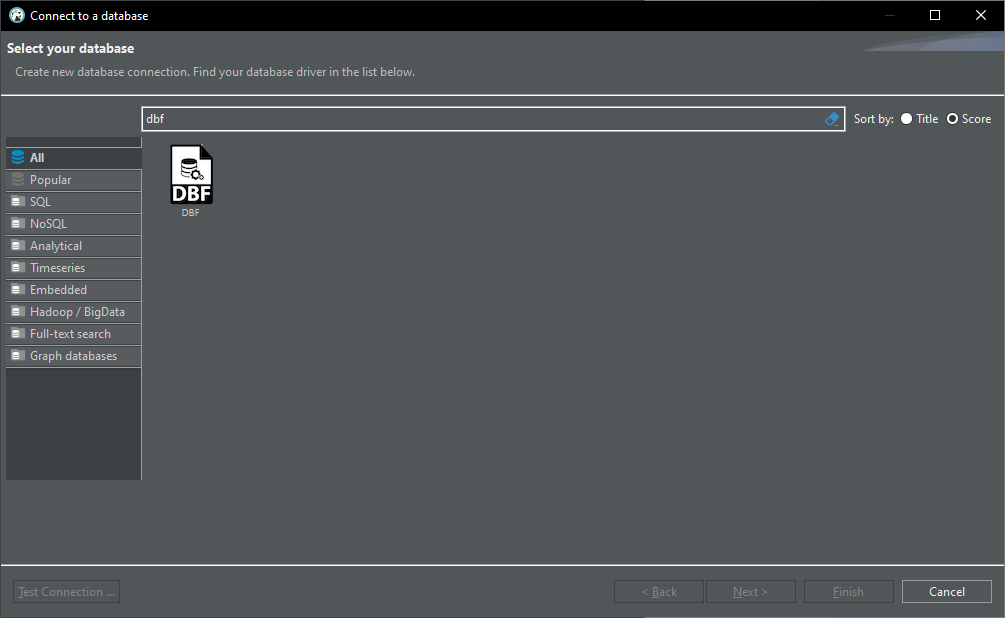
now you can create a new connection using the Embedded/DBF driver
Connection anlegen:
Im Database Navigator:
DBF Database auswählen:
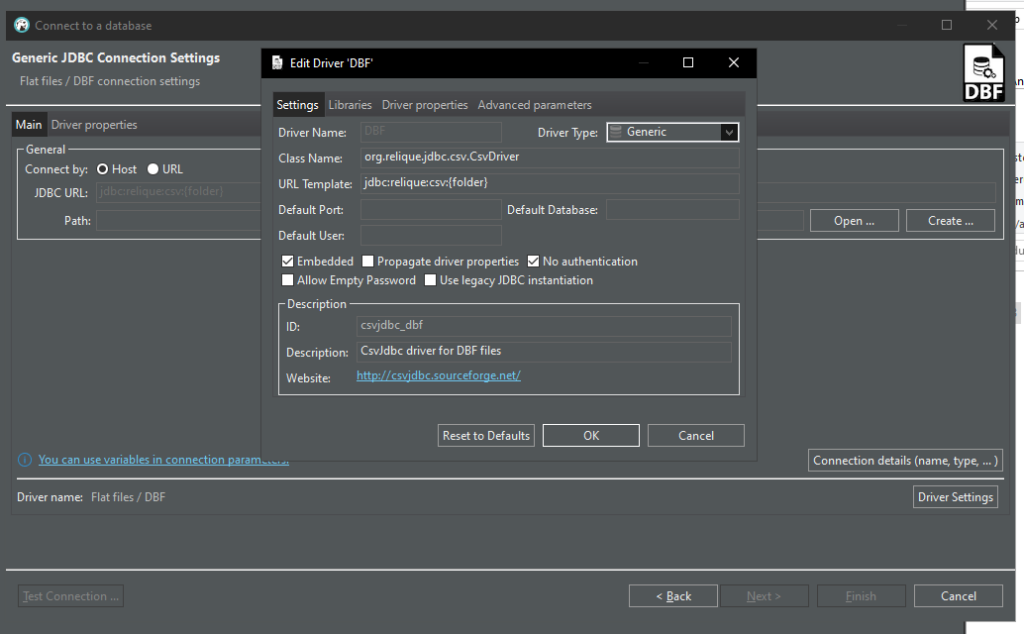
Wenn ich dann aber in die Treiber Details schaue, sieht es nicht so aus, als ob das DANS DBF Driver ist:
Andererseits erscheint das jar dann doch bei den Libraries, also sollte das doch richtig sein?
