Was man mal alles so gemacht hat...
Ein Vortrag von meinen Kommilitonen und mir ist noch im Netz zu finden: prak_ges.ppt (fh-koeln.de)
Was man mal alles so gemacht hat...
Ein Vortrag von meinen Kommilitonen und mir ist noch im Netz zu finden: prak_ges.ppt (fh-koeln.de)
Ich wollte mal Authentifizierung mit Spring Boot und GitHub-Login antesten. Als inspiration dient dieser Guide.
Die Sourcen lege ich in ein GitHub-Repository.
Spring Initializr verwenden.
Als Dependencies Spring Web und OAuth2 Client hinzufügen.
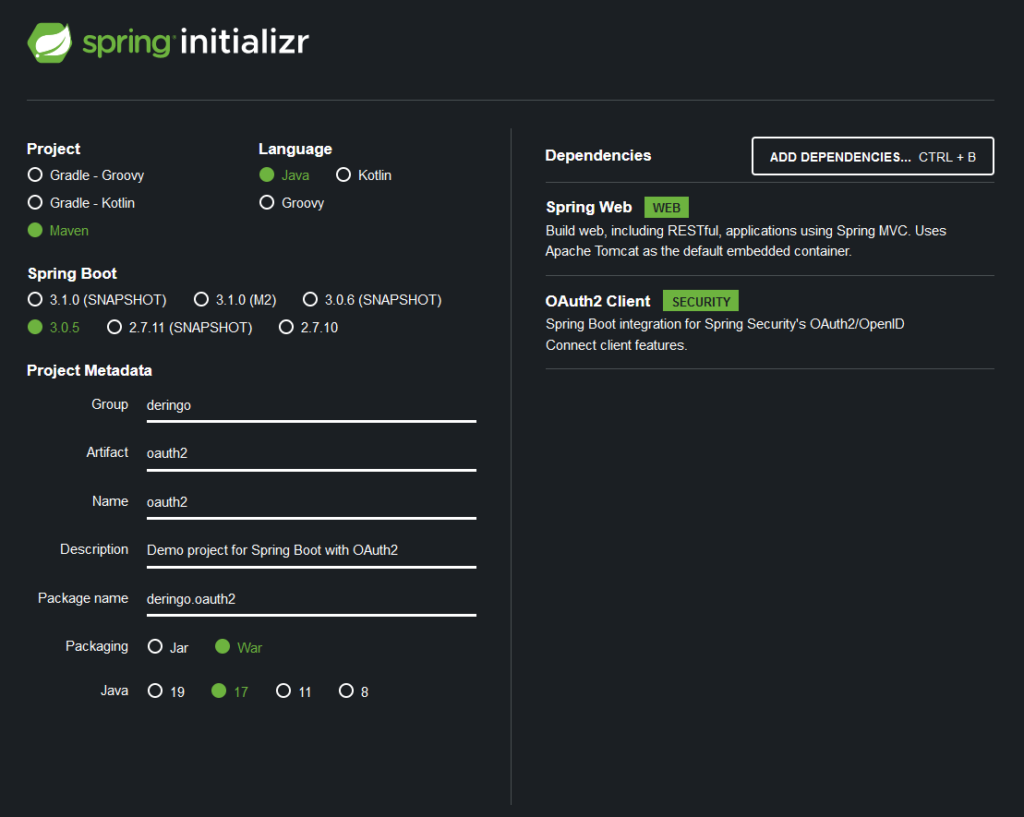
Zip-File herunterladen und in das Projekt entpacken. Warten bis Maven alle Dependencies heruntergeladen hat und anschließend Oauth2Application starten.
Unter http://localhost:8080 wird eine Login-Seite angezeigt:
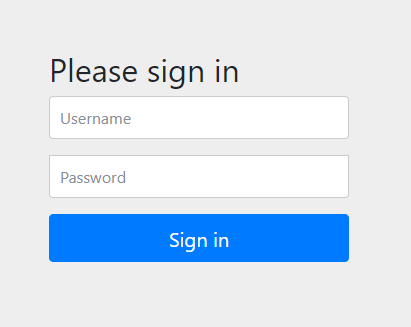
Hier halte ich mich an den Guide. Die WebJars kannte ich bereits, aber noch nicht deren Locator. Den muss ich mal in meinem JSF Projekt ausprobieren.
In your new project, create index.html in the src/main/resources/static folder. You should add some stylesheets and JavaScript links so the result looks like this:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8"/>
<meta http-equiv="X-UA-Compatible" content="IE=edge"/>
<title>Demo</title>
<meta name="description" content=""/>
<meta name="viewport" content="width=device-width"/>
<base href="/"/>
<link rel="stylesheet" type="text/css" href="/webjars/bootstrap/css/bootstrap.min.css"/>
<script type="text/javascript" src="/webjars/jquery/jquery.min.js"></script>
<script type="text/javascript" src="/webjars/bootstrap/js/bootstrap.min.js"></script>
</head>
<body>
<h1>Demo</h1>
<div class="container"></div>
</body>
</html>None of this is necessary to demonstrate the OAuth 2.0 login features, but it’ll be nice to have a pleasant UI in the end, so you might as well start with some basic stuff in the home page.
If you start the app and load the home page, you’ll notice that the stylesheets have not been loaded. So, you need to add those as well by adding jQuery and Twitter Bootstrap:
<dependency> <groupId>org.webjars</groupId> <artifactId>jquery</artifactId> <version>3.4.1</version> </dependency> <dependency> <groupId>org.webjars</groupId> <artifactId>bootstrap</artifactId> <version>4.3.1</version> </dependency> <dependency> <groupId>org.webjars</groupId> <artifactId>webjars-locator-core</artifactId> </dependency>
