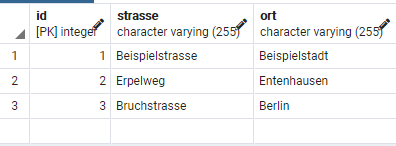
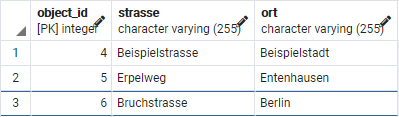
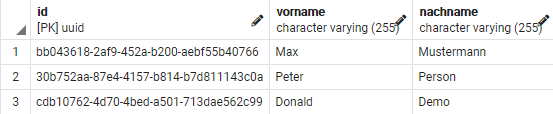
Zuletzt kochte die Log4J Lücke hoch, so dass man sich mit dem Thema Logging auseinander setzen musste.
Mich betraf der Bug nicht besonders, nach eingehender Analyse stellte sich heraus, dass keines meiner im Betrieb befindlichen Projekte Log4J verwendet. Ein Paar Projekte, die ich jahrelang betreuen durfte, waren betroffen, aber für die bin ich nicht mehr verantwortlich und war nur beratend tätig und habe meine Einschätzung und Handlungsempfehlung abgegeben.
Allerdings trägt das grade in der Entwicklung, aber noch nicht in Betrieb gegangene, Projekt Log4J in sich, so dass das Thema vor dem GoLive angegangen werden muss.
Java Logging
Einen sehr schönen, pragmatischen Einstieg in Java Util Logging habe ich auf Java Code Geeks gefunden.
Das einfachste Beispiel, um einen Ausgabe auf der Console zu erhalten:
package deringo.jpa;
import java.util.logging.Logger;
public class TestMain {
public static void main(String[] args) throws Exception {
Logger logger = Logger.getLogger(TestMain.class.getName());
logger.warning("Dies ist nur ein Test!");
}
}Ein paar Code Beispiele:
package deringo.jpa;
import java.util.logging.ConsoleHandler;
import java.util.logging.Handler;
import java.util.logging.Level;
import java.util.logging.Logger;
public class TestMain {
public static void main(String[] args) throws Exception {
Logger logger = Logger.getLogger(TestMain.class.getName());
logger.warning("Dies ist nur ein Test!");
// Warnung wird ausgegeben, Fine nicht
logger.fine("Eine fine Nachricht. 1");
logger.warning("Eine warnende Nachricht. 1");
// Das Level des Loggers auf ALL setzen
logger.setLevel(Level.ALL);
// Trotzdem: Warnung wird ausgegeben, Fine nicht
logger.fine("Eine fine Nachricht. 2");
logger.warning("Eine warnende Nachricht. 2");
// Einen Handler für den Logger definieren, der Handler Level wird auf ALL gesetzt
Handler consoleHandler = new ConsoleHandler();
consoleHandler.setLevel(Level.ALL);
logger.addHandler(consoleHandler);
// Warnung wird ausgegeben, Fine wird ausgegeben
// ABER: Warnung wird doppelt ausgegeben
logger.fine("Eine fine Nachricht. 3");
logger.warning("Eine warnende Nachricht. 3");
}
}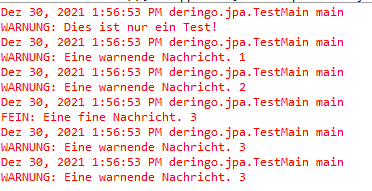
Überraschend ist erstmal, dass die dritte Ausgabe, zumindest für die Warnung, doppelt erscheint.
Die Erklärung ist, dass es noch einen Root Logger gibt, welcher der Parent des TestMain Loggers ist.
Standardmäßig gibt ein Logger seine Einträge an den Parent Logger weiter. Bzw. an die Handler des Parent Loggers.
Der Root Logger hat die ersten Logs ausgegeben, als der TestMain Logger noch gar keinen Handler hatte, der die Log Einträge verarbeiten konnte.