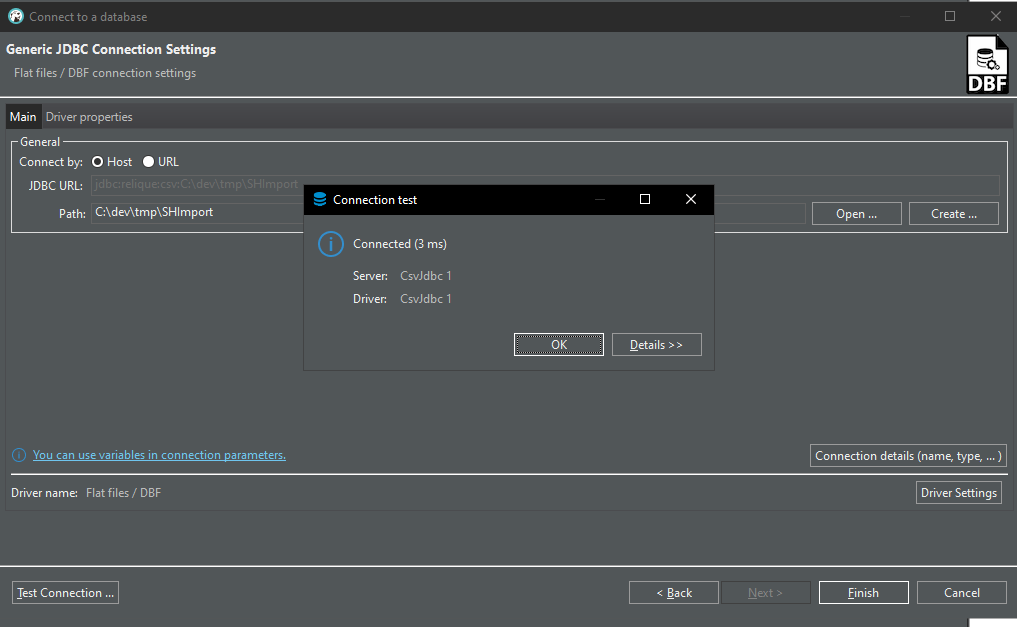
Ich gebe den Pfad zum Ordner mit der .dbf Datei an und rufe Test Connection auf, was sogar funktioniert:
Mit Finish beenden.
Im Database Navigator erscheint die ".dbf Datenbank" und ich kann die enthaltene Tabelle mit ihren Spalten erkennen. Wenn ich dann allerdings View Data auf der Tabelle aufrufe gibt es eine Fehlermeldung:
SQL Error: nl.knaw.dans.common.dbflib.CorruptedTableException: Could not find file 'C:\dev\tmp\SHImport\adress.dbt' (or multiple matches for the file)
Möglicherweise habe ich keinen ordentlichen Export bekommen?
Ich werde dem nachgehen und wenn es noch relevante Informationen zum DBeaver Import geben sollte werde ich diese hier anfügen.
Im vorletzten Post: PostgreSQL hatte ich beschrieben, wie ich zwei Bestandsdatenbanken analysiert und in eine PostgreSQL-DB in einem Docker Container gebracht habe, samt PGAdmin.
Jetzt möchte ich einen Schritt weiter gehen und das komplette Setup über ein Script starten können: DB, PGAdmin & SQL-Scripte. Dazu verwende ich Docker-Compose.
Ausgangslage
In PostgreSQL hatte ich bereits die zugrundeliegenden Docker-Images ermittelt: postgres:13.4-buster für die DB und dpage/pgadmin4 für PGAdmin. Inzwischen gibt es aber ein aktuelleres Image für die DB, das ich verwenden werde: postgres:13.5-bullseye
Für die SQL-Daten werde ich auf den Artikel PostgreSQL IDs zurückgreifen und daraus zwei Scripte machen, eines für das Schema der DB und eines mit den "Masterdaten" mit denen das Schema initial befüllt werden soll.