The final dependency is the webjars "locator" which is provided as a library by the webjars site. Spring can use the locator to locate static assets in webjars without needing to know the exact versions (hence the versionless /webjars/** links in the index.html). The webjar locator is activated by default in a Spring Boot app, as long as you don’t switch off the MVC autoconfiguration.
With those changes in place, you should have a nice looking home page for your app.
Oauth2Application starten.
Mir wird wieder die Login-Seite angezeigt.
Ich nehme die spring-boot-starter-oauth2-client Dependency aus der pom.xml heraus, starte Oauth2Application neu und sehe eine leere Seite.
Mir ist nicht ganz klar, woran das liegt, also mache ich erstmal weiter mit dem Guide, in der Hoffnung dass es am Ende laufen wird.
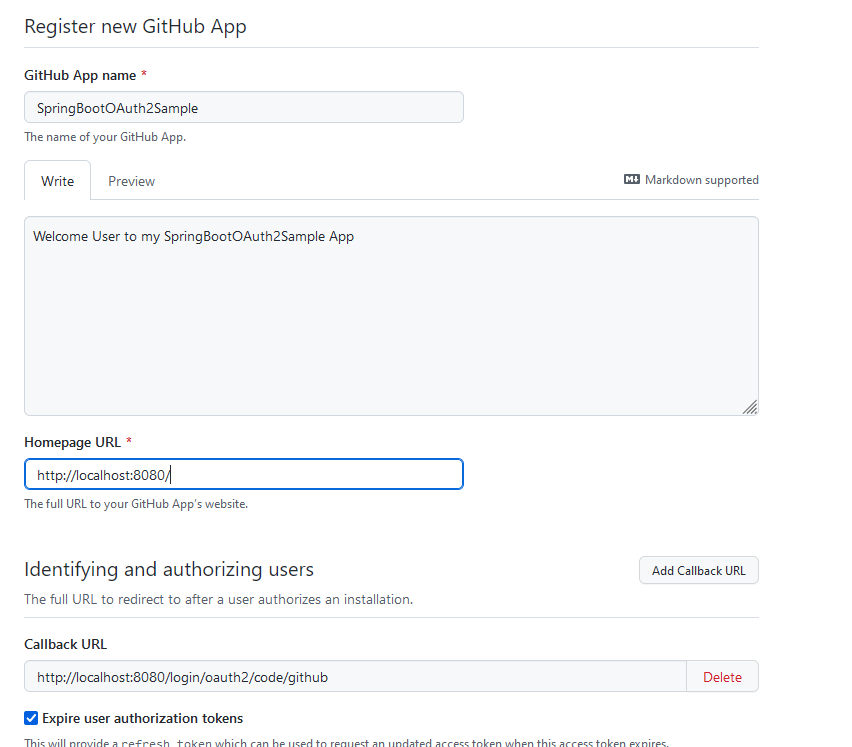
Webhook: Active Flag deaktivieren

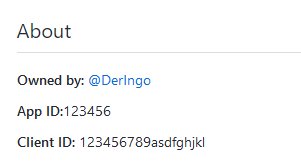

MÖÖÖÖÖÖP FALSCH
Ich habe oben eine GitHub App angelegt und keine OAuth App. Also nochmal von vorn:
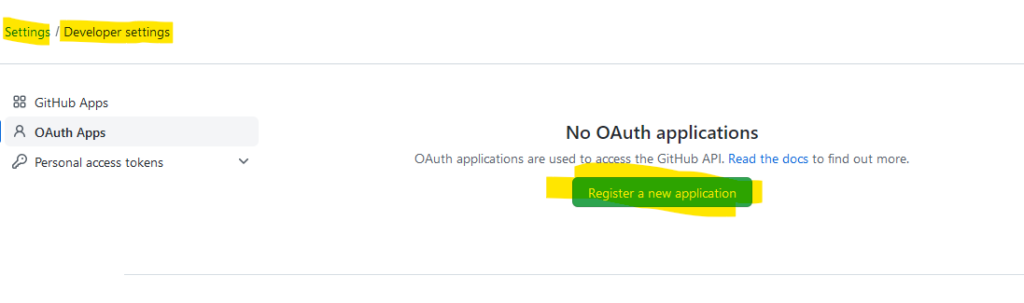
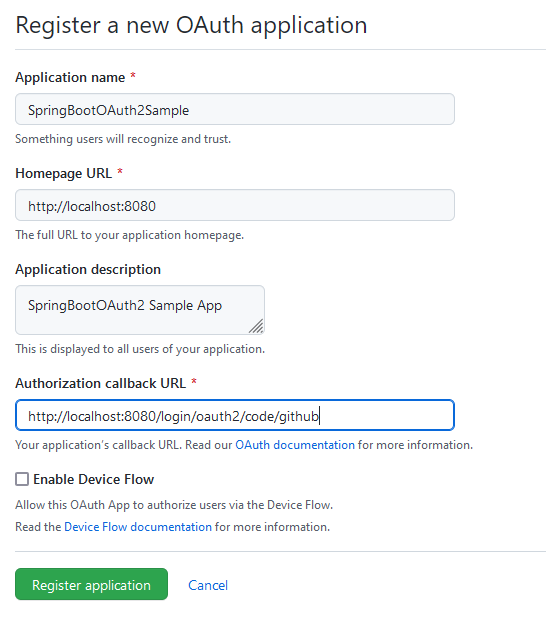
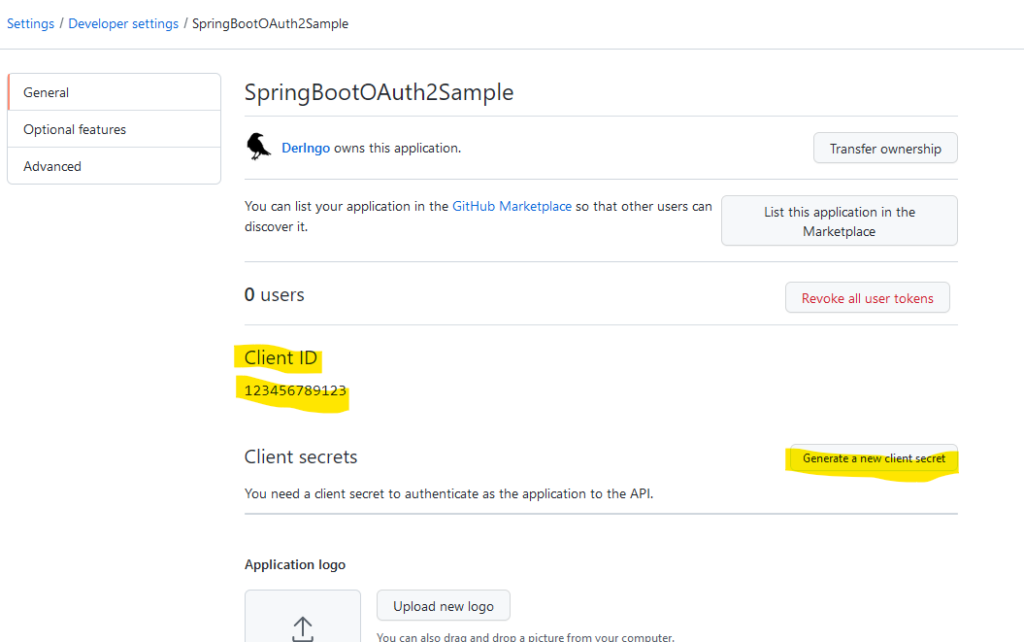
In src/resources application.yml anlegen:
spring:
security:
oauth2:
client:
registration:
github:
clientId: github-client-id
clientSecret: github-client-secrethttp://localhost:8080 aufrufen.
In einem anderen Tab des Browsers war ich bereits in GitHub eingeloggt:
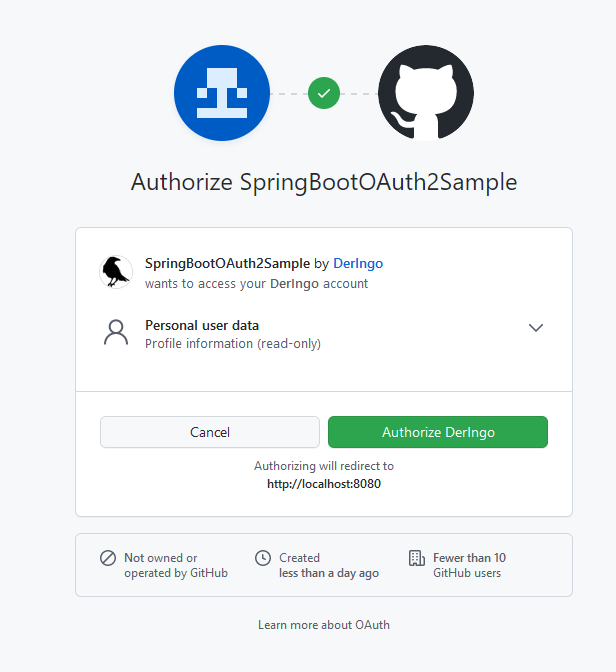
Wenn ich den Seitenaufruf in einem neuen privaten Browserfenster tätige, sieht die Anmeldung so aus:
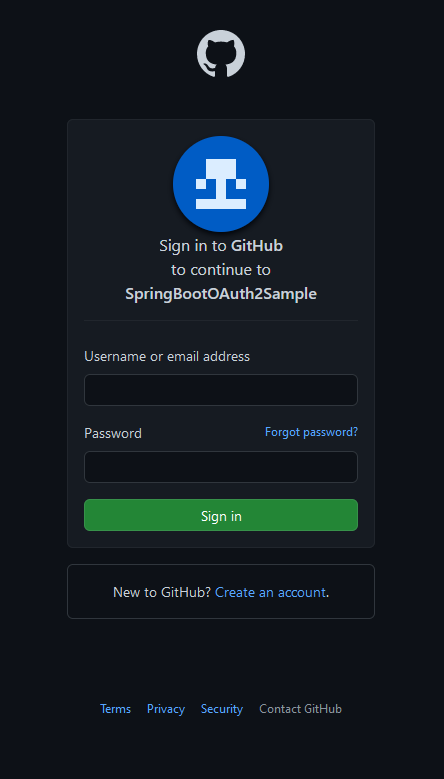
In beiden Fällen wird anschließend eine leere Seite angezeigt:
Auch die index.html bleibt leer:
Also irgendwas ist da noch nicht richtig.
Anscheinend hatte ich die index.html nicht richtig gespeichert, die Datei war noch leer. Also den Code hinzugefügt und gespeichert.
Anschließend funktioniert es auch:
Sehr schön, da kann der Zukunftsingo sich ja freuen, hier weiter herumzuexperimentieren, sobald wieder etwas Zeit ist.
Habe gestern gehört, dass es auf GitHub einen Dienst gibt, der die Aktualität der verwendeten Bibliotheken überwacht und über neuere Versionen informiert.
Der Dienst heißt Dependabot
Auf GitHub gibt es einen Blog Eintrag dazu und GitHub-Dokumentation gibt es auch.
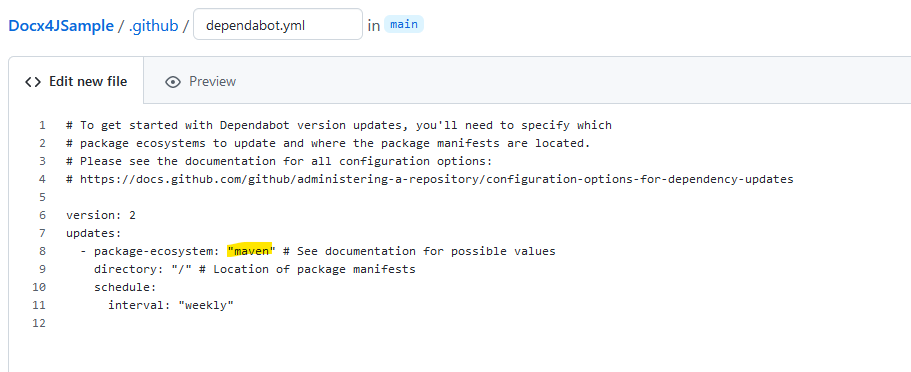
Im Projekt wird Maven verwendet und daher lautet das package-ecosystem laut Dokumentation überraschenderweise: "maven":
Dass es funktioniert hat, konnte ich direkt daran sehen, dass ein Pull request angezeigt wird:
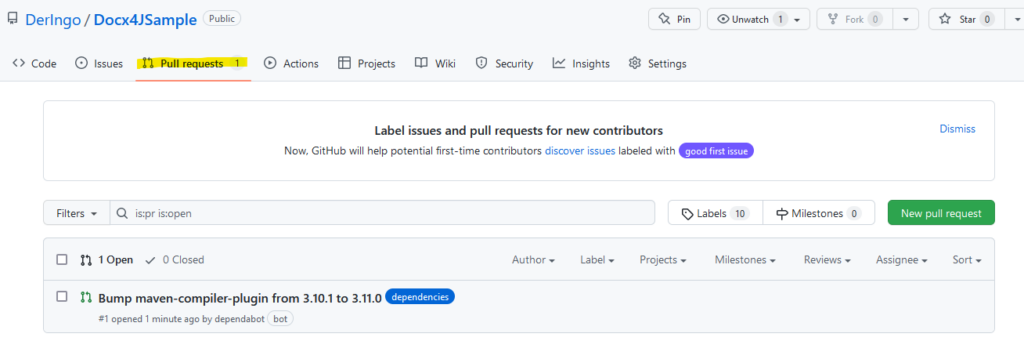
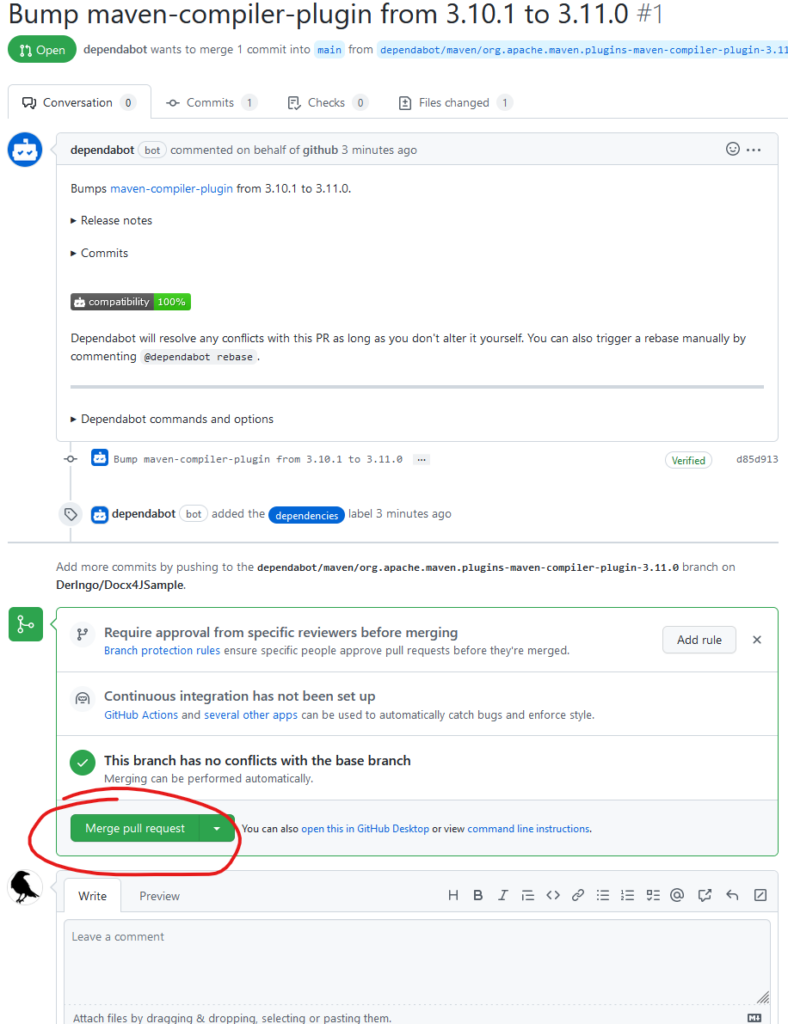
Merge & confirm pull request. Und schon ist die pom.xml wieder up to date. Das war ja einfach.