Wird die Weitergabe an den Parent Handler deaktiviert, wird nicht mehr doppelt geloggt:
package deringo.jpa;
import java.util.logging.ConsoleHandler;
import java.util.logging.Handler;
import java.util.logging.Level;
import java.util.logging.Logger;
public class TestMain {
public static void main(String[] args) throws Exception {
Logger logger = Logger.getLogger(TestMain.class.getName());
// Warnung wird ausgegeben, Fine nicht
logger.fine("Eine fine Nachricht. 1");
logger.warning("Eine warnende Nachricht. 1");
// Nicht an Parent Handler weiter reichen
logger.setUseParentHandlers(false);
// Warnung wird NICHT mehr ausgegeben, Fine ebenfalls nicht
logger.fine("Eine fine Nachricht. 2");
logger.warning("Eine warnende Nachricht. 2");
// Eigenen Handler definieren
Handler consoleHandler = new ConsoleHandler();
consoleHandler.setLevel(Level.ALL);
logger.addHandler(consoleHandler);
// Warnung wird ausgegeben, Fine wird NICHT ausgegeben
// Warnung wird NICHT doppelt ausgegeben
logger.fine("Eine fine Nachricht. 3");
logger.warning("Eine warnende Nachricht. 3");
// Das Level des Loggers auf ALL setzen
logger.setLevel(Level.ALL);
// Warnung wird ausgegeben, Fine wird ausgegeben
// Warnung wird NICHT doppelt ausgegeben
logger.fine("Eine fine Nachricht. 4");
logger.warning("Eine warnende Nachricht. 4");
}
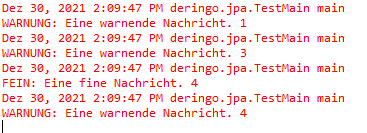
}
Java Logging - Konfiguration per Datei
Möchte man die Konfiguration des Java Util Loggers nicht per Code, wie oben, vornehmen, sondern per Datei findet sich ein guter Einstieg auf Wikibooks.
Davon abgeleitet meine Konfigurationsdatei logging.properties, die ich in src/main/resources abgelegt habe:
# Der ConsoleHandler gibt die Nachrichten auf std.err aus #handlers= java.util.logging.ConsoleHandler # Alternativ können weitere Handler hinzugenommen werden. Hier z.B. der Filehandler handlers= java.util.logging.FileHandler, java.util.logging.ConsoleHandler # Festlegen des Standard Loglevels .level= INFO ############################################################ # Handler specific properties. # Describes specific configuration info for Handlers. ############################################################ # Die Nachrichten in eine Datei im Benutzerverzeichnis schreiben java.util.logging.FileHandler.pattern = d:/java%u.log java.util.logging.FileHandler.limit = 50000 java.util.logging.FileHandler.count = 1 java.util.logging.FileHandler.formatter = java.util.logging.XMLFormatter java.util.logging.FileHandler.level = ALL # Zusätzlich zu den normalen Logleveln kann für jeden Handler noch ein eigener Filter # vergeben werden. Das ist nützlich wenn beispielsweise alle Nachrichten auf der Konsole ausgeben werden sollen # aber nur ab INFO in das Logfile geschrieben werden soll. java.util.logging.ConsoleHandler.level = ALL java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter ############################################################ # Extraeinstellungen für einzelne Logger ############################################################ # Für einzelne Logger kann ein eigenes Loglevel festgelegt werden. deringo.jpa.TestMain.level = FINEST
Leider funktionierte es nicht.
Es wird nach wie vor die originale logging.properties von Java genommen, die im Java Installationsverzeichnis $JAVA_HOME/jre unterhalb des lib Verzeichnises liegt, bzw. ab Java 9 in $JAVA_HOME/conf. Vgl. Mkyong
Falls nicht die Original-logging.properties-Datei benutzt werden soll, kann über die System-Property java.util.logging.config.file die stattdessen zu verwendende Datei angegeben werden.
Wie das praktisch geht, kann bei Mkyong nachgesehen werden.