CREATE SEQUENCE object_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
CREATE TABLE person (
object_id integer NOT NULL DEFAULT nextval('object_id_seq'::regclass),
vorname varchar(255),
nachname varchar(255),
CONSTRAINT person_pkey PRIMARY KEY (object_id)
);
CREATE TABLE adresse (
object_id integer NOT NULL DEFAULT nextval('object_id_seq'::regclass),
strasse varchar(255),
ort varchar(255),
CONSTRAINT adresse_pkey PRIMARY KEY (object_id)
);
INSERT INTO person (vorname, nachname) VALUES ('Max', 'Mustermann');
INSERT INTO person (vorname, nachname) VALUES ('Peter', 'Person');
INSERT INTO person (vorname, nachname) VALUES ('Donald', 'Demo');
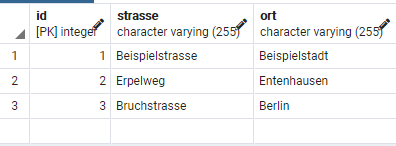
INSERT INTO adresse (strasse, ort) VALUES ('Beispielstrasse', 'Beispielstadt');
INSERT INTO adresse (strasse, ort) VALUES ('Erpelweg', 'Entenhausen');
INSERT INTO adresse (strasse, ort) VALUES ('Bruchstrasse', 'Berlin');
Auf der Seite von Docker Compose bringe ich in Erfahrung, dass die aktuelle Version von Docker Compose 3.9 ist und erstelle schon mal die Datei:
version: "3.9" # optional since v1.27.0
Ordernstrucktur:
Images starten
Bisher habe ich PostgreSQL und PGAdmin über folgende Kommandos gestartet:
docker run --name myapp-db -p 5432:5432 -e POSTGRES_PASSWORD=PASSWORD -d postgres:13.4-buster
Jetzt können beide Images mit einem einfachen Befehl gestartet werden:
\myapp> docker-compose up
Creating network "myapp_default" with the default driver
Creating myapp_myapp-db_1 ... done
Creating myapp_myapp-pgadmin_1 ... done
Attaching to myapp_myapp-db_1, myapp_myapp-pgadmin_1
PGAdmin im Browser starten: http://localhost:80 Login wie bisher mit admin@admin.com / admin
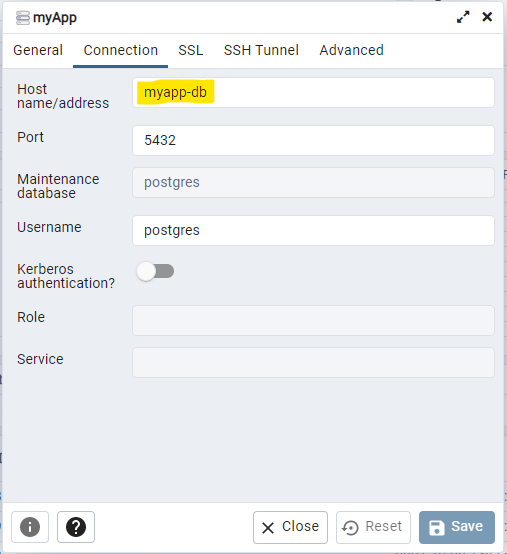
Im nächsten Schritt gibt es bereits eine entscheidende Änderung: Während bisher beide Container isoliert nebeneinander liefen und nur über den Host-Rechner kommunizieren konnten, wurde durch Docker-Compose automatisch beim Start ein Netzwerk ("myapp_default") angelegt, in dem beide Container laufen. Außerdem sind beide Container über ihren Servicenamen ("myapp-db" & "myapp-pgadmin") erreichbar.
Dadurch muss nicht mehr die IP des Host-Rechners ermittelt werden (die sich manchmal ändert), sondern es kann der Name genommen werden:
Datenbank erstellen
In der PostgreSQL Instanz muss jetzt eine Datenbank erzeugt werden, in der die Anwendungsdaten gespeichert werden.
Hierzu gehen wir in den DB Container. Allerdings ist der Name anders als bisher: Es wurde der Verzeichnisname als Präfix davor und eine 1 (für die 1. und in unserem Fall einzige Instanz) als Postfix dahinter gehangen und so lautet der Name : myapp_myapp-db_1
docker exec -it myapp_myapp-db_1 bash
Im Container erzeugen wir die DB:
su postgres
createdb myappdb
exit
So war es zumindest bisher, einfacher geht es mit Docker-Compose und dem Setzten der Environment-Variablen POSTGRES_DB wodurch die DB automatisch angelegt und verwendet wird. Sicherlich hätte ich das auch bisher im Docker Kommando so nehmen können, aber im letzten Post hatte ich es zum einen mit zwei DBs zu tun und zum anderen musste ich eh auf die Kommandozeile um die DBs einzuspielen.
Einfacher geht es über Docker-Compose und den Mechanismus, dass PostgreSQL automatisch die Dateien importiert, die im Verzeichnis /docker-entrypoint-initdb.d/ liegen. Und zwar in alphabetischer Reihenfolge.
Während der Entwicklung öfters mal die DB platt macht und komplett neu aufsetzt: Mit Docker ist das schnell gemacht. Mit Docker-Compose sind es jetzt nur noch zwei Befehle:
# stop and remove stopped containers
docker-compose down
# start containers
docker-compose up
Einen Nachteil gibt es allerdings: Die Einstellungen im PGAdmin gehen ebenfalls flöten und müssen neu eingegeben werden. Die Lösung: Der PGAdmin Container bekommt ein persistentes Volume, das ein docker-compose down übersteht. Und wenn es doch mal neu aufgesetzt werden muss, ist das einfach über das -v Flag umsetzbar: docker-compose down -v
An Schema und Stammdaten wird sich erstmal nichts ändern. Daher wäre es gut, wenn beim Neubau der Container die DB bereits mit Schema und Stammdaten gestartet wird und nicht diese erst aufbauen muss.
Das wird dadurch erreicht, dass ein Image gebaut wird, dass die PostgreSQL DB sowie Schema und Stammdaten enthält.
Im Verzeichnis database wird eine Datei Dockerfile angelegt. Dieses Dockerfile enthält die Informationen zum Bau des DB Images.
Sollte es erforderlich sein, das Image neu zu bauen, zB wenn ich das Schema verändert hat:
docker-compose up --build
# or
docker-compose build
UPDATE: Das war leider nix mit dem vorgefüllten Image
Das Dockerfile enthält zwar den Schritt die SQL Dateien in das Image zu kopieren. Es fehlt aber der Schritt, bei dem diese Dateien in die Datenbank hineinmigriert werden. Das geschieht wie zuvor auch erst beim Starten des Containers. Mein Ziel, einen Image zu haben, dass diese Daten bereits enthält, habe ich damit also leider nicht erreicht. Das Dockerfile enthält keine Informationen, die nicht zuvor auch schon im Docker Compose enthalten waren.
Da mich das herumkaspern mit diesem Problem heute den ganzen Tag gekostet und abgesehen vom Erkenntnisgewinn leider nichts gebracht hat, kehre ich zur Docker Compose Variante zurück, bei der die DB beim Starten des Containers gebaut wird. Für das Beispiel auf dieser Seite macht das praktisch gesehen keinen Unterschied, da die Scripte winzig sind. Für mein Projekt leider schon, da benötigt der Aufbau der DB ein paar Minuten. Für die Anwendungsentwicklung, bei der ich die DB alle paar Tage mal neu aufsetze, ist das durchaus OK. Für Tests, die mit einer frischen DB starten sollen, die am Ende weggeschmissen wird, ist das schon ein Problem.
Also Rückkehr zu Docker Compose, diesmal mit einem extra Volume für die DB. Das kann ich dann gezielt löschen.
# Create and start containers
docker-compose up
# Image neu bauen
docker-compose up --build
# or
docker-compose build
# Stop containers
docker-compose stop
# Start containers
docker-compose start
# Stop containers and remove them
docker-compose down
# Stop containers, remove them and remove volumes
docker-compose down -v
CREATE TABLE person (
vorname varchar(255),
nachname varchar(255)
);
Diese Personen sollen alle eine eindeutige ID bekommen und diese soll automatisch beim Einfügen generiert werden.
Sequenz
Dazu kann man eine Sequenz anlegen und aus dieser die ID befüllen:
CREATE SEQUENCE person_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
CREATE TABLE person (
id integer NOT NULL DEFAULT nextval('person_id_seq'::regclass),
vorname varchar(255),
nachname varchar(255),
CONSTRAINT person_pkey PRIMARY KEY (id)
);
Anschließend ein paar Personen hinzufügen:
INSERT INTO person (vorname, nachname) VALUES ('Max', 'Mustermann');
INSERT INTO person (vorname, nachname) VALUES ('Peter', 'Person');
INSERT INTO person (vorname, nachname) VALUES ('Donald', 'Demo');
Und anzeigen lassen:
SELECT * FROM person;
Identity
Da es etwas lästig ist, immer für jede Tabelle jeweils eine eigene Sequenz anlegen und mit der ID verknüpfen zu müssen, wurde die Frage an mich herangetragen, ob es da nicht soetwas wie autoincrement gäbe, wie man es von MySQL kennen würde.
Nach kurze Recherche fand sich, dass es soetwas natürlich auch für PostgreSQL gibt und zwar seit der Version 10 als "IDENTITY".