Da die version updates so gut geklappt haben, aktiviere ich die security updates, für die auch die alerts aktiviert werden müssen:
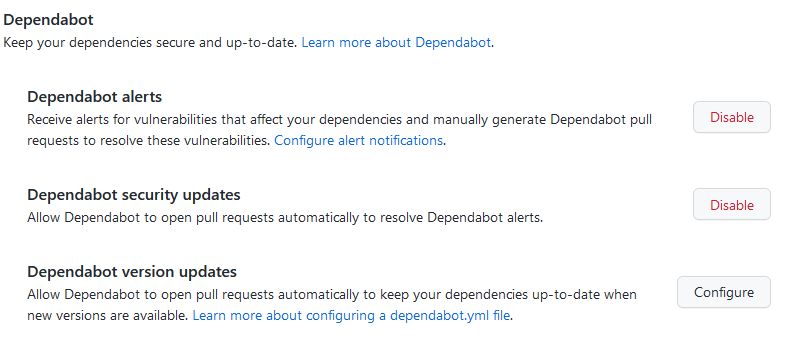
Das Aktivieren hat keine Auswirkungen gezeigt, vermutlich ist mein Sample Projekt schon sicher.
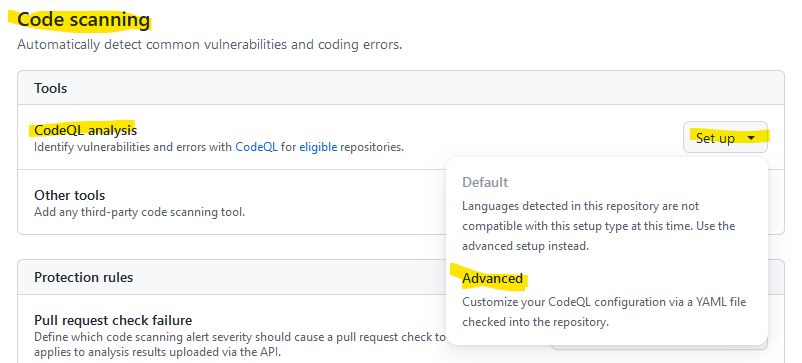
Als Sprache wurde Java automatisch erkannt, daher kann die Konfigurationsdatei unverändert gespeichert werden.
Unter Actions kann ich sehen, dass der Code scanning workflow gelaufen ist und es Probleme gibt:
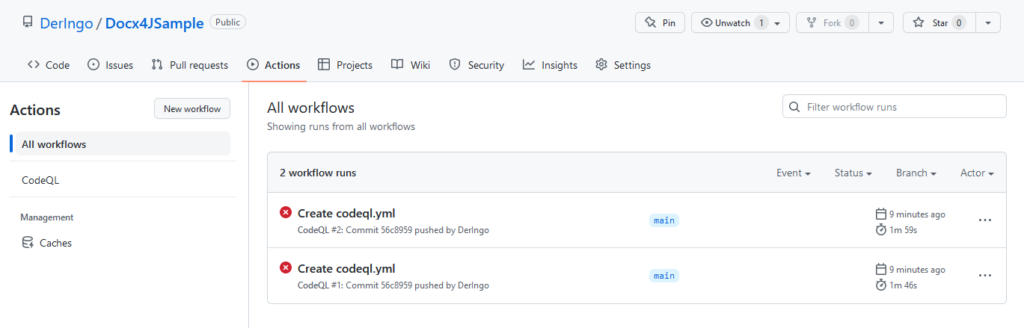
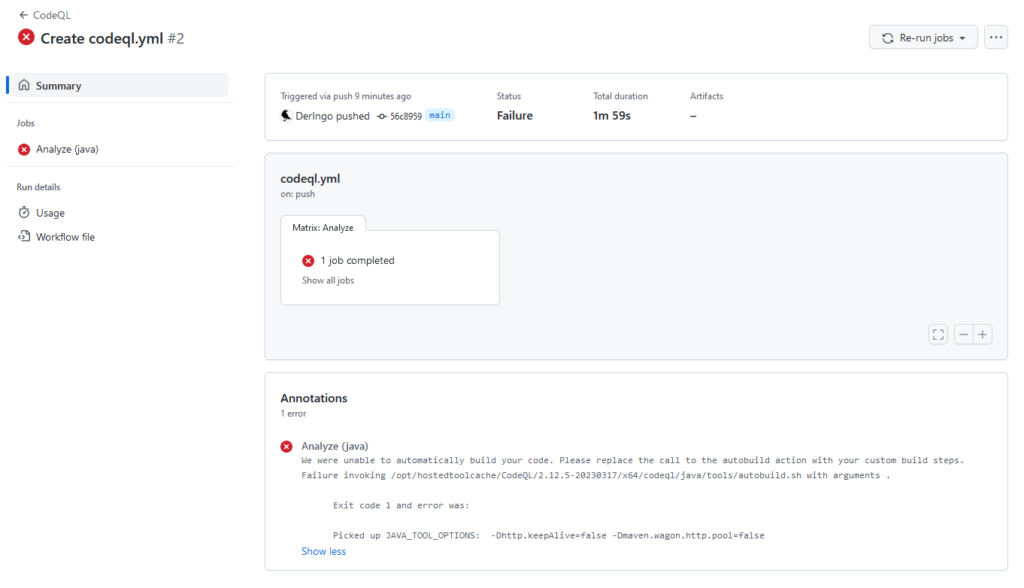
Logfiles suchen und herunterladen, da sie zu lang für den Webviewer sind.
Fatal error compiling: error: invalid target release: 17
Hier findet sich ein Hinweis: "Have you set up a Java 17 environment on Actions using https://github.com/actions/setup-java?"
Die Dokumentation hilft weiter und der Workflow wird um einen Schritt erweitert: Set up JDK 17
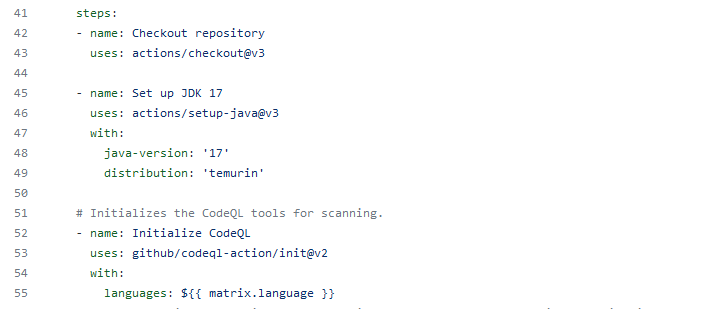
- name: Set up JDK 17
uses: actions/setup-java@v3
with:
java-version: '17'
distribution: 'temurin'
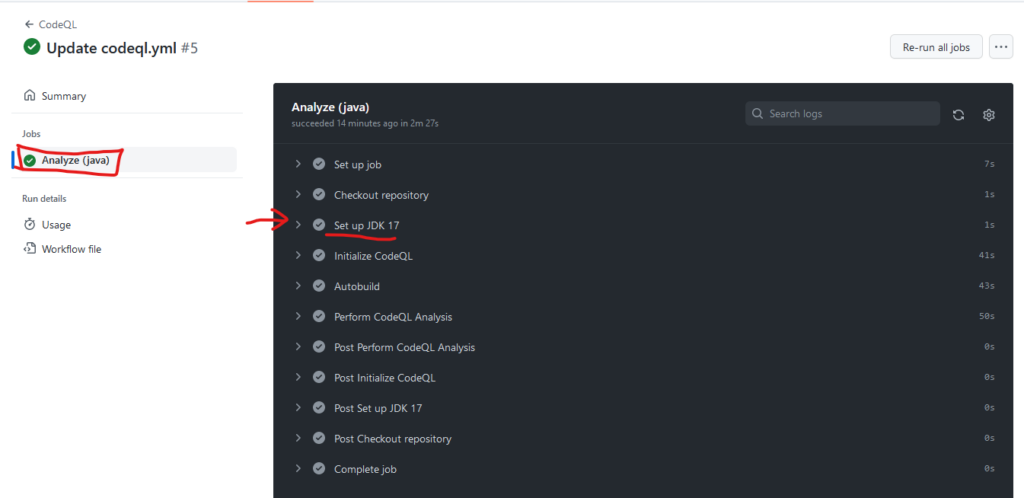
Anschließend läuft der Job durch:
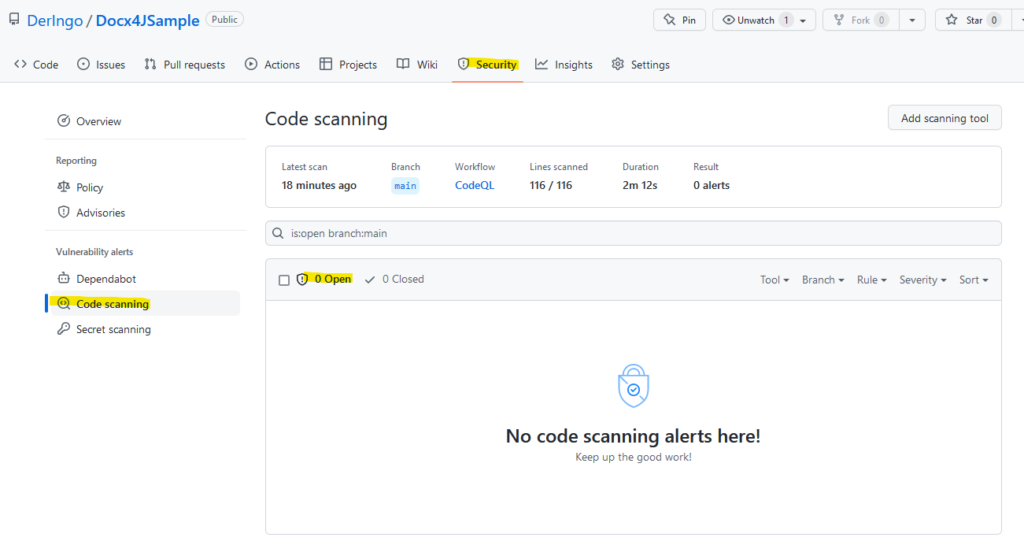
Der Erfolg des Scans findet sich im Security Tab unter Code scanning:
Receive alerts on GitHub for detected secrets, keys, or other tokens.
https://github.com/DerIngo/Docx4JSample/settings/security_analysis
Klingt interessant. Mein Projekt hat keine Secrets, also füge ich erstmal eine Properties-Datei mit einem geheimen Passwort hinzu:
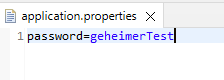
Anschließend wird das Secret scanning aktiviert:

Es wird kein Secret Alert ausgelöst:
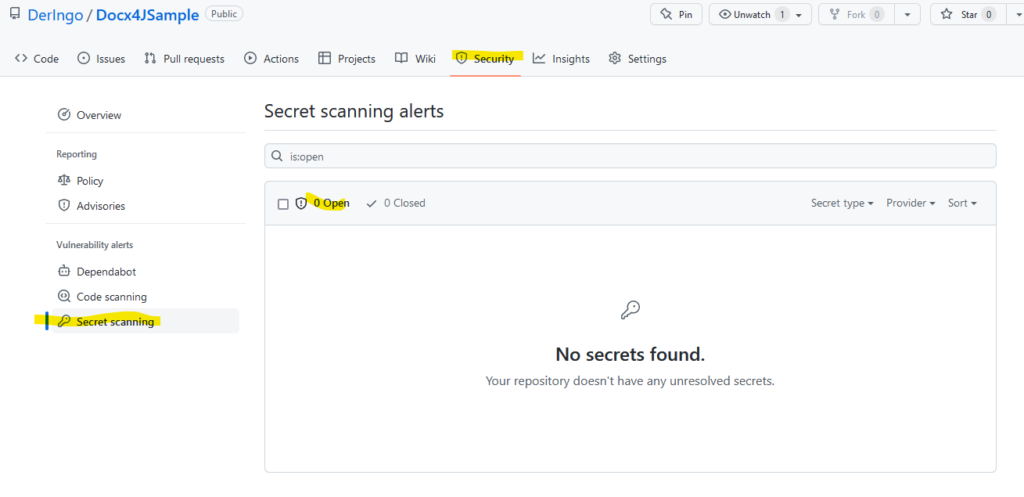
Anschließend füge ich dem password auch noch ein username hinzu, aber das Ergebnis bleibt das Gleiche.
In der Dokumentation finden sich Supported secrets, ich probiere eines davon ("adafruit_io_key") als Property-Eintrag aus. aber das Ergebnis bleibt das Gleiche.
Ich suche nach "adafruit_io_key" und erweitere die Properties-Datei ein weiteres mal:
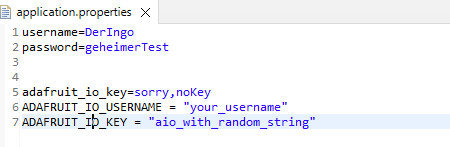
Aber das Ergebnis bleibt das Gleiche.
Ich probiere es mit einer weiteren Secret Datei:
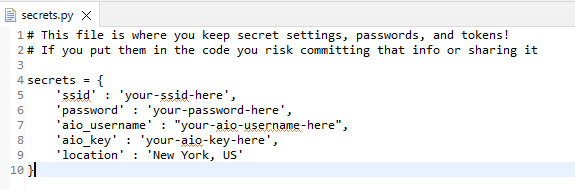
Aber das Ergebnis bleibt das Gleiche.
Also sind meine Fake-Credentials zu billig, als dass GitHub darauf anspringt, oder das Feature funktioniert anders als gedacht.
Ein Report soll als Word Dokument (.docx) verfügbar gemacht werden.
Dazu wird zuerst eine Word Datei als Template erstellt mit Platzhaltern an den entsprechenden Stellen. Die Ersetzung einzelner Wörter ist relativ trivial, das Befüllen einer Tabelle mit n Zeilen stellte sich dann etwas kniffliger heraus. Diese Notizen und das dazugehörige Beispielprojekt dienen als Erinnerungsstütze, falls der Zukunftsingo nach dem aktuellen Projekt noch einmal etwas mit docx4j machen darf.
Word mit einem leeren Dokument öffnen, einen Platzhalter für eine Überschrift, einen Text und eine Tabelle hinzufügen.
Die Überschriften der Tabelle sind fix und werden nicht ersetzt.
Die Anzahl der Zeilen in dem Report ist dynamisch.
Die Tabelle erhält keine Zeilen, diese werden später hineingeneriert.
Würde der Report eine Tabelle mit einer fixen Anzahl von Zeilen vorsehen, könnte man die ganze Tabelle in das Dokument eintragen und und später die einzelnen Werte per Wortersetzung hineingenerieren.

Die Tabelle bekommt noch einen Titel, um sie so eindeutig identifizieren zu können. Beispielsweise wenn das Dokument mehrere Tabellen enthält.
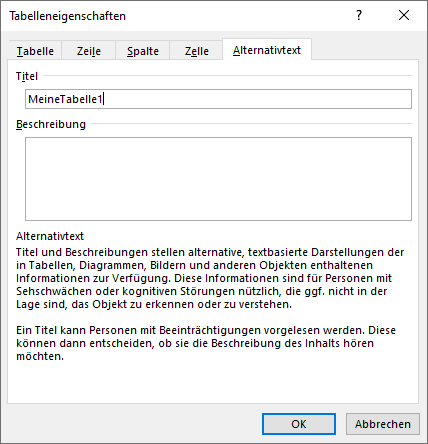
Abschließend unter dem Namen template.docx als Word-Dokument speichern, nicht als Strict Open XML-Dokument!
Ein neues Maven Projekt anlegen.
Die Datei template.docx nach src/main/resources kopieren.
Java Klasse anlegen, die das Template läd und eine neue Zieldatei im tmpdir mit teilgeneriertem Name anlegt. Dadurch erhalten wir bei jedem Durchlauf eine neue Datei, um sie ggf. noch einmal miteinander vergleichen zu können, und das Aufräumen übernimmt das Betriebssystem für uns.
Als Dummyaction wird das Template in die Zieldatei kopiert. An dieser Stelle kommt im nächsten Schritt Docx4J ins Spiel um das Template zu befüllen.
Im letzten Schritt lassen wir uns die Zieldatei mit Word öffnen um so direkt das Ergebnis überprüfen zu können.
public class Main {
public static void main(String[] args) throws Exception {
File template = getTemplateFile();
File output = getOutputFile();
Files.copy(Paths.get(template.toURI()), Paths.get(output.toURI()), StandardCopyOption.REPLACE_EXISTING);
Desktop.getDesktop().open(output);
}
private static File getTemplateFile() throws Exception {
File template = new File( Main.class.getClassLoader().getResource("template.docx").toURI() );
return template;
}
private static File getOutputFile() throws Exception {
String tmpdir = System.getProperty("java.io.tmpdir");
Path tmpfile = Files.createTempFile(Paths.get(tmpdir), "MyReport" + "-", ".docx");
return tmpfile.toFile();
}
}Um das Template befüllen zu können legen wir einen Report mit Beispieldaten an:
public class Report {
public String ueberschrift = "Sample Report";
public String text = "Lorem Ipsum";
public List<String[]> tabelle;
public Report() {
tabelle = new ArrayList<>();
tabelle.add(new String[] {"Montag", "Regen", "4°C"});
tabelle.add(new String[] {"Dienstag", "Wolkig", "6°C"});
tabelle.add(new String[] {"Mittwoch", "Sonne", "10°C"});
}
}Projekt Homepage: Link
Projekt GitHub Repository: Link
Artikel zum Einstieg: Baeldung
Dem Projekt dank Maven einfach die notwendigen Abhängigkeiten in der pom.xml hinzufügen:
<dependencies>
<!-- https://mvnrepository.com/artifact/org.docx4j/docx4j-JAXB-ReferenceImpl -->
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j-JAXB-ReferenceImpl</artifactId>
<version>11.4.9</version>
</dependency>
</dependencies>WordprocessingMLPackage wordPackage = WordprocessingMLPackage.load(template);
Wir suchen alle Texte und wenn ein Platzhalter gefunden wird, wird der Text mit dem Wert aus dem Report gefüllt:
private static void textErsetzen(WordprocessingMLPackage wordPackage, Report report) throws Exception {
List<Object> texts = wordPackage.getMainDocumentPart().getJAXBNodesViaXPath(XPATH_TO_SELECT_TEXT_NODES, true);
for (Object obj : texts) {
Text text = (Text) ((JAXBElement<?>) obj).getValue();
String textValue;
if ("ÜBERSCHRIFT1".equals(text.getValue())) {
textValue = report.ueberschrift;
} else if ("TEXT1".equals(text.getValue())) {
textValue = report.text;
} else {
textValue = text.getValue();
}
text.setValue(textValue);
}
}Resultat:

Wir laufen über alle Elemente und wenn eine Tabelle gefunden wird, wird deren Titel überprüft und dann die Tabelle befüllt.
private static void tabellenzeilenErzeugen(WordprocessingMLPackage wordPackage, Report report) {
for (Object o : wordPackage.getMainDocumentPart().getContent()) {
if (o instanceof JAXBElement) {
@SuppressWarnings("unchecked")
Tbl tbl = ((JAXBElement<Tbl>)o).getValue();
String tblCaption = tbl.getTblPr().getTblCaption() != null ? tbl.getTblPr().getTblCaption().getVal() : null;
if ("MyTabelle1".equals(tblCaption)) {
fillTabelle1(tbl, report);
} else {
System.out.println("tblCaption: " + tblCaption);
}
}
}
}
private static void fillTabelle1(Tbl tbl, Report report) {
for (String[] zeile : report.tabelle) {
addRow(tbl, zeile[0], zeile[1], zeile[2]);
}
}Bei den Einträgen in der Tabelle setzen wir noch den gewünschten Font.
private static void addRow(Tbl tbl, String... cells) {
ObjectFactory factory = new ObjectFactory();
// setup Font
String fontName = "Arial";
RFonts fonts = factory.createRFonts();
fonts.setAscii(fontName);
fonts.setCs(fontName);
fonts.setHAnsi(fontName);
RPr rpr = factory.createRPr();
rpr.setRFonts(fonts);
// new Row
Tr tr = factory.createTr();
for (String cell : cells) {
Tc tc = factory.createTc();
P p = factory.createP();
R r = factory.createR();
r.setRPr(rpr);
Text text = factory.createText();
text.setValue(cell);
r.getContent().add(text);
p.getContent().add(r);
tc.getContent().add(p);
tr.getContent().add(tc);
}
tbl.getContent().add(tr);
}Resultat:

wordPackage.save(output);
Projekt zum Extrahieren der Daten der WISIA Webseite.
Ich benötige die Daten der Artenschutzdatenbank des Bundesamt für Naturschutz in Bonn.
Deren Wissenschaftliches Informationssystem zum Internationalen Artenschutz liefert diese Informationen über eine Webseite. Weder API noch Datenbankkopie sind verfügbar.
Daher musste ich die Seite jeder einzelnen Art aufrufen, die Informationen extrahieren und verarbeiten.
Mit dem Projekt speichere ich den Weg, wie ich meine Kopie der Artenschutzdatenbank aufgebaut habe. So kann jederzeit eine neue Version der Artenschutzdatenbank erstellt werden, beispielsweise nach einem Update der Original Datenbank.
Das Projekt ist weder universell, flexibel, konfigurierbar oder sonst was, sondern dient nur diesem einen Zweck.
Auf der WISIA Seite kann man eine Recherche starten, zB zu "testudo":
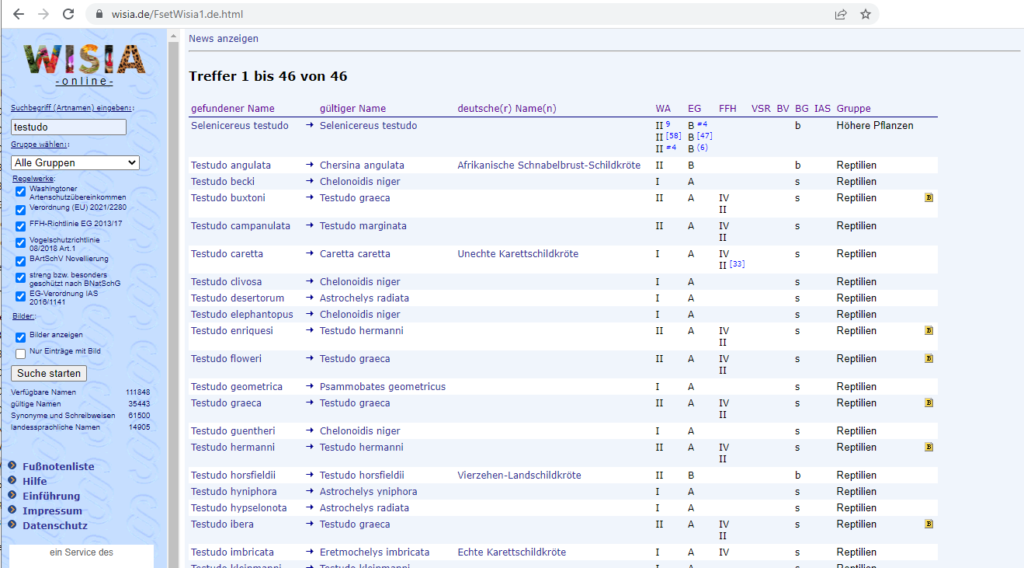
Von dort gelangt man auf die jeweilige Seite einer Art, zB "Testudo hermanni":
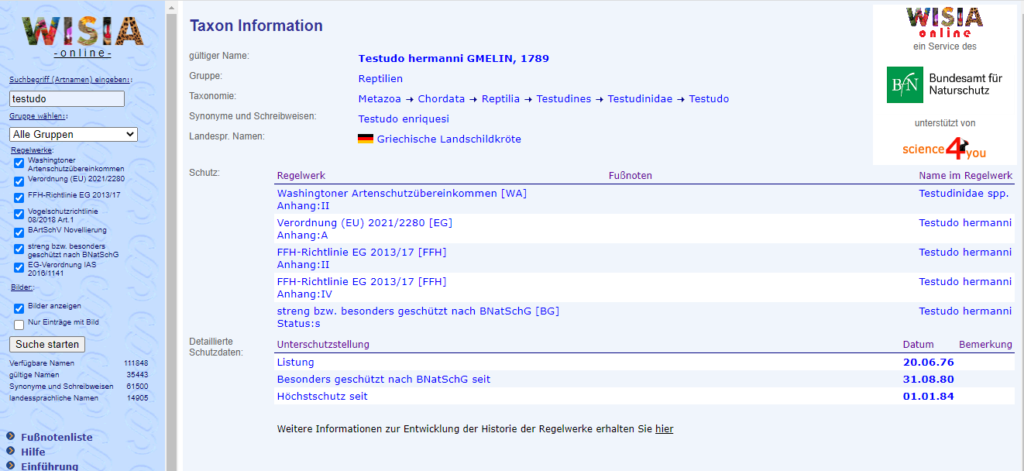
Eine Analyse des HTML Source Codes der Seite zeigt, dass die Seite über ein Frameset zusammengebaut ist und der rechte Teil mit den Informationen eine eigene Seite ist. Diese Seite wird über einen eindeutigen Parameter, der Knoten ID, aufgerufen.
Für Testudo hermanni lautet die Knoten ID: 19442.
Der Aufruf der Seite: https://www.wisia.de/GetTaxInfo?knoten_id=19442:
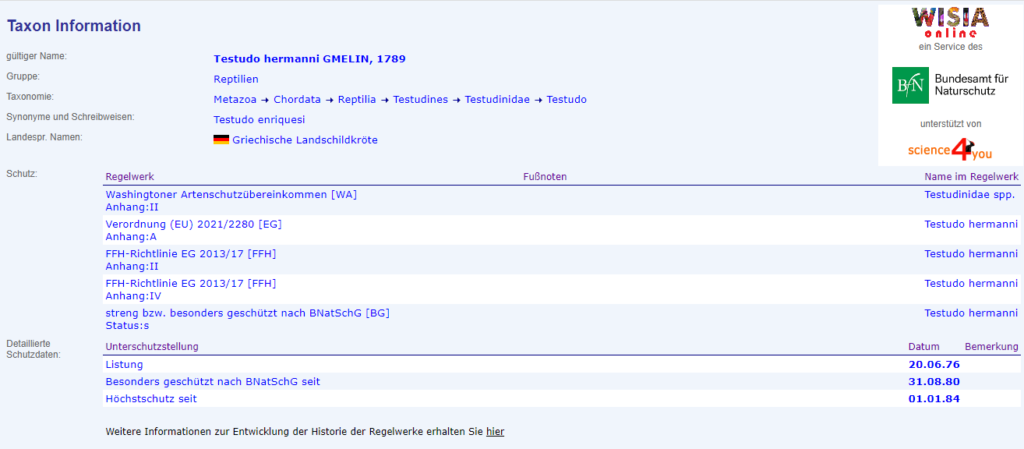
Auf der Seite finden sich strukturiert alle Informationen zu der Art.
Leider ist es technisch nicht so, dass es eine leere Vorlage der Seite ist, die anschließend zB über einen REST Aufruf, der ein JSON Objekt zurückgibt, gefüllt wird. Das hätte es mir bedeutend einfacher gemacht.
So muss ich für jede Art die komplette Seite laden und die Informationen selbst extrahieren.
TODO: funktionierendes Mermaid-Plugin installieren.
Workaround: Screenshot
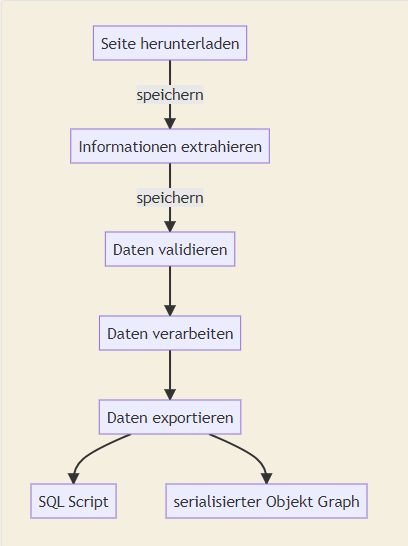
In einem ersten Schritt lade ich die jeweilige Seite einer Art auf meinen Arbeitsrechner herunter und speichere sie. Anschließend kann ich mit der gespeicherten Seite weiter arbeiten und muss sie nicht jedesmal neu ziehen, um darauf zuzugreifen.
Die Seiten werden als GZIPte Objekte gespeichert.
Am Ende hatte ich über 7 GB gespeichert, bei einer Kompression auf ca. 25% habe ich also ca. 30 GB heruntergeladen.
Im nächsten Stritt werden die Informationen der Seite extrahiert und gespeichert.
Die Informationen werden als GZIPte Objekte gespeichert.
Die gespeicherten Objekte haben eine Größe von knapp 43 MB.
Für das Verarbeiten der Seite habe ich HtmlUnit verwendet.
<!-- https://mvnrepository.com/artifact/net.sourceforge.htmlunit/htmlunit --> <dependency> <groupId>net.sourceforge.htmlunit</groupId> <artifactId>htmlunit</artifactId> <version>2.70.0</version> </dependency>
Seiten ohne gültigem Namen werden aussortiert, zu deren Knoten ID ist keine Art zugeordnet.
Seiten mit gültigem Namen aber ohne Taxonomie werden ebenfalls aussortiert.
Der gültige Name / wissenschaftliche Name ist nicht eindeutig, daher muss die eindeutige Knoten ID weiter verwendet werden.
Bei der Taxonomie bin ich davon ausgegangen, dass die Pfade alle eindeutig sind. Ich war überrascht, dass dem nicht so ist. Es existieren einige Einträge mit mehreren Elternknoten.
Beispielsweise Gomphus kann über Gomphidae, aber auch über Gomphaceae erreicht werden.
Das ist aber anscheinend korrekt, denn ich fand folgendes:
Duplicate name. This name, above species rank, is duplicated within the NCBI classification
https://www.ncbi.nlm.nih.gov/Taxonomy/Browser/wwwtax.cgi?mode=Info&id=107809
Hier die uneindeutigen Taxonomien:
Aus den extrahierten Daten muss ich eine Struktur ableiten und diese dann dorthin überführen.
Die verarbeiteten Daten werden als ein serialisiertes, gezippte Objekte gespeichert. Dieses ist weniger als 2MB groß und kann in wenigen Sekunden geladen werden.
Ursprünglich hatte ich die Idee, ein SQL-Schema zu schreiben und die Daten als INSERT-INTO-Scripte generieren zu lassen. Kann vielleicht nochmal kommen.
Letztendlich habe ich aber die Objekt Datei verwendet.
Neuer Rechner - neues Glück. Aber auch neu zu installierende Software. Und bei Toad hatte ich ein paar Probleme Herausforderungen, die ich mir bei der nächsten Installation ersparen möchte.
Es fing schon damit an, überhaupt die Installationsdateien für Toad zu bekommen. Zuerst bin ich auf Toadworld gelandet und dort will man mir erstmal eine Subscripton verkaufen, und mir dazu erstmal eine Trial Version zur Verfügung stellen. Möglicherweise kann man die Version mit einer bestehenden Lizenz zur Vollversion aufwerten, vielleicht aber auch nicht. Will man mit diesem Risiko den Alt-Laptop mit funktionierender Datenbank Software abgeben? Nach Murphy's Law kommt dann garantiert ein schweres Datenbank Problem am Tag nach Ablauf des Testzeitraums. Klar, es gibt dann auch anderes Tools, wie zB den Oracle SQL Developer, mit denen man dann zur Not arbeiten könnte. Aber dafür zahlt man ja nicht viel Geld für Professional Edition von Toad.
Ich betreue eine Anwendung, die in eine Oracle DB nutzt, für einen Kunden, der auch die Lizenz für Toad bereit gestellt hat. Ich könnte mich also an den Kunden wenden, der das dann an die interne Stelle für Beschaffung weiter leitet, die dann die Firma für die Lizenzen kontaktiert, die dann Quest kontaktieren können. Ich habe das Thema dann erstmal liegen lassen.
Im zweiten Anlauf habe ich besser gesucht und tatsächlich die Downloadseite gefunden: Produktsupport - Toad for Oracle
Der Download kann beginnen:
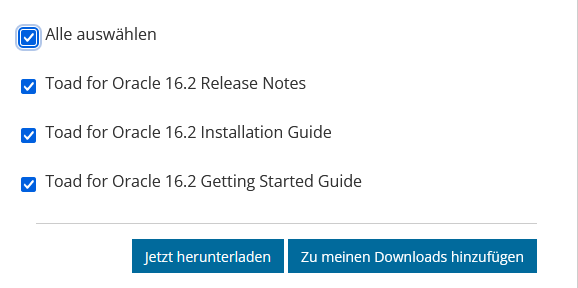
Die Installation kann beginnen. Zum Glück wurde die Subscription immer verlängert, den die Permanent License wurde für Version 10 erworben, aktuell ist 16:
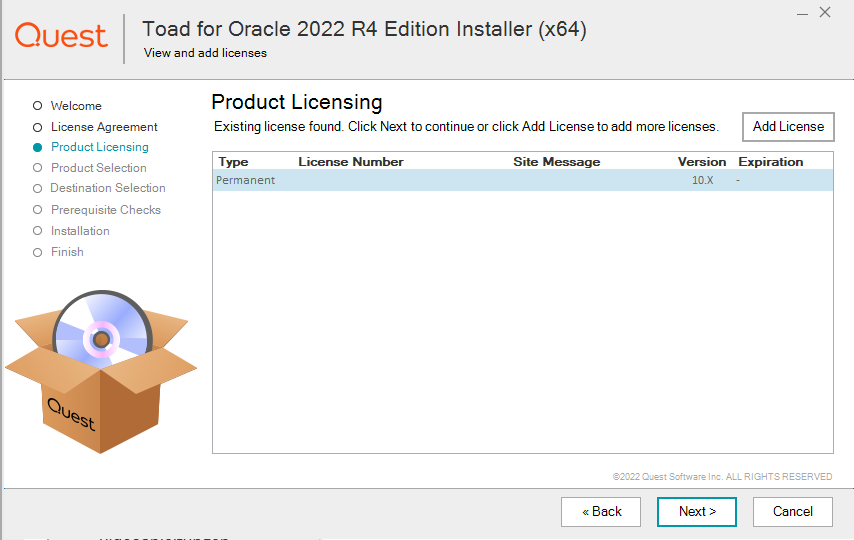
Leider bricht die Installation ab, es wird erst der Oracle Client verlangt:
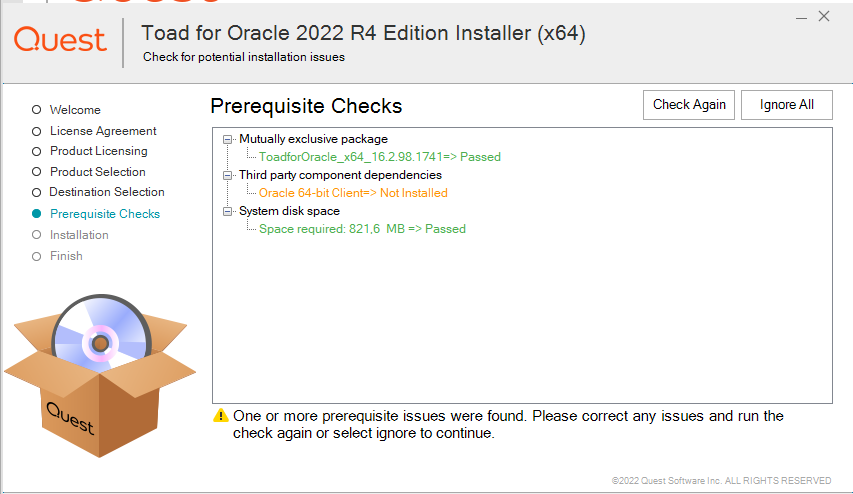
Zuerst den Oracle Instant Client herunterladen. Ich wähle das Basic Package und zusätzlich die beiden optionalen Packages für SQL*Plus und Tools.
The installation instructions are at the foot of the page.
Oracle Instant Client, SQL*Plus und Tools entpacken, zB in das Verzeichnis: C:\Program Files\Oracle
PATH Variable setzen.
Dazu einfach die Windows 10 Suche benutzen und "Systemumgebungsvariablen bearbeiten" suchen.
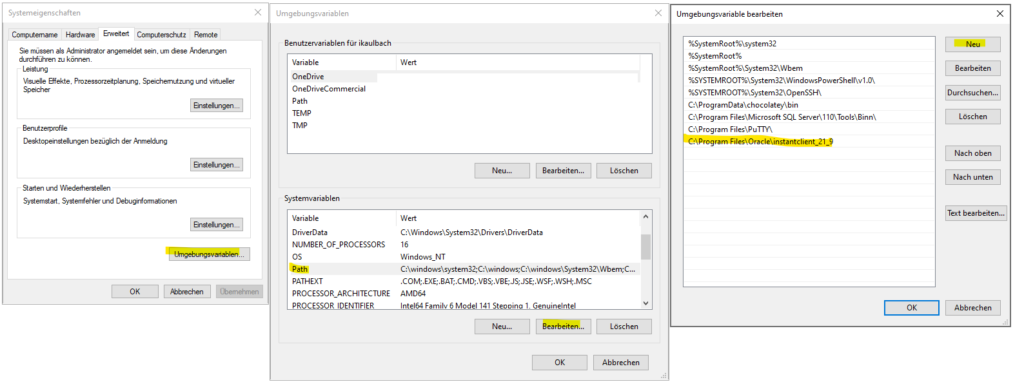
In einer frisch geöffneten PowerShell kann man sich den Erfolg anzeigen lassen:
echo $ENV:PATH
Instant Client 19 requires the Visual Studio 2017 redistributable. Also die auch noch herunterladen & installieren.
Nach einem Neustart konnte dann Toad installiert werden.
TOAD doesn't like blank lines in SQL statements
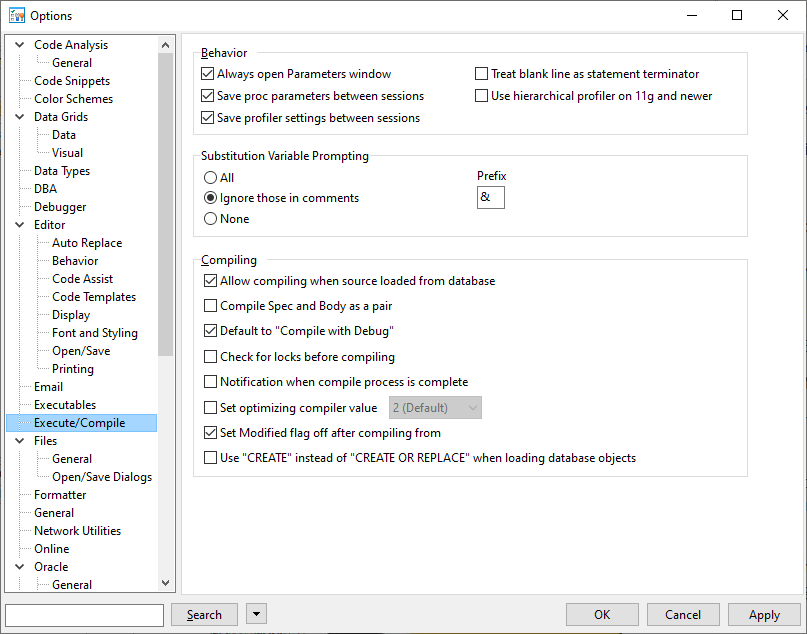
Seit der Version 12.9 ist im TOAD standardmäßig die Option aktiviert, dass im Editor neue Zeilen als Befehlsende gelten. Dies empfand ich als sehr störend, da einige Foundation-Templates Leerzeilen enthalten und habe daher die Option deaktiviert:
View → Toad Options → Editor → Execute/Compile → Treat blank line as statement terminator
Obigen Hinweis hatte ich mir in einer früheren Installation notiert und füge das mal hier hinzu, aber es scheint so, als ob das obsolet geworden ist:
Vor einigen Wochen hat ein Kollege in einem internen TecTalk das Tool Mermaid vorgestellt und mein Interesse geweckt.
Mit Mermaid kann man Diagramme erstellen. Das können andere Tools auch, aber Mermaid verfolgt einen eigenen Ansatz: Während andere Tools Diagramme erzeugen, die zB als Bilder (png, jpeg, ...) exportiert und so in anderen Dokumenten verwendet werden können, generiert Mermaid die Diagramme aus Code/Text heraus.
Mermaid
GitHub - mermaid-js/mermaid: Generation of diagrams like flowcharts or sequence diagrams from text in a similar manner as markdown
Generate diagrams from markdown-like text.
Dadurch, dass die Diagramme aus Code generiert werden, sind sie sehr leicht anpassbar und können beispielsweise in der Projekt Readme verwendet werden, ohne dass erst das Diagramm in einem eigenen Tool bearbeitet, exportiert, in das Projekt kopiert und in der Readme verlinkt werden muss.
-> "Documentation as Code"
Homepage von Mermaid
GitHub von Mermaid
Live Editor um direkt online loslegen zu können
Klingt auf jeden Fall sehr interessant, auf diese Weise etwas schnell grafisch dokumentieren zu können.
Ich werde die Integration in WordPress, GitHub und Eclipse ansehen.
Diesen Code:
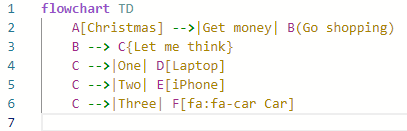
wandelt Mermaid in dieses Diagramm um:
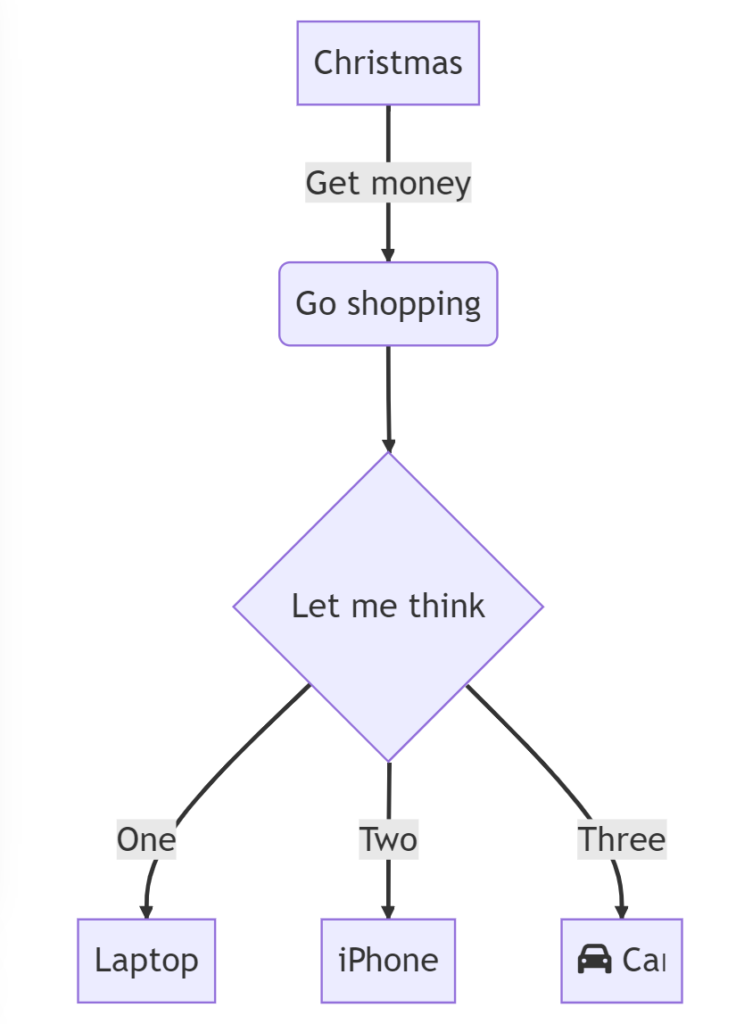
Das Beispiel ist aus dem Live Editor von Mermaid.
Die Auswahl an WordPress Plugins für Mermaid ist überschaubar:
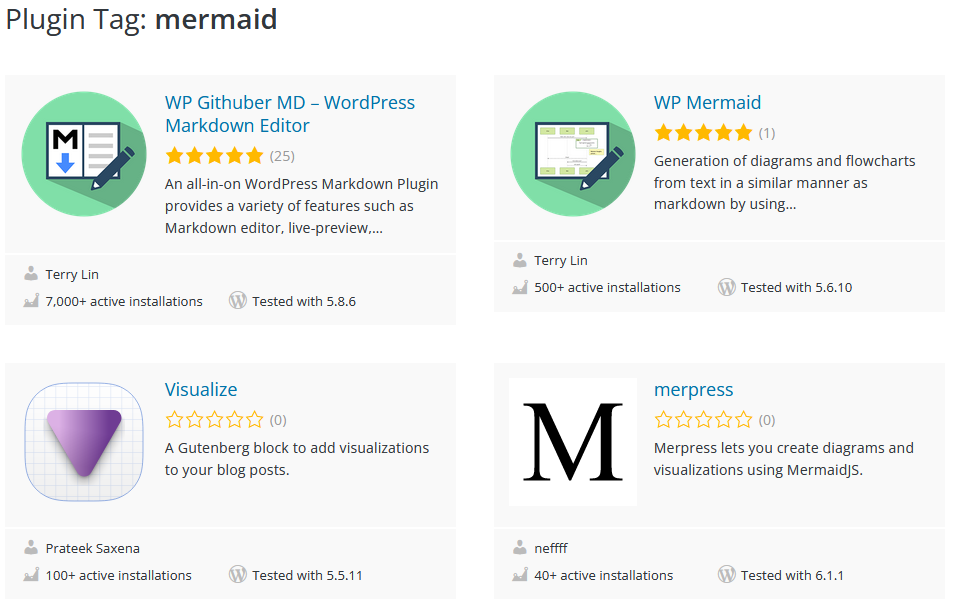
Aufgrund der Anzahl aktiver Installationen entscheide ich mich für ein Plugin von Terry Lin. Ich habe erst überlegt, nur das reine Mermaid Plugin zu nehmen, mich dann aber für den kompletten Markdown Editor mit Mermaid Unterstützung entschieden, denn es könnte eine gute Ergänzung zu meinen Code Mirror Block Plugin sein.
WP Githuber MD installiert. Getestet. Deinstalliert.
Problem: Mit dem Plugin kann man NUR noch den Markdown Editor verwenden und nicht mehr den Live Editor von WordPress.
Ich möchte aber gezielt einzelne Markdown bzw. Mermaid Blöcke in meine Seite einbinden und ansonsten den bequemen WYSIWYG Editor verwenden.
Und während ich das hier im WP Editor schreibe, merke ich, dass ich das Plugin noch gar nicht deinstalliert habe und trotzdem kein Markdown verwenden muss. Nach einiger Suche finde ich dann die Möglichkeit, Markdown ein- bzw. auszuschalten. Allerdings geht das immer nur für den ganzen Post. Ich möchte das aber nur für einzelne Blöcke verwenden und nicht deswegen den ganzen Post im Texteditor schreiben müssen.
Nächster Test: WP Mermaid
WP Mermaid is smart enough that loads mermaid.js only when your posts contain Mermaid syntax, by detecting the use of shortcode and block. So it will not be loaded on your website everywhere.
https://www.commoninja.com/discover/wordpress/plugin/wp-mermaid
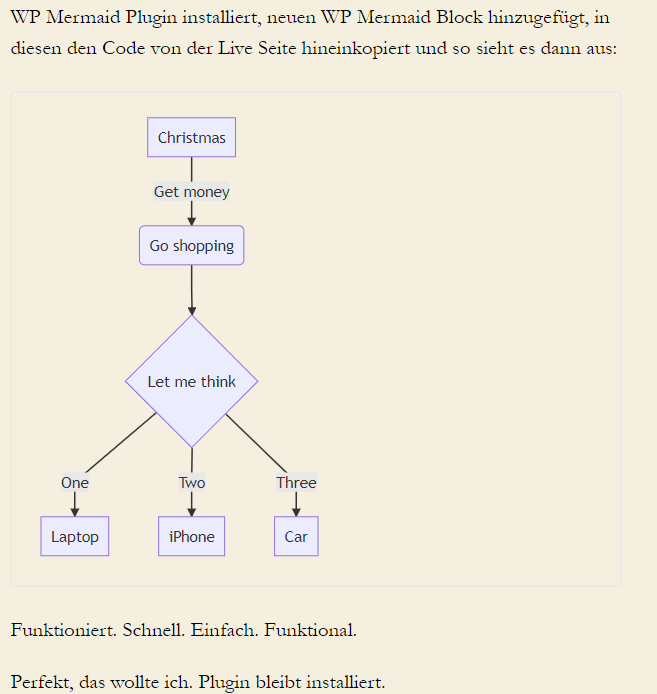
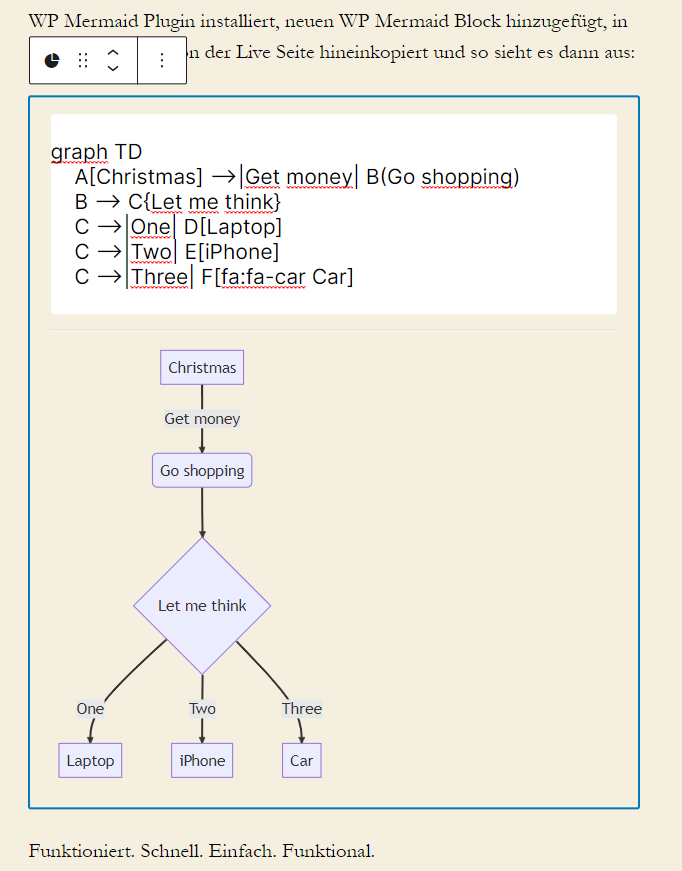
WP Mermaid Plugin installiert, neuen WP Mermaid Block hinzugefügt, in diesen den Code von der Live Seite hineinkopiert und so sieht es dann aus:
Funktioniert. Schnell. Einfach. Funktional.
Perfekt, das wollte ich. Plugin bleibt installiert.
Wie funktioniert es in GitHub?
Dieser Blogeintrag verrät es: Include diagrams in your Markdown files with Mermaid
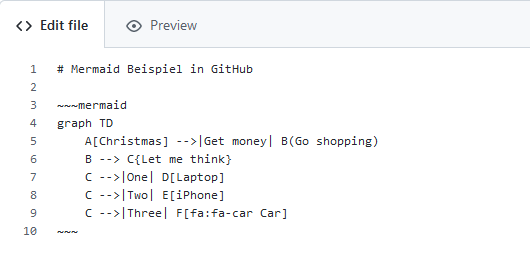
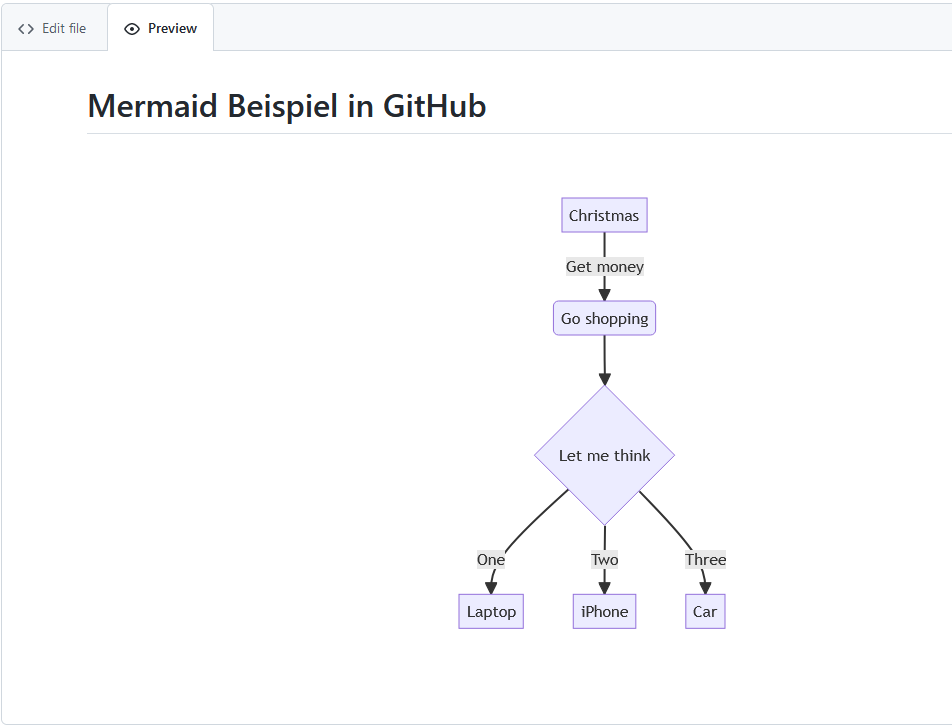
Auf die GitHub Seite, eine README.md eines Projektes im Browser im Editor geöffnet, in Edit file den Code eingegeben und im Preview das Diagramm angesehen.
In meinem Eclipse habe ich noch keinen Markdown Editor, wenn ich eine .md Datei öffnen möchte, erscheint der Hinweis:
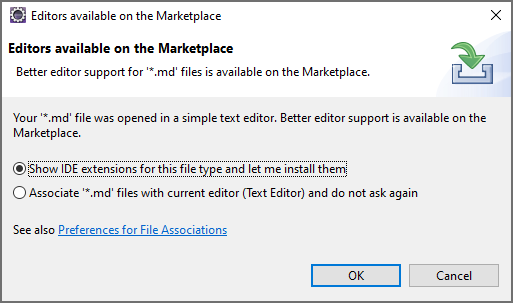
Da ich bisher selten Markdown verwendet habe, habe ich das ignoriert, auf die Vorschau verzichtet und im Texteditor gearbeitet.
Ich vermute, dass ich Mermaid nur in Markdown Dateien verwenden kann, daher muss ich einen passenden Editor suchen.
Bisher war übrigens ein Markdown Editor in Eclipse enthalten, aber im Release 2022-06 wurde er irrtümlich entfernt.
Über Install New Software ist Mylyn WikiText schnell nachinstalliert.
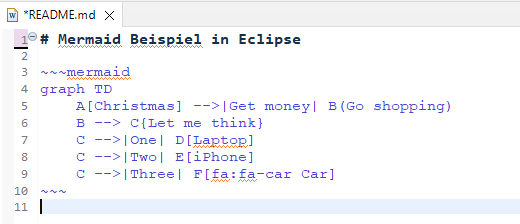

Der Markdown Editor funktioniert, aber leider Mermaid nicht.
Kein Mermaid Support in Eclipse?
Kann ich mir eigentlich nicht vorstellen, aber ich konnte kein Plugin und keine Anleitung finden.
Ich belasse es erstmal dabei, zur Not erstelle ich die Diagramme online und sehe sie mir dann in GitHub an bis ich eine Lösung für Eclipse gefunden habe.
Das WP Mermaid Plugin scheint nicht richtig zu funktionieren, denn während es im Editor Modus so aussieht, wie es soll, sieht es bei "normalen" Aufruf der Seite verunglückt aus:

Und so sieht es im Editor aus:
Das Problem ist bekannt:
Heute (07.06.23) habe ich das WP Mermaid Plugin auf Version 1.0.2 geupdated.
So sieht es jetzt im Editor im Bearbeiten-Modus aus:
Und so sieht es in der normalen Ansicht aus:
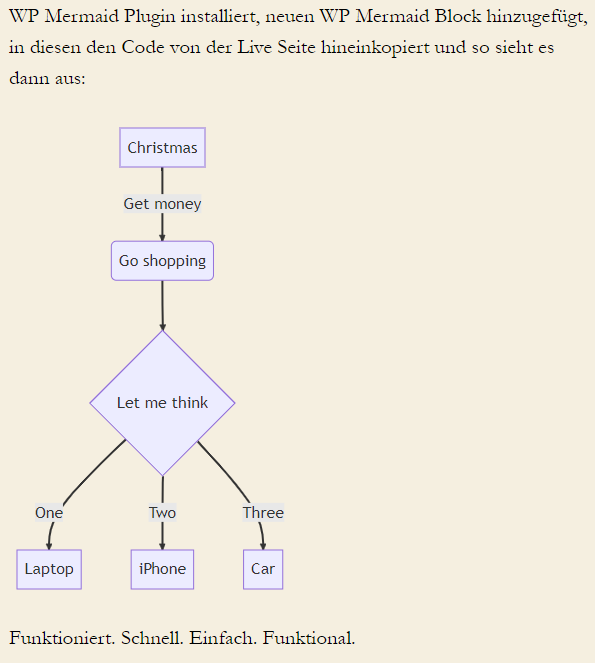
Jetzt scheint es also wirklich zu funktionieren! 🥳