Ich habe folgenden Code verwendet:
package deringo.jpa;
import java.util.logging.Logger;
public class TestMain {
public static void main(String[] args) throws Exception {
String path = TestMain.class.getClassLoader().getResource("logging.properties").getFile();
System.setProperty("java.util.logging.config.file", path);
Logger logger = Logger.getLogger(TestMain.class.getName());
// Warnung wird ausgegeben, Fine wird ausgegeben
// Beides auf der Console und in der Datei D:/java0.log
logger.fine("Eine fine Nachricht. 1");
logger.warning("Eine warnende Nachricht. 1");
}
}Es wird in der Console und der definierten Datei geloggt.
Warum die logging.properties des Projektes nicht standartmäßig anstelle der Java logging.properties gezogen wird, kann ich mir nicht erklären.
SLF4J
SLF4J ist kein Logging Framework, sondern eine Fassade vor der eigentlichen Implementierung. Man kann also im Code mit SLF4J loggen und SLF4J leitet das dann an das gewählte Framework, zB Java Util Logging oder Log4J weiter. So kann man das Logging Framework austauschen ohne den Code anfassen zu müssen.
Ob das jemals jemand vor dem Log4J Bug gemacht hat lasse ich mal dahingestellt, mir gefällt aber das eingebaute Templating, bzw. Parameterisierung, von SLF4J:
Object entry = new SomeObject();
logger.debug("The entry is {}.", entry);Das SLF4J Manual und das SLF4J Configuration File Example waren mir gute Informationsquellen.
Maven Dependency:
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-api -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.32</version>
</dependency>Erster Beispielcode:
package deringo.jpa.repository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SLF4JTest {
public static void main(String[] args) {
Logger logger = LoggerFactory.getLogger(SLF4JTest.class);
logger.info("Hallo Welt!");
}
}
Folgende Grafik aus dem SLF4J Manual zeigt, dass nach /dev/null geloggt wurde:
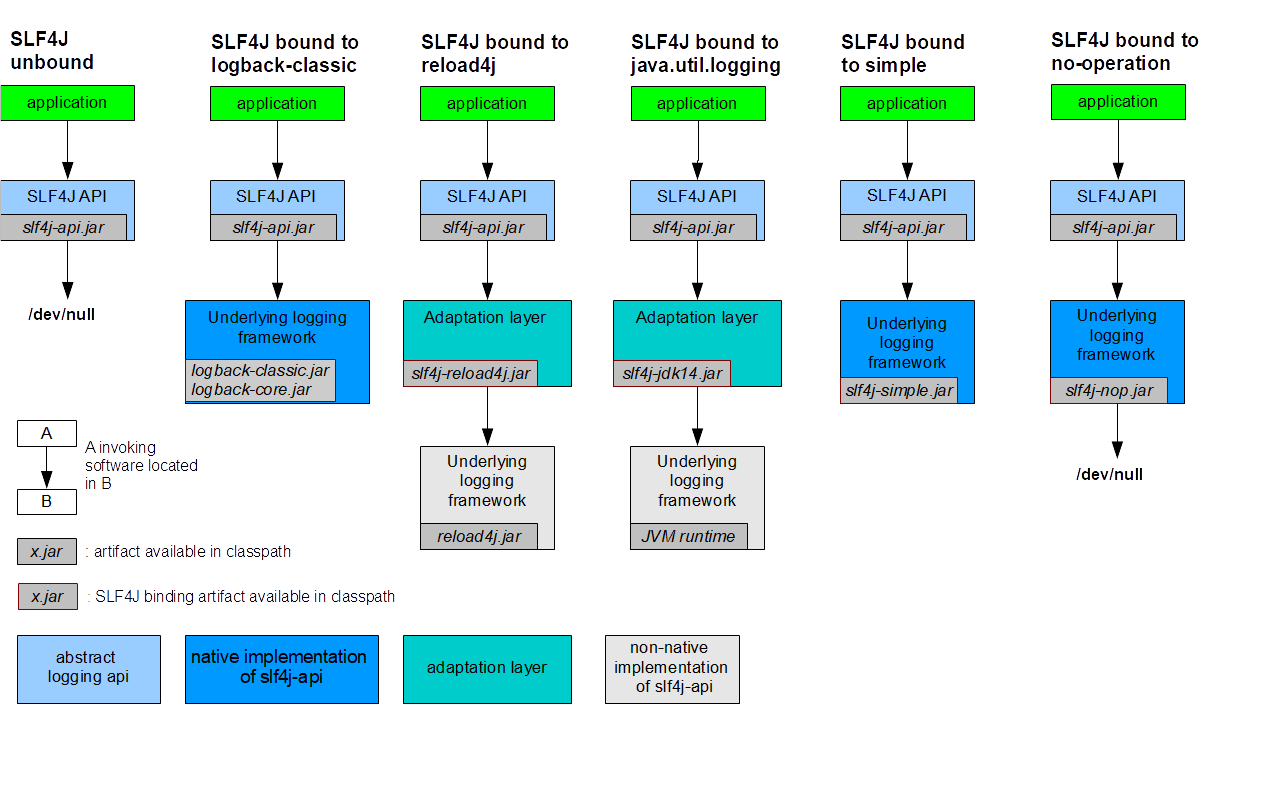
Es wird also eine Logging Framework Implementierung benötigt.
Ich entscheide mich für das Java Util Logging Framework, denn dieses ist in Java bereits enthalten und ich muss keine weitere Bibliothek, wie zB Log4J, in mein Projekt einbinden.
Es kommt also eine weitere Maven Abhängigkeit hinzu:
<properties>