CREATE TABLE adresse (
id int GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
strasse varchar(255),
ort varchar(255)
);
Anschließend ein paar Adressen hinzufügen:
INSERT INTO adresse (strasse, ort) VALUES ('Beispielstrasse', 'Beispielstadt');
INSERT INTO adresse (strasse, ort) VALUES ('Erpelweg', 'Entenhausen');
INSERT INTO adresse (strasse, ort) VALUES ('Bruchstrasse', 'Berlin');
Und anzeigen lassen:
SELECT * FROM adresse;
Der Vorteil der Identity, was man so auf den ersten Blick sieht, ist also, dass man sich etwas stumpfe Tipparbeit spart und keine Sequenz anlegen, mit der ID verknüpfen und die ID als Primary Key definieren muss.
Eine Betrachtung der Unterschiede zwischen SEQUENCE und IDENTITY habe ich leider nicht finden können.
Vermutlich gibt es da keine großen technischen Unterschiede, die IDENTITY scheint mir eine anonyme SEQUENCE zu sein.
Object ID Sequenz
Die IDENTITY kann man nur für einen TABLE nutzen, die SEQUENCE könnte man für mehrere Tabellen nutzen und so eine datenbankweite eindeutige ID verwenden.
Beispielsweise eine eindeutige Object ID Sequenz anlegen und für die Tabellen Person und Adresse verwenden:
CREATE SEQUENCE object_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
CREATE TABLE person (
object_id integer NOT NULL DEFAULT nextval('object_id_seq'::regclass),
vorname varchar(255),
nachname varchar(255),
CONSTRAINT person_pkey PRIMARY KEY (object_id)
);
CREATE TABLE adresse (
object_id integer NOT NULL DEFAULT nextval('object_id_seq'::regclass),
strasse varchar(255),
ort varchar(255),
CONSTRAINT adresse_pkey PRIMARY KEY (object_id)
);
Anschließend ein paar Personen und Adressen hinzufügen:
INSERT INTO person (vorname, nachname) VALUES ('Max', 'Mustermann');
INSERT INTO person (vorname, nachname) VALUES ('Peter', 'Person');
INSERT INTO person (vorname, nachname) VALUES ('Donald', 'Demo');
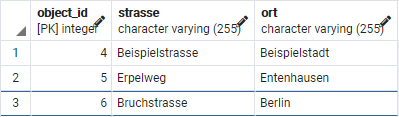
INSERT INTO adresse (strasse, ort) VALUES ('Beispielstrasse', 'Beispielstadt');
INSERT INTO adresse (strasse, ort) VALUES ('Erpelweg', 'Entenhausen');
INSERT INTO adresse (strasse, ort) VALUES ('Bruchstrasse', 'Berlin');
Und anzeigen lassen:
SELECT * FROM person;
SELECT * FROM adresse;
Wie man sehen kann, wurde die ID fortlaufend über beide Tabellen vergeben. Dadurch erhält man eine datenbankweit eindeutige, fortlaufende ID.
UUID
Und weil ich grade schon dabei bin: Seit Version 13 bringt PostgreSQL auch standartmäßig die Möglichkeit einer UUID mit.
Eine UUID ist ein Universally Unique Identifier. Manchmal, typischerweise in Zusammenhang mit Microsoft, wird auch der Ausdruck GUID Globally Unique Identifier verwendet.
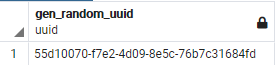
SELECT * FROM gen_random_uuid ();
UUIDs sind ebenfalls datenbankweit (und darüber hinaus) eindeutig. Allerdings sind die IDs nicht mehr fortlaufend.
UUIDs sind etwas langsamer als Sequenzen und verbrauchen etwas mehr Speicher.
Das Beispiel von vorhin:
CREATE TABLE person (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
vorname varchar(255),
nachname varchar(255)
);
CREATE TABLE adresse (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
strasse varchar(255),
ort varchar(255)
);
Anschließend ein paar Personen und Adressen hinzufügen:
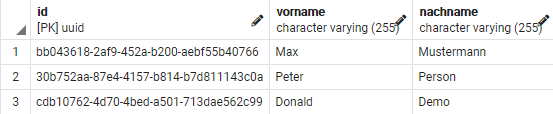
INSERT INTO person (vorname, nachname) VALUES ('Max', 'Mustermann');
INSERT INTO person (vorname, nachname) VALUES ('Peter', 'Person');
INSERT INTO person (vorname, nachname) VALUES ('Donald', 'Demo');
INSERT INTO adresse (strasse, ort) VALUES ('Beispielstrasse', 'Beispielstadt');
INSERT INTO adresse (strasse, ort) VALUES ('Erpelweg', 'Entenhausen');
INSERT INTO adresse (strasse, ort) VALUES ('Bruchstrasse', 'Berlin');
Für die Neu- und Weiterentwicklung einer Anwendung habe ich zur Analyse die Bestandsanwendung samt Datenbanken bekommen. Für die Analyse musste ich zunächst die Datenbanken zum laufen bekommen und uA mit einem DB-Client einsehen.
Ich habe zum einen eine Datei dump.backup bekommen. Zunächst musste ich herausfinden, um was für eine Datei es sich dabei handelt, dazu nutzte ich das Linux Tool file:
Es handelt sich also um einen Dump einer PostgreSQL Datenbank. Und im Dump konnte ich eine Versionsnummer 13.0 finden.
Die andere Datei mydb.sql.gz beinhaltet eine gezippte Version eines SQL Exports einer PostgreSQL DB Version 13.2 von einem Debian 13.2 Server.
Im Laufe der weiteren Analyse der DB Exporte stellte sich heraus, dass der dump.backup die PostGIS Erweiterung der PostgreSQL DB benötigt, welche mit installiert werden muss.
PostgreSQL Datenbank Docker Image
Ich werde beide Datenbanken in einer Docker Version installieren, dazu werde ich eine DB Instanz starten, in der beide DBs installiert werden.
Da es sich um die Versionsnummer 13.0 und 13.2 handelt, werde ich ein aktuelles Image von Version 13 verwenden, was zum Projektzeitpunkt Version 13.4 war.
Da zumindest eine der beiden DBs auf einem Debian System gehostet ist, werde ich ein Debian Image wählen.
Die Wahl des Images fällt also auf: postgres:13.4-buster
Datenbank installieren
Zuerst das Docker Image ziehen:
docker pull postgres:13.4-buster
Datenbank starten:
docker run --name myapp-db -p 5432:5432 -e POSTGRES_PASSWORD=PASSWORD -d postgres:13.4-buster
DB-Dateien in den laufenden Docker Container kopieren:
su postgres
createdb mydb_dump
pg_restore -d mydb_dump -v /tmp/dump.backup
exit
DB von SQL erstellen:
su postgres
cd /tmp
gunzip mydb.sql.gz
createdb mydb_sql
pg_restore -d mydb_sql -v /tmp/mydb.sql
exit
Die Datenbanken sind installiert und es kann mittels eines letzten exit der Container verlassen werden.
DB Client PGAdmin installieren
Um in die Datenbanken hinein sehen zu können wird ein Client Programm benötigt. Sicherlich es gibt da bereits etwas auf der CommandLine Ebene:
su postgres
psql mydb_sql
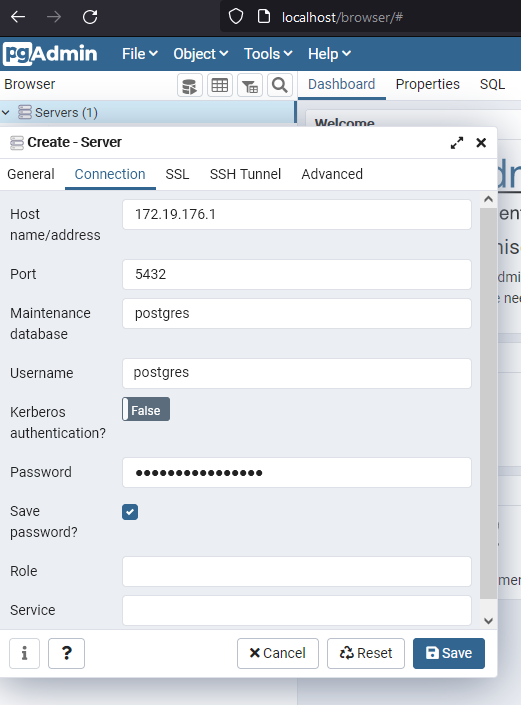
Übersichtlich oder komfortabel ist das aber nicht. Daher möchte ich ein Tool mit einer grafischen Oberfläche verwenden. Die Wahl fiel auf pgAdmin, welches sich leicht von einem Docker Image installieren und anschließend über den Browser bedienen lässt.
Für die Konfiguration für die Verbindung zur zuvor gestarteten PostgreSQL Datenbank benötige ich die IP meines Rechners, die ich mittels ipconfig herausfinden kann.