<org.slf4j.version>1.7.32</org.slf4j.version>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-api -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${org.slf4j.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-jdk14 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-jdk14</artifactId>
<version>${org.slf4j.version}</version>
</dependency>
</dependencies>Der selbe Beispielcode von oben:
package deringo.jpa.repository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SLF4JTest {
public static void main(String[] args) {
Logger logger = LoggerFactory.getLogger(SLF4JTest.class);
logger.info("Hallo Welt!");
}
}Führt jetzt zu folgender Ausgabe:

Äquivalent zu dem Code Beispiel zu Java Util Logging - Konfiguration per Datei weiter oben, führt folgender Code zusätzlich zu einem Logging in einer Datei:
package deringo.jpa.repository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SLF4JTest {
public static void main(String[] args) {
String path = SLF4JTest.class.getClassLoader().getResource("logging.properties").getFile();
System.setProperty("java.util.logging.config.file", path);
Logger logger = LoggerFactory.getLogger(SLF4JTest.class);
logger.info("Hallo Welt!");
}
}
SLF4J & Log4J
Maven:
<properties>
<org.slf4j.version>1.7.32</org.slf4j.version>
<log4j.version>2.17.1</log4j.version>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-api -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${org.slf4j.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-log4j12 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${org.slf4j.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.logging.log4j/log4j-core -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
</dependency>
</dependencies>Selber Beispielcode wie oben:
package deringo.jpa.repository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SLF4JTest {
public static void main(String[] args) {
Logger logger = LoggerFactory.getLogger(SLF4JTest.class);
logger.info("Hallo Welt!");
}
}Ausgabe:

Zur Initialisierung bzw. Konfiguration von Log4J wird in src/main/resources eine Datei log4j.properties angelegt:
log4j.debug=false log4j.rootLogger=INFO, CONSOLE log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender log4j.appender.CONSOLE.Encoding=UTF-8 log4j.appender.CONSOLE.layout = org.apache.log4j.PatternLayout log4j.appender.CONSOLE.layout.ConversionPattern = %d [%t] %-5p %c- %m%n # Configure which loggers log to which appenders log4j.logger.deringo.jpa=DEBUG
Der Java Code bleibt unverändert, die Ausgabe sieht jetzt aber so aus: