For my last post about PrivateGPT I need to install Ollama on my machine.
The Ollama page itself is very simple and so is the instruction to install in Linux (WSL):
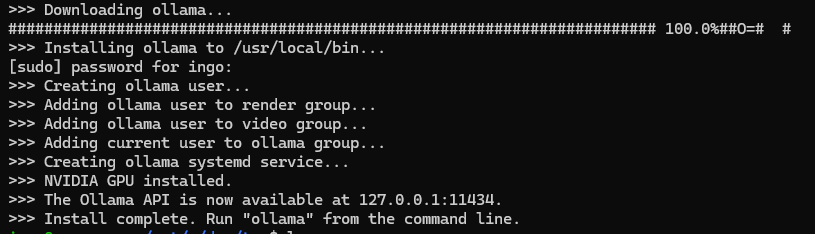
curl -fsSL https://ollama.com/install.sh | sh
ollama serve
Couldn't find '/home/ingo/.ollama/id_ed25519'. Generating new private key.
Your new public key is:
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIGgHcpiQqs4qOUu1f2tyjs9hfiseDnPfujpFj9nV3RVt
Ollama is bound to localhost:11434. So Ollama is only available from localhost or 127.0.0.1, but not from other IPs, like from inside a docker container.
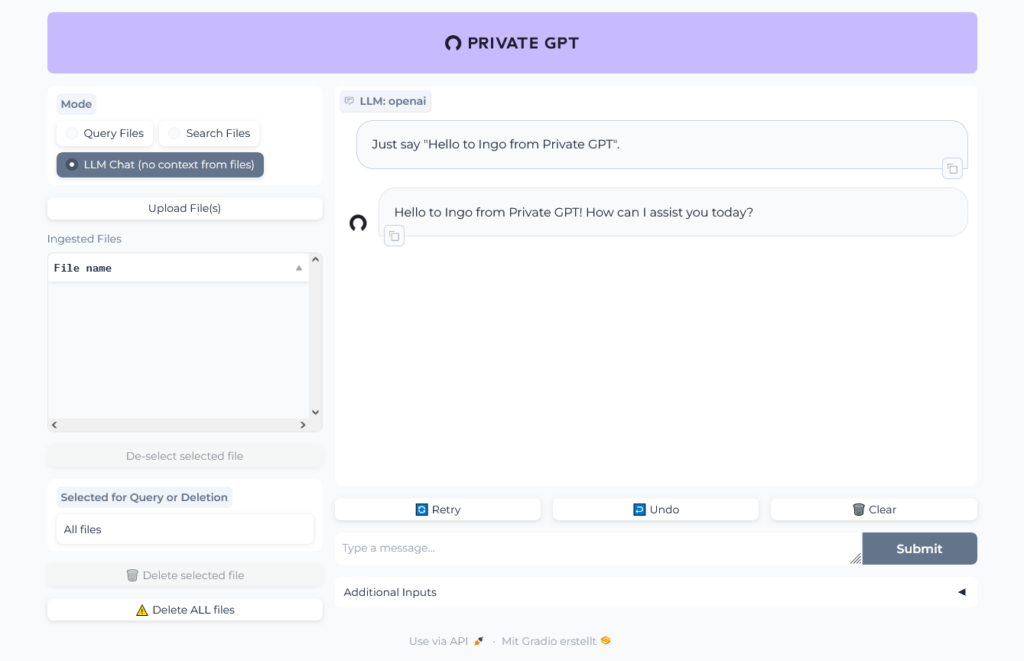
To start with an easier example, I will use PrivateGPT with OpenAI/ChatGPT as AI. Of course therefore the chat will not be private, what is the main reason to use PrivateGPT, but it is a good start to bring things up and running and in a next step add a local AI.
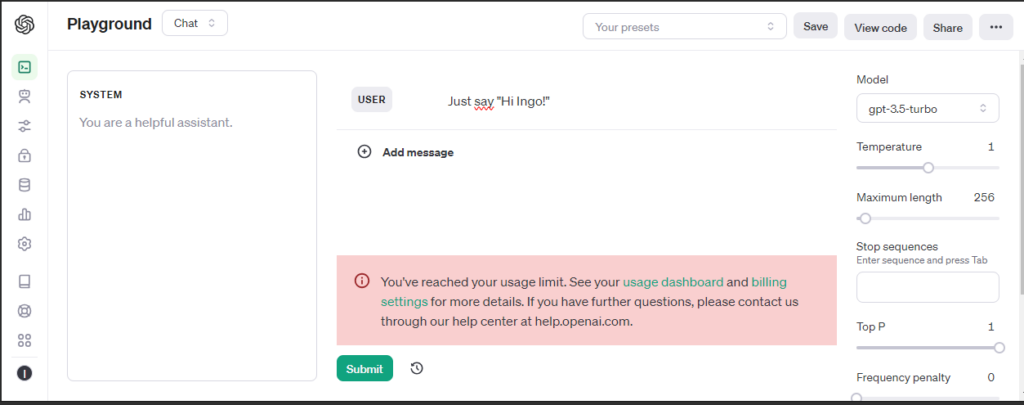
OpenAI API key
To use ChatGPT we need an OpenAI API key. The key itself is free, but I needed to charge my account with 5$ to get it working.
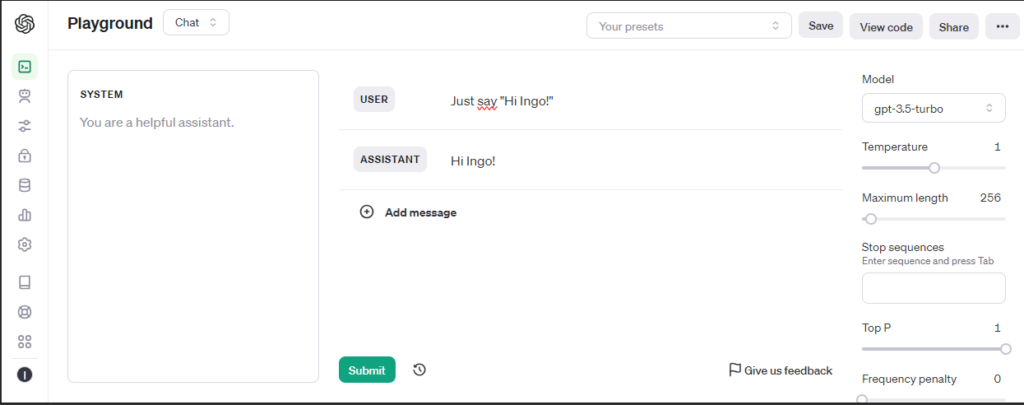
For testing a Playground is available.
Before funding my account:
After funding my account with the minimum of 5$:
Docker
The OpenAI API key is stored in a file .env, that provides its content to docker compose as environment variables.
In docker-compose we set the API key and profile: openai as environment for our Docker container:
In Docker image we configure installation for openai:
RUN poetry install --extras "ui llms-openai vector-stores-qdrant embeddings-openai"
PrivateGPT will download Language Model files during its setup, so we provide a mounted volume for this model files and execute the setup at the start of the container and not at image build:
volumes:
- ../models/cache:/app/privateGPT/models/cache
command: /bin/bash -c "poetry run python scripts/setup && make run"
Here are the complete files, you can also find them on my GitHub:
# Use the specified Python base image
FROM python:3.11-slim
# Set the working directory in the container
WORKDIR /app
# Install necessary packages
RUN apt-get update && apt-get install -y \
git \
build-essential
# Clone the private repository
RUN git clone https://github.com/imartinez/privateGPT
WORKDIR /app/privateGPT
# Install poetry
RUN pip install poetry
# Lock and install dependencies using poetry
RUN poetry lock
RUN poetry install --extras "ui llms-openai vector-stores-qdrant embeddings-openai"
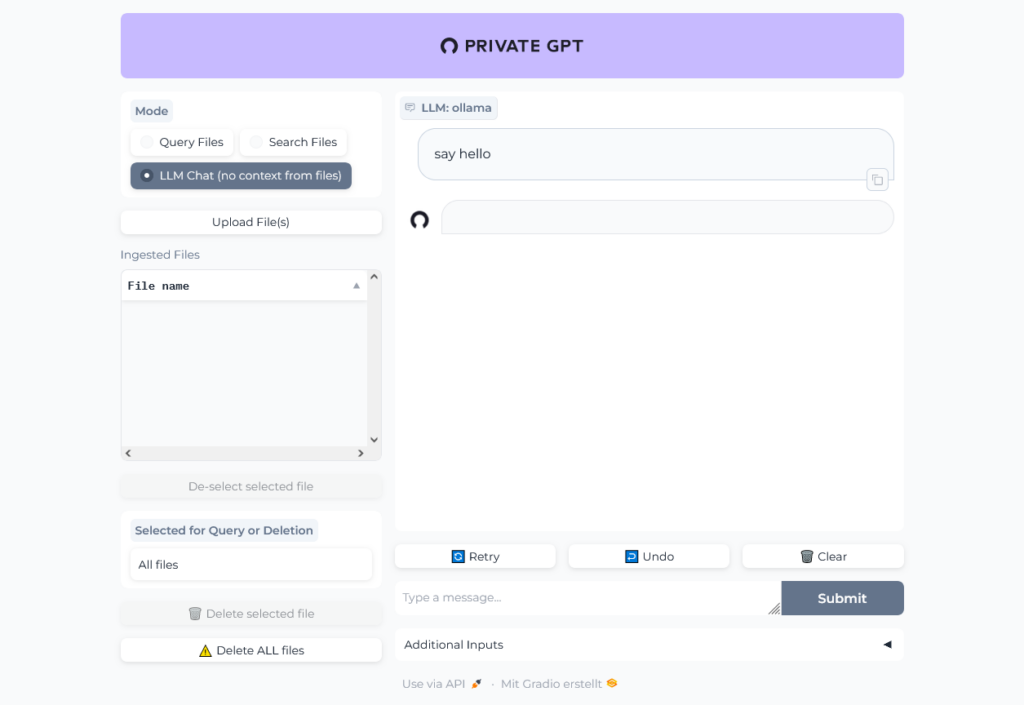
Open http://localhost:8001 in your browser to open Private GPT and run a simple test:
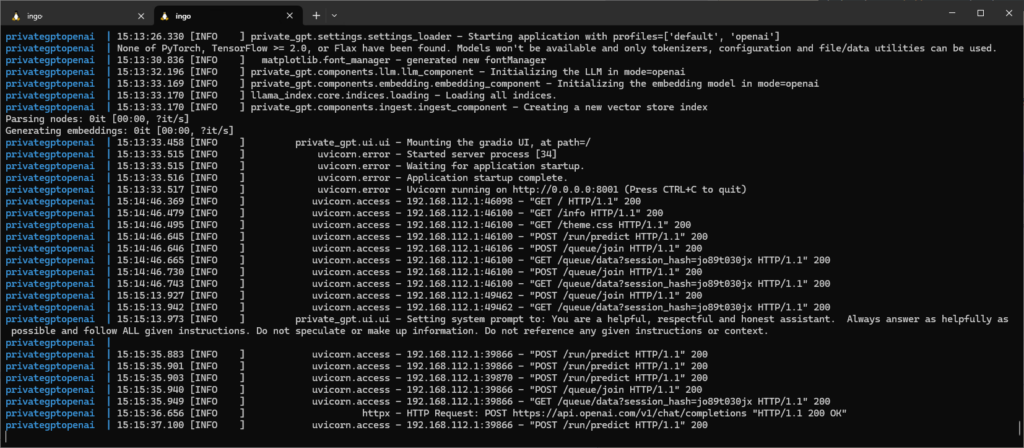
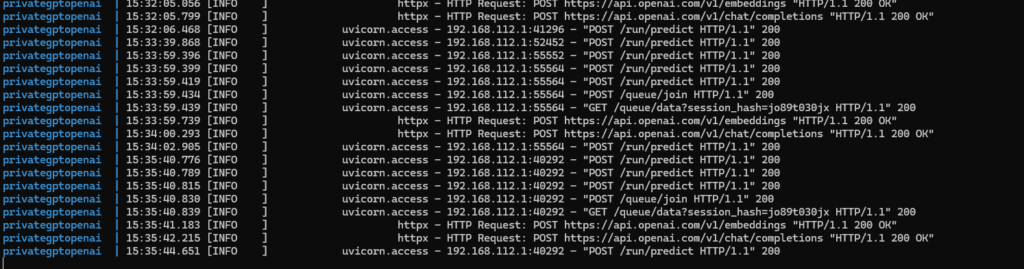
Have a look at the logs to see that there is communication with OpenAI servers:
Chat with document
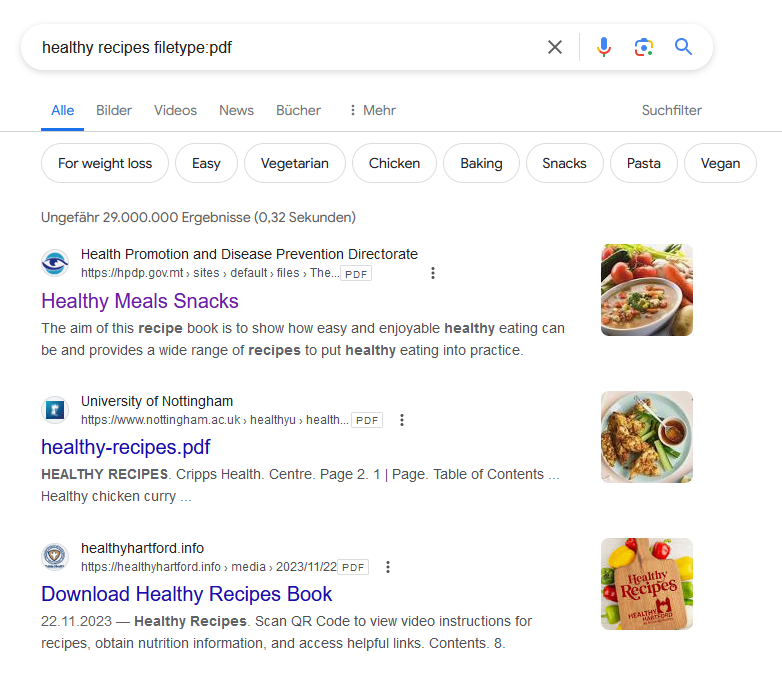
To "chat" with a document we first need a public available one, because right now we are using ChatGPT where we must not upload internal project documents.
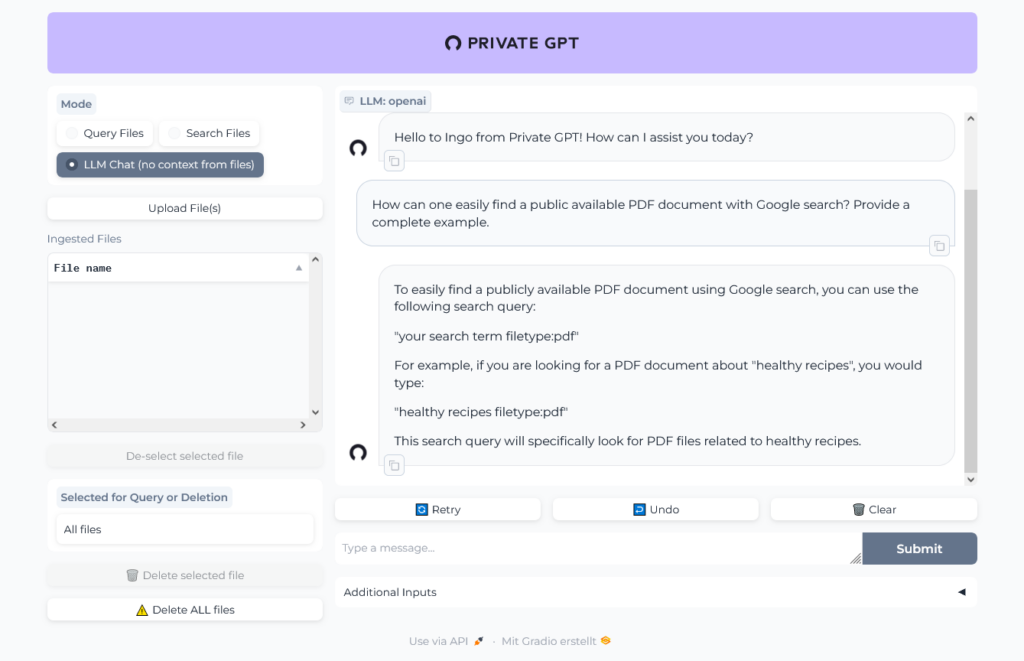
So first ask PrivateGPT/ChatGPT to help us to find a document:
Working fine, we could easily find and download a PDF:
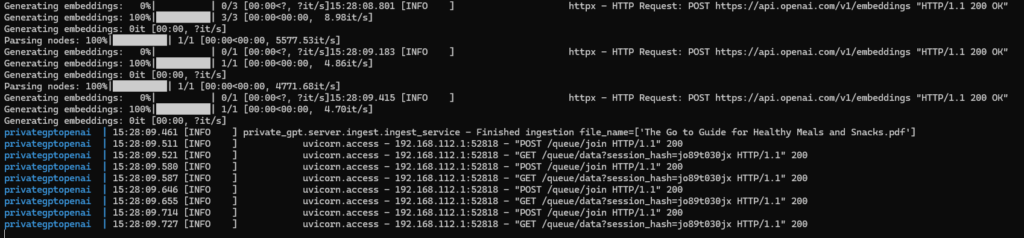
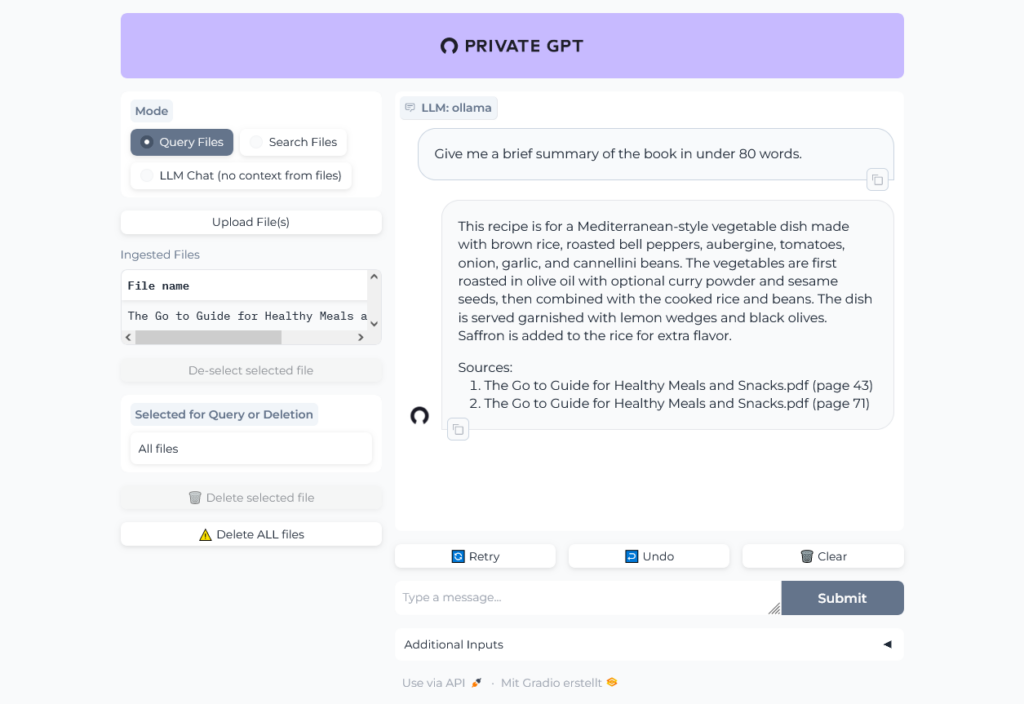
The upload of the PDF (The Go to Guide for Healthy Meals and Snacks.pdf) with 160 pages in 24 MB into PrivateGPT took nearly two minutes. In the logs we can see, that the file was uploaded to ChatGPT:
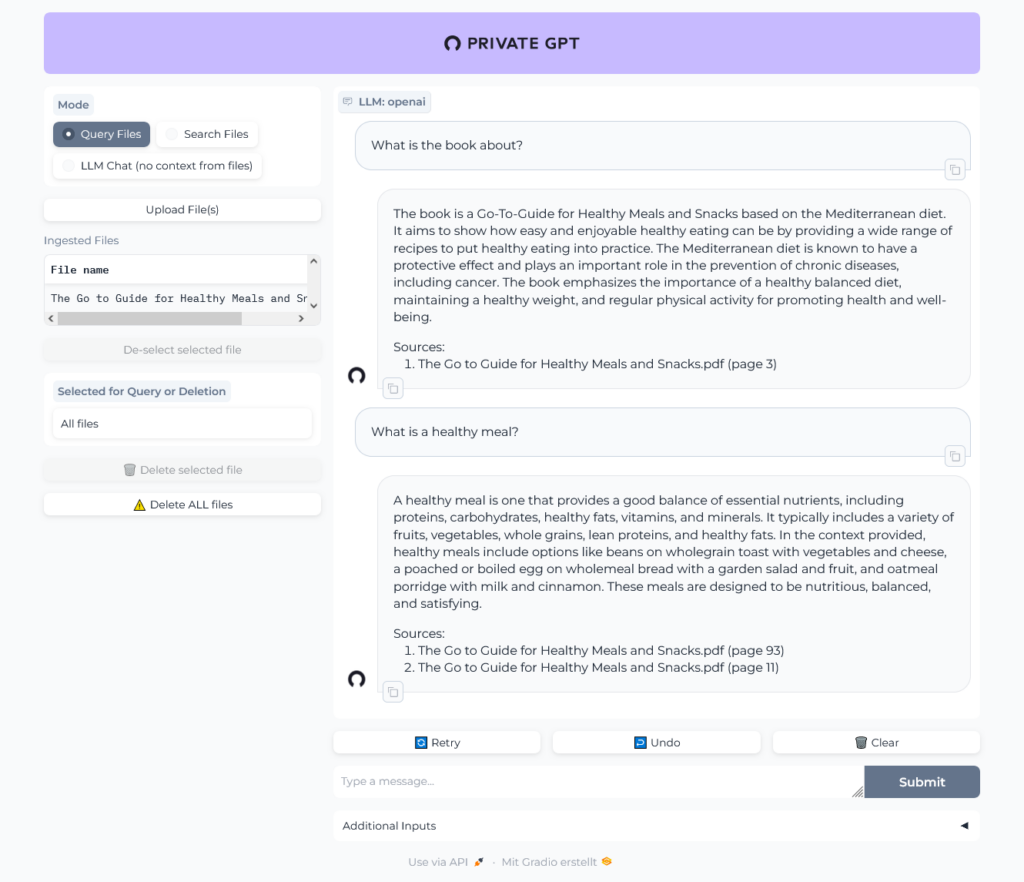
Let's chat with the book:
Uh, was that question too hard? Give it another try:
OK, sounds better. In the logs we can see the traffic to OpenAI:
Local, Ollama-powered setup
Now we want to go private, baby.
Copy configuration to a new folder, can be found in GitHub.
In docker-compose we change the profile to ollama:
environment:
- PGPT_PROFILES=ollama
In Docker image we configure installation for ollama:
RUN poetry install --extras "ui llms-ollama embeddings-ollama vector-stores-qdrant"
As before we can build the image, start the container and watch the logs:
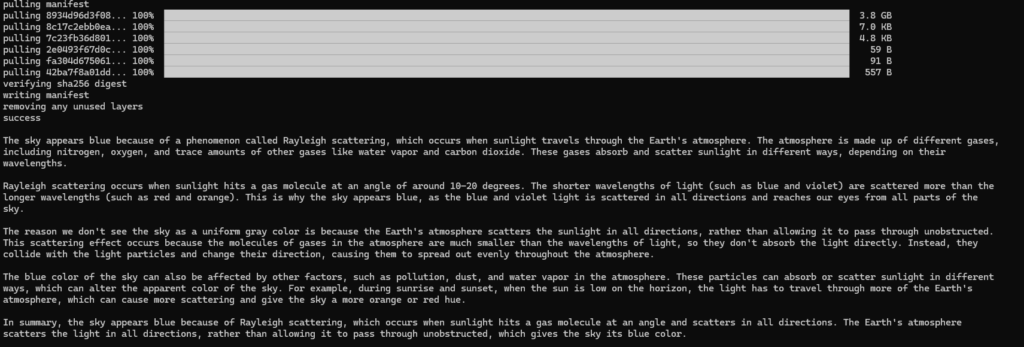
I did not use the large ~24MB file I tried with ChatGPT, but a much smaller one ~297 KB I randomly found in the internet. It is written in german, but it seems, like Ollama understands german.
Well, then I tried the 24 MB file and ... it worked pretty well, the result of the first question was even better than the result from ChatGPT!
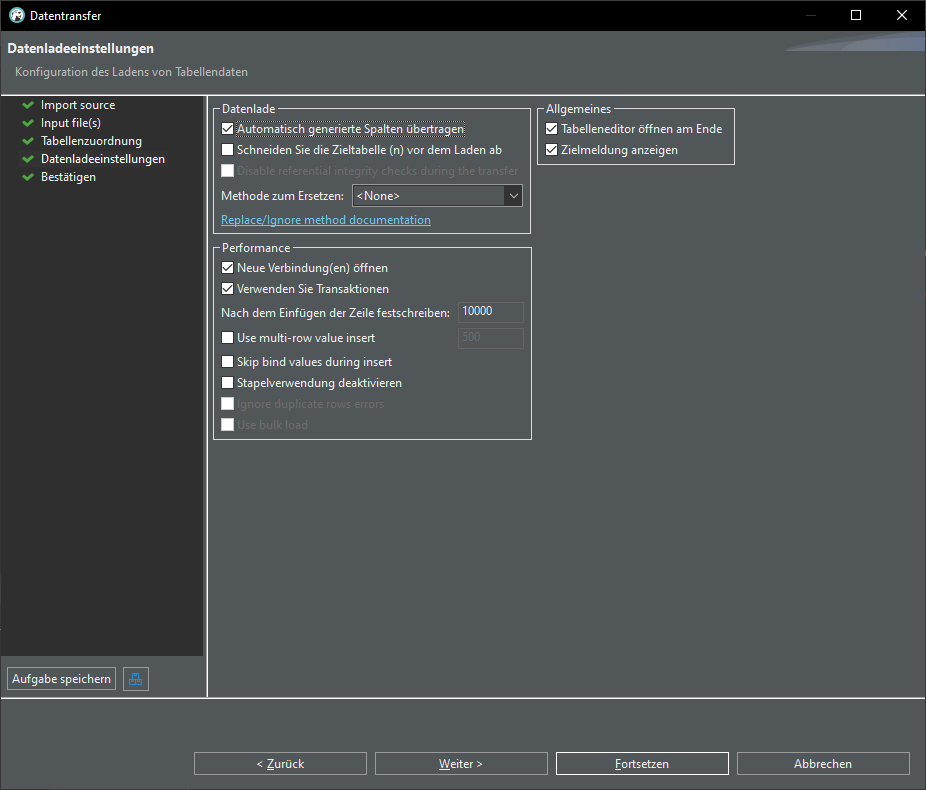
There are many ways to work with data, here is a quick walkthrough how to transfer data from an Excel file into a database.
Excel-File -> CSV-File -> DBeaver -> PostgreSQL
Excel file
We have a simple Excel file:
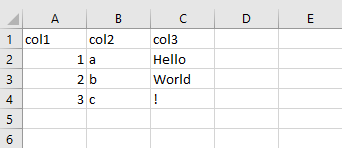
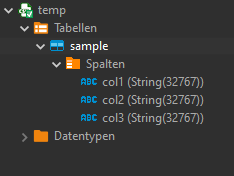
with a simple sample data structure:
Excel file conversion
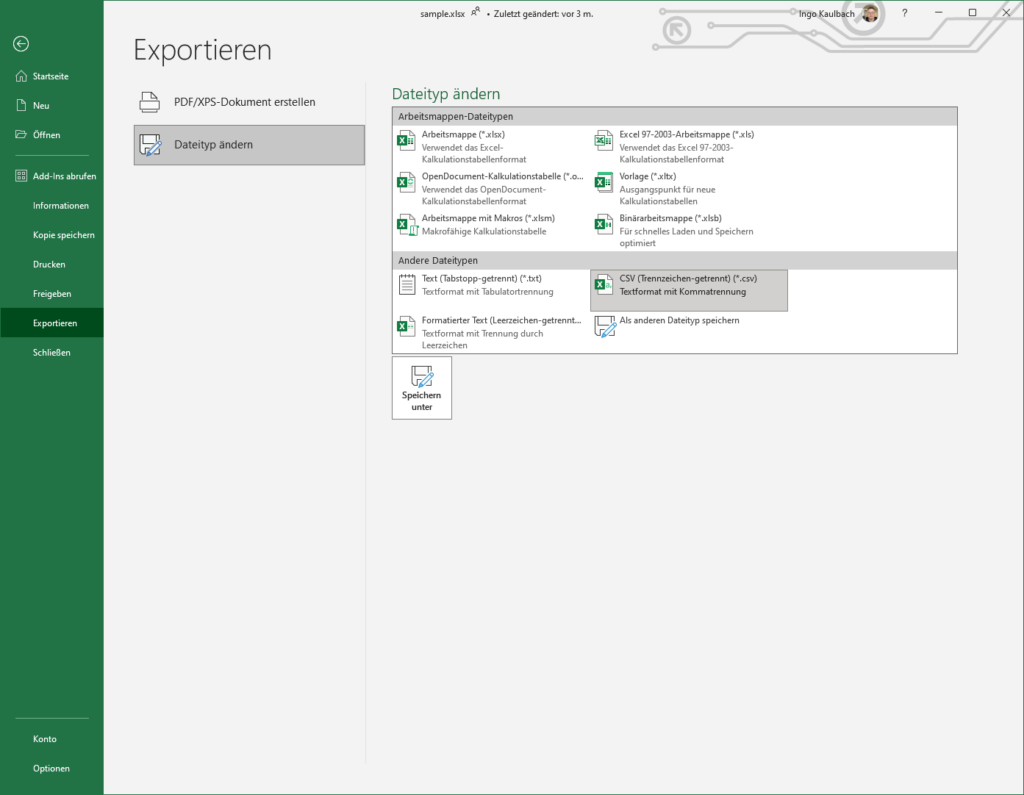
We need to convert the Excel file into a .csv (Comma Seperated Values) file.
Just open the file -> Datei -> Exportieren > Dateityp ändern -> CSV and save as sample.csv
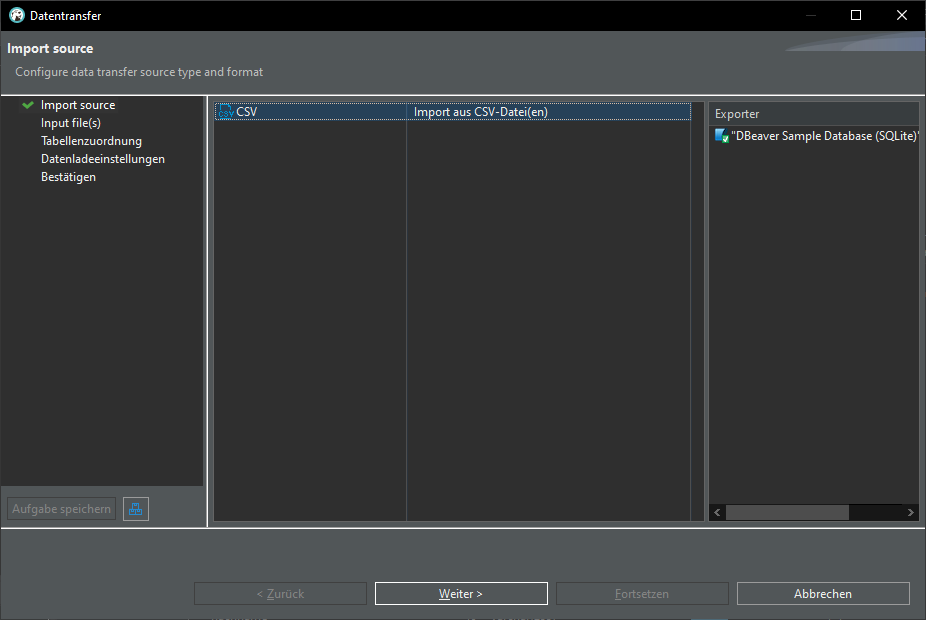
Import from CSV
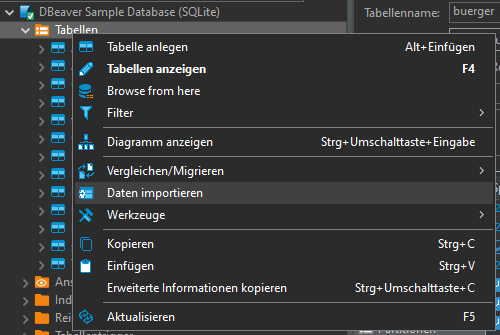
In DBeaver:
Open Database connection -> database -> schema -> Rightclick -> Data import:
Import from CSV:
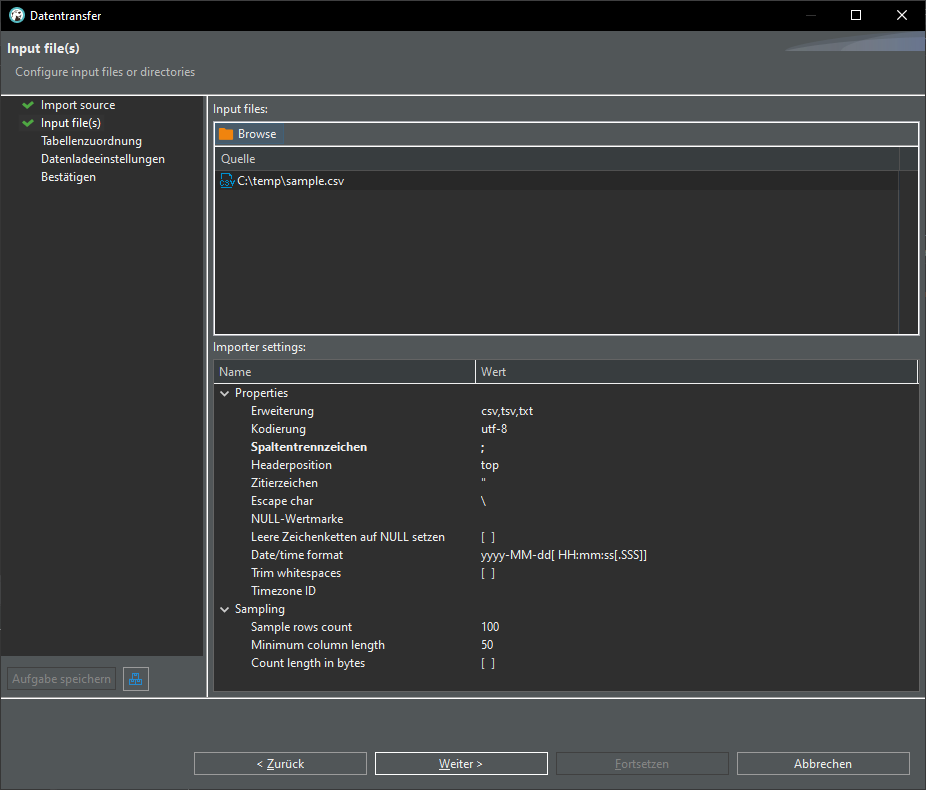
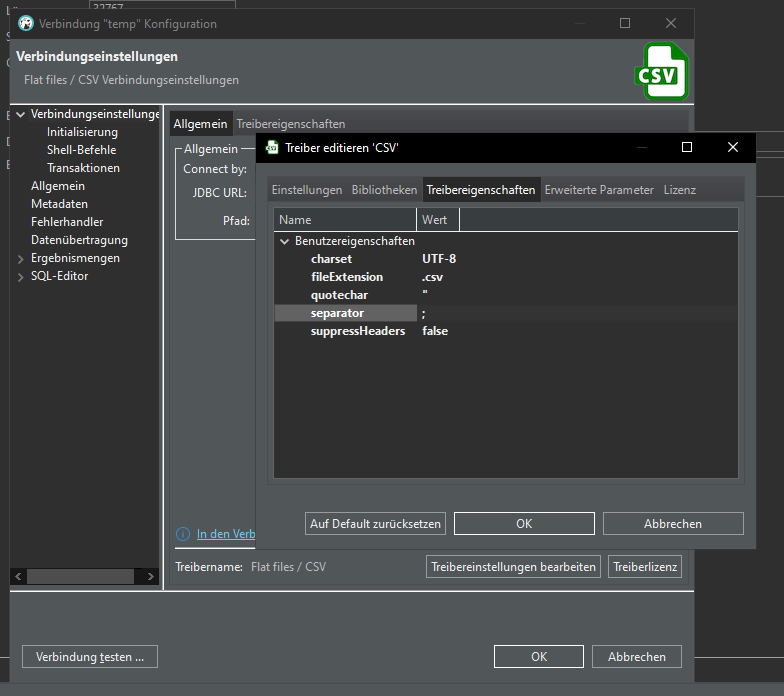
Change delimiter (Spaltentrennzeichen) from , to ;
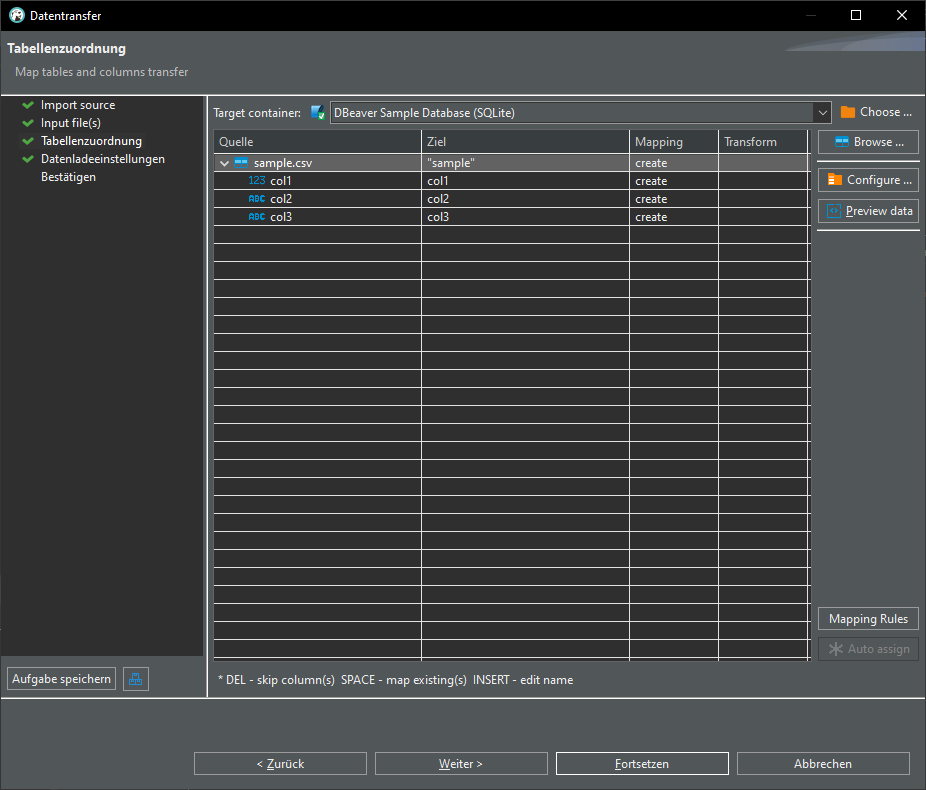
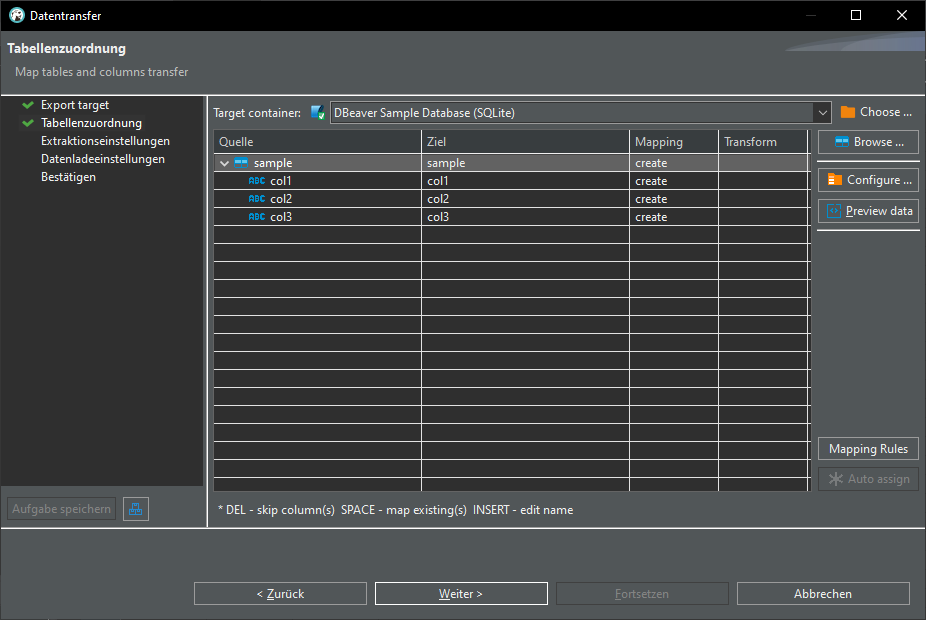
click "Auto assign", change target to "sample"
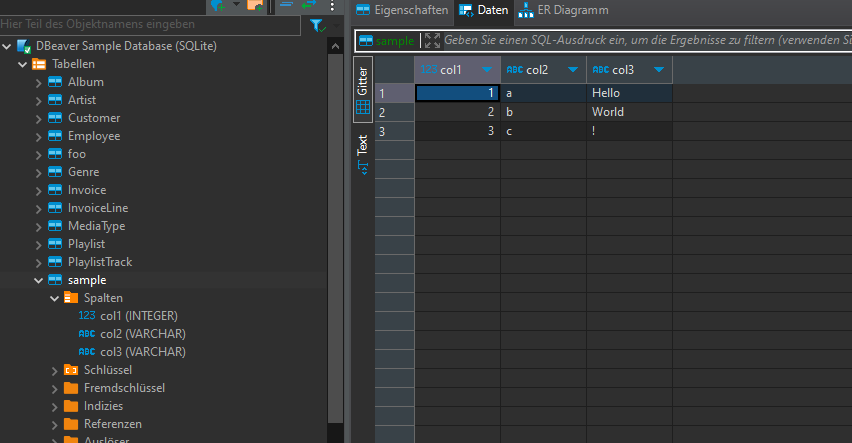
TADA! We have a new table "sample" in our database:
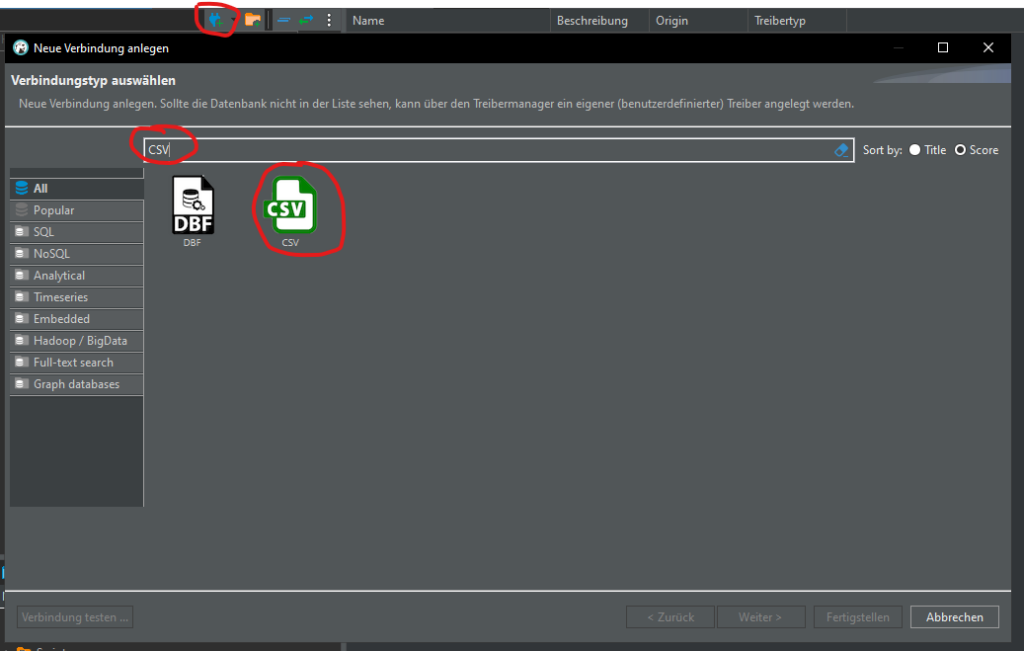
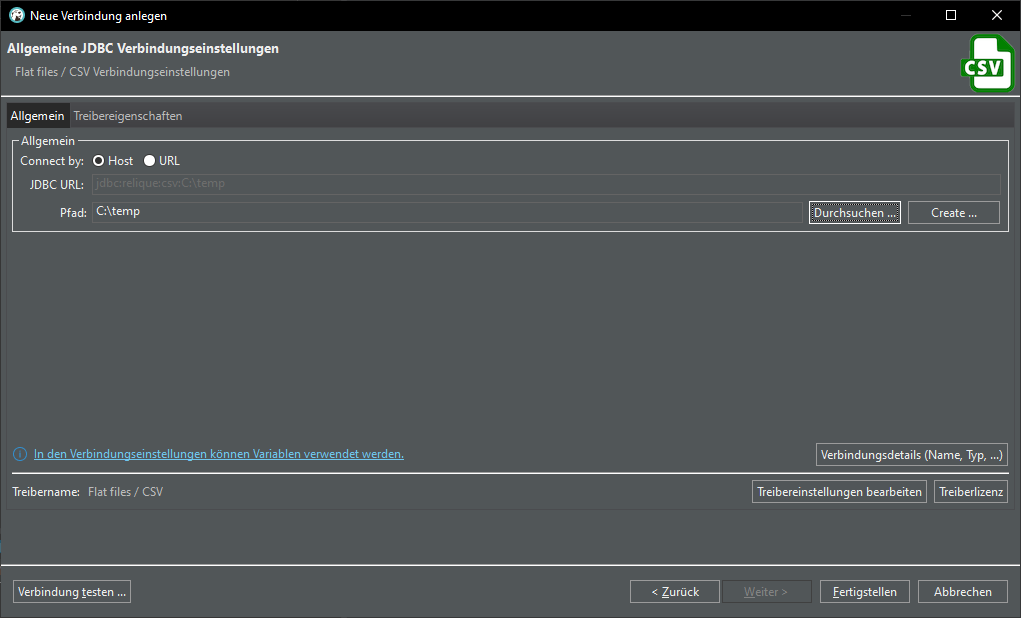
Create CSV connection
Let's try another way. Delete table "sample" and create a connection to the CSV file:
Click Browse… and select the folder where your csv file is that you saved from Excel. You’re selecting a folder here, not a file. The connection will load ALL csv files in that folder. Click Finish.
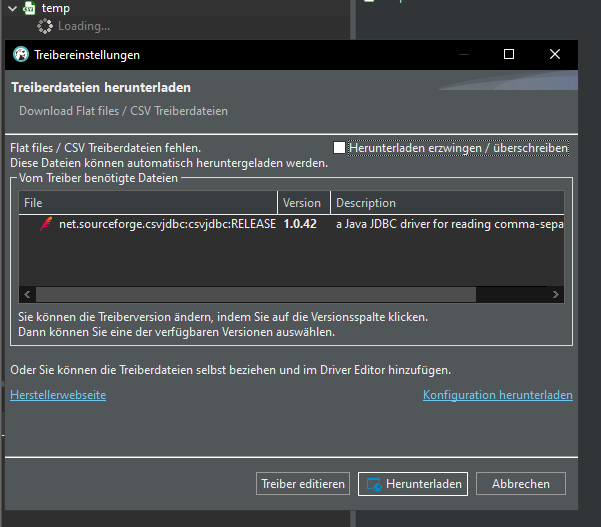
Download the driver, if using for the very first time:
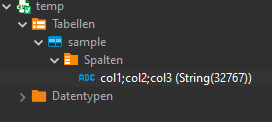
You will now see a new connection; this connection is set up exactly like a regular connection. Each csv file in your folder will be set up as a table with columns.
But there is a problem with the columns, it's just one, not three:
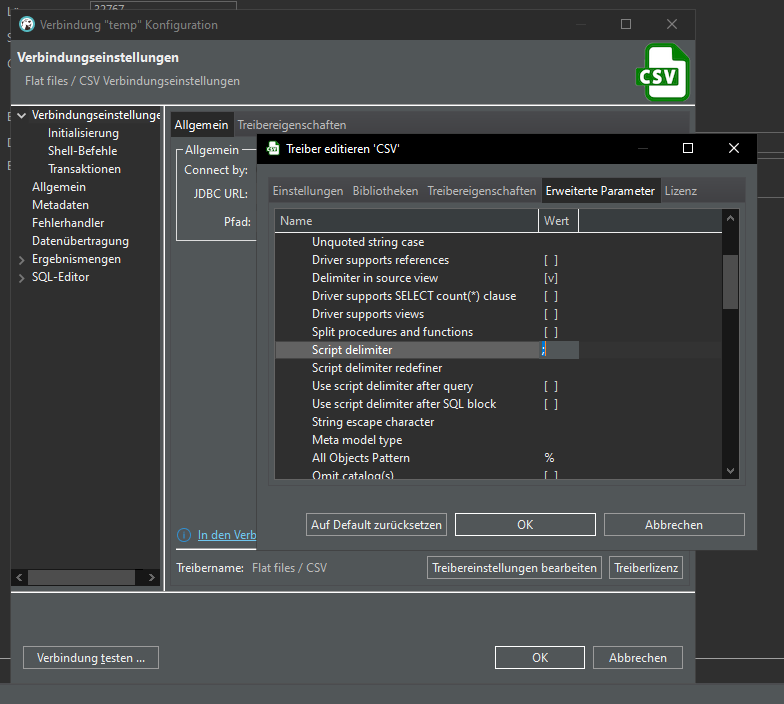
Doublecheck delimiter, but it is already set to ;
Ah, in driver details we have to set the separator from , to ;
Looks better now:
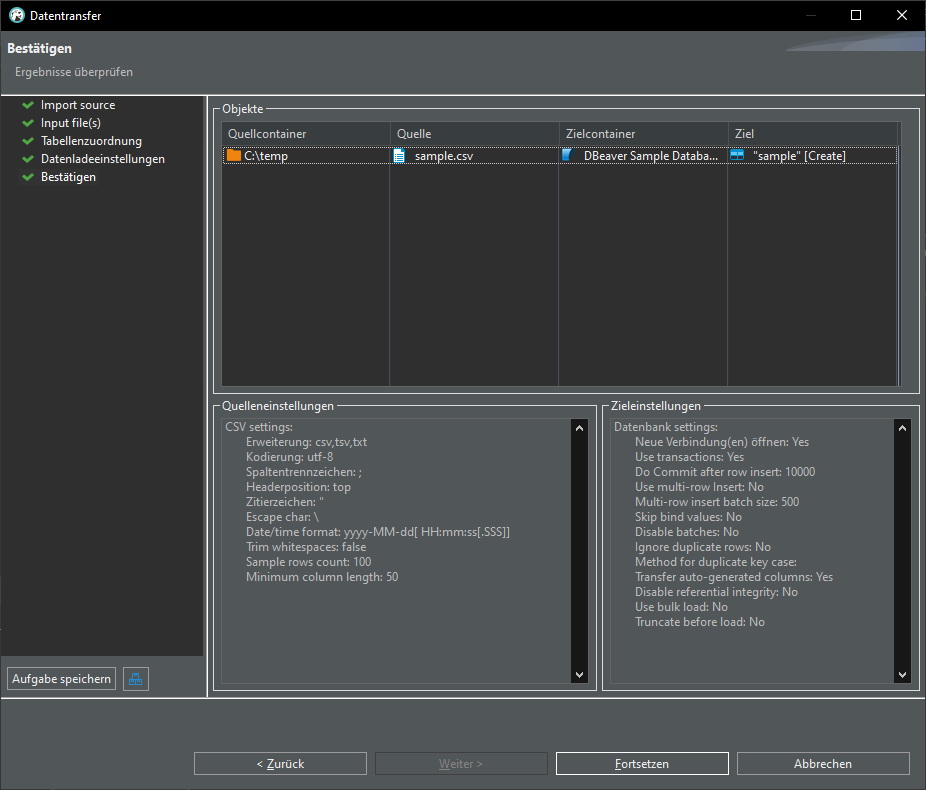
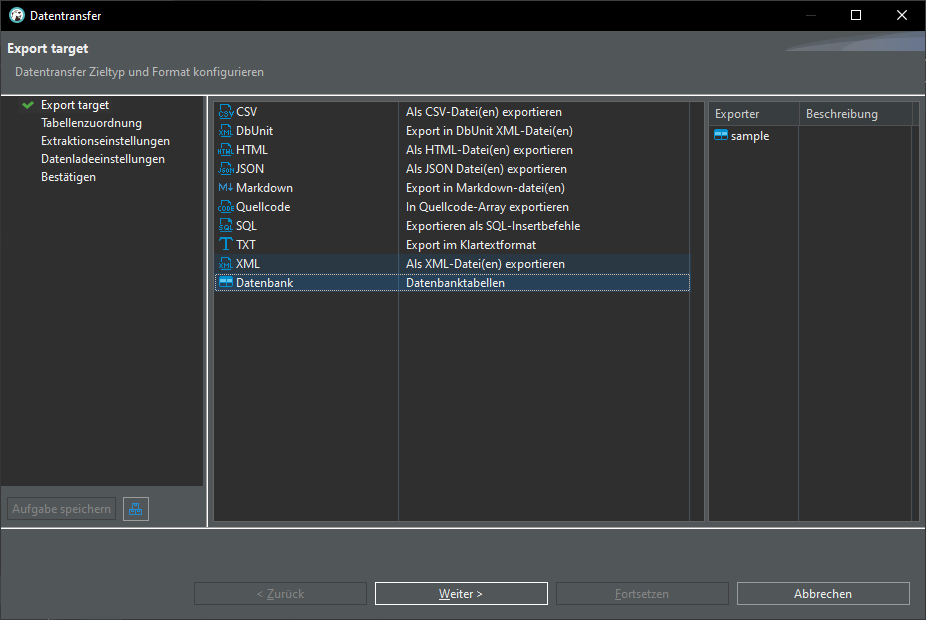
Export CSV data into database:
Once again we have our sample table in our database:
Die Sourcen des DBFSample finden sich wie immer im GitHub.
Das DBFSample ist ein PoC um eine DBF Datei mit Java verarbeiten zu können.
Im Projekt haben wir einige DBF Dateien erhalten, deren Daten wir importieren/verarbeiten müssen. Das soll nicht meine Aufgabe sein, aber ich möchte für den Fall vorbereitet sein, dass ich dabei unterstützen darf.
Ich brauche also erstmal nur verstehen, was eine DBF Datei ist und wie ich grundlegend damit arbeiten kann.
Was ist eine DBF Datei
Eine DBF-Datei ist eine Standarddatenbankdatei, die von dBASE, einer Datenbankverwaltungssystemanwendung, verwendet wird. Es organisiert Daten in mehreren Datensätzen mit Feldern, die in einem Array-Datentyp gespeichert sind.
Aufgrund der frühzeitigen Einführung in der Datenbank und einer relativ einfachen Dateistruktur wurden DBF-Dateien allgemein als Standardspeicherformat für strukturierte Daten in kommerziellen Anwendungen akzeptiert.
https://datei.wiki/extension/dbf
Wie kann ich eine DBF Datei öffnen?
DBeaver
Da es sich um ein Datenbankformat handelt und ich grade das Tool DBeaver in meinen Arbeitsalltag eingeführt habe, lag es für mich nahe, die Datei mit DBeaver zu öffnen.
Dazu musste ich einen Treiber zu DBeaver hinzufügen um anschließend die Datei öffnen zu können. Ich konnte dann die Tabellenstruktur sehen, aber nicht auf die Tabelle zugreifen. Es gab eine Fehlermeldung, dass eine weitere Datei fehlen würde.
java.sql.SQLException: nl.knaw.dans.common.dbflib.CorruptedTableException: Could not find file 'C:\dev\tmp\adress.dbt' (or multiple matches for the file)
DBeaver Stack-Trace
Diese andere Datei gibt es nicht und sie ist auch nicht für den Zugriff erforderlich, wie der erfolgreiche Zugriff über die anderen Wege beweist.
Etwas ausführlicher hatte ich es im Artikel zu DBeaver geschrieben.
Excel
Excel öffnen, DBF Datei reinziehen, Daten ansehen. Fertig, so einfach kann es gehen.
Ich hatte mich allerdings durch die Bezeichnung Standarddatenbankdatei ablenken lassen, so dass ich zuerst die Wege über DBeaver und Java versucht hatte.
Java
Für den Zugriff mit Java habe ich die Bibliothek JavaDBF verwendet.
Die beiden Testklassen JavaDBFReaderTest und JavaDBFReaderWithFieldNamesTest waren schnell angepasst und eine weiter Klasse zum Auslesen aller Daten ReadItAll war dann auch problemlos möglich. Dabei ignoriere ich die Datentypen und lese einfach alles als Strings ein. Für den PoC reicht das.
DBF in PostgresDB speichern
Als Beispiel, wie ich mit den Daten weiterarbeiten kann, importiere ich sie in eine Postgres Datenbank.
Dazu lese ich zuerst die sample.dbf ein und erzeuge dann eine Tabelle sample mit allen Columns, die in sample.dbf vorhanden sind. Anschließend wird die Tabelle zeilenweise gefüllt.
Das meiste ist hardcodiert und die Spalten sind alles Text-Spalten, da ich die Datentypen aus der DBF Datei nicht auslese, aber für den PoC reicht das.
Dadurch werden die Logfiles mit dem User root geschrieben und ich kann sie mit meinem User ingo nicht lesen.
Auf der Console kann ich das leicht mit einem vorangestellten sudo lösen, aber um mal eben schnell in die Logfiles rein zu schauen würde ich gerne mein graphisches Tool WinSCP verwenden
Lösung
Man kann Docker / Docker Compose mit einem User starten und mit dem würden dann vermutlich auch die Logfiles geschrieben werden. Als ich das mit einem Tomcat Image getestet hatte, ist es daran gescheitert, dass mit meinem User ingo auf bestimmte Verzeichnisse im Container nicht zugegriffen werden konnte.
Gelöst habe ich es dann so, dass ich nicht den User, oder User und Gruppe, gesetzt habe, sondern nur die Gruppe. So wird mit dem root User gearbeitet, die Dateien gehören dem User root und für die gesetzte Gruppe sind sie lesbar. Mein User muss natürlich ebenfalls in der Gruppe sein.
Gruppe anlegen:
sudo groupadd -g 1001 logfilegroup
Die Group ID ist relativ willkürlich gesetzt. Eigentlich hatte ich groupadd ohne das -g Flag aufgerufen und dann mit cat /etc/group die Group ID rausgesucht. Hier wollte ich das Statement mit explizitem setzen der Group ID hinschreiben, da ich es auch im Projekt verwendet hatte, um auf jedem Server die selbe Group ID zu haben.
User der Gruppe hinzufügen:
sudo usermod --append --groups logfilegroup ingo
Mit den Befehlen groups oder id kann man die Gruppen seines Users sehen, die neue logfilegroup wird aber erst in einer neuen Shell hinzugefügt. Also entweder die Shell schließen und neu öffnen, oder mit su ingo weiter arbeiten.
ingo$ sudo usermod --append --groups logfilegroup ingo
ingo$ groups
ingo adm
ingo$ su ingo
Password:
ingo$ groups
ingo adm logfilegroup
Docker Compose File:
Im Docker Compose File muss die Group ID gesetzt werden, mit dem Namen der Gruppe geht es nicht.
Bisher hatte ich auf meine Postgres Datenbank per PG-Admin zugegriffen.
Ein Kollege hat mir heute DBeaver als Datenbanktool empfohlen.
Installation
Die Installation der DBeaver Community Version war in meinem Fall einfach das ZIP-File herunterladen, und nach C:\Program Files\dbeaver entpacken.
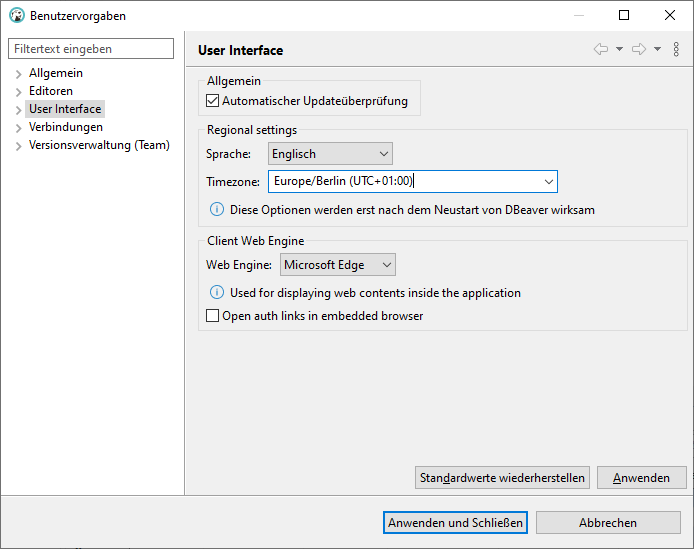
DBeaver erscheint in deutscher Lokalisation. Da aber die meisten Artikel über DBeaver auf Englisch sind, stelle ich auf Englisch um. Dazu auf Fenster -> Einstellungen gehen und im User Interface die Regional settings anpassen:
Im Unterpunkt User Interface -> Appearance stelle ich testweise das Theme auf Dark.
Meine Postgres Datenbank konnte ich mit den Verbindungsparametern anbinden, benötigte Treiber konnte DBeaver selbst nachladen.
CSV Export
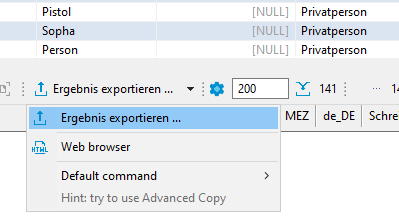
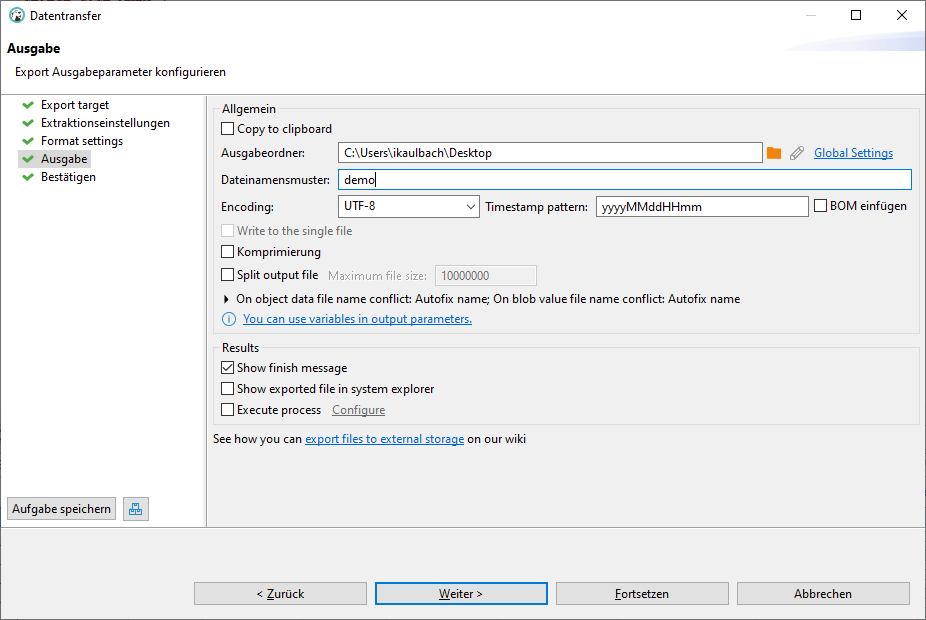
Für den CSV Export im Result-Tab auf "Ergebnis exportieren" klicken:
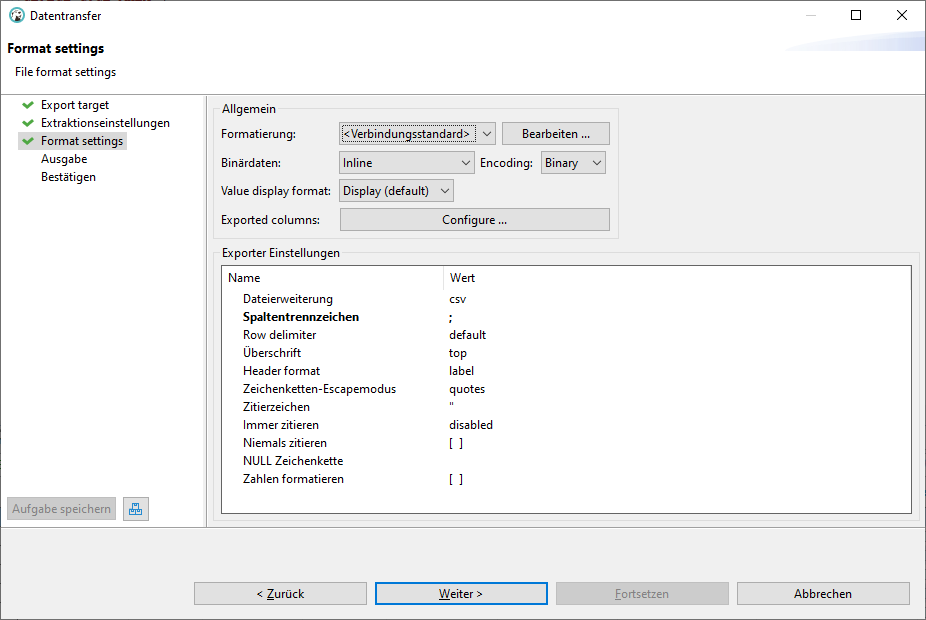
In den Format settings noch das Spaltentrennzeichen auf ";" für mein deutsches Excel ändern:
Im Ausgabetab den Ausgabeordner und Dateinamen, ohne Endung .csv, eingeben, Encoding auf UTF-8 belassen:
Trotz UTF-8 zeigt Excel die Umlaute nicht richtig an:
Die Ursache / Lösung konnte ich auf die Schnelle nicht finden. Zum Glück ist das grade nicht so wichtig, daher kann ich die Recherche vertragen.
dBase
Ich habe eine .dbf-Datei erhalten. Dabei handelt es sich anscheinend um einen dBase-Datenbank-Export. Diese Datei/Datenbank möchte ich mir mit DBeaver ansehen.
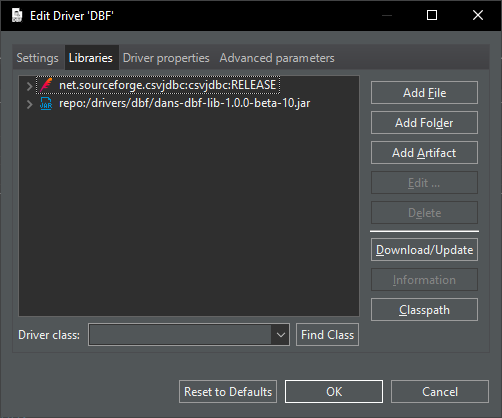
Dazu muss ich zuerst einen JDBC-Driver herunterladen. Nach kurzer Suche habe ich dieses Maven-Dependency gefunden, die ich in mein Maven Repository herunterlade:
download dans-dbf-lib-1.0.0-beta-10.jar (e.g. from sourceforge)
in Drivers location, Local folder (in Windows: C:\Users\user\AppData\Roaming\DBeaverData\drivers) create the \drivers\dbf directory. NB 'drivers' must be created under drivers, so ...\DBeaverData\drivers\drivers\...
put dans-dbf-lib-1.0.0-beta-10.jar in this folder
now you can create a new connection using the Embedded/DBF driver
Connection anlegen:
Im Database Navigator:
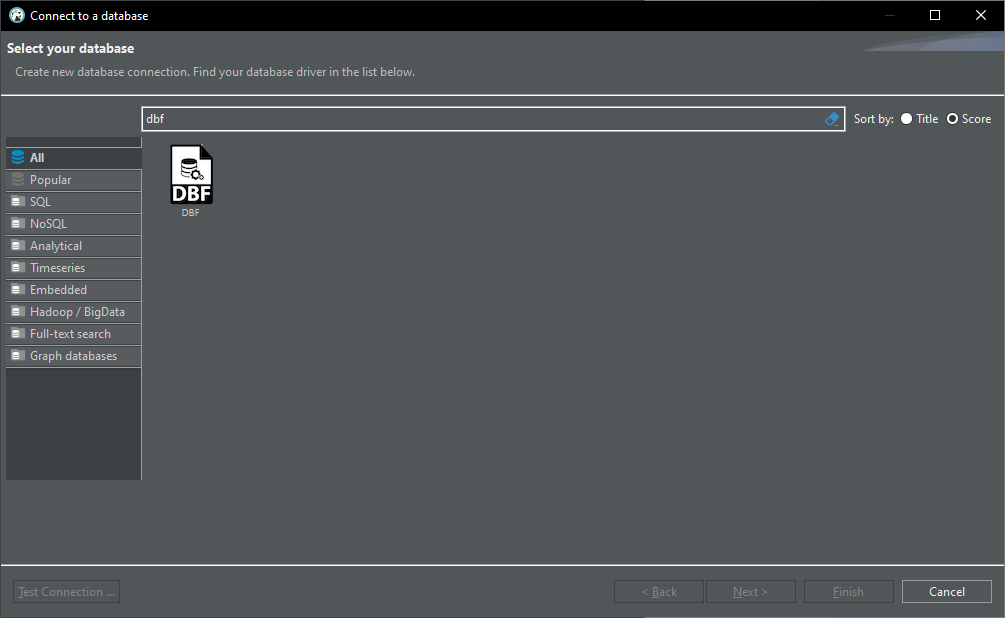
DBF Database auswählen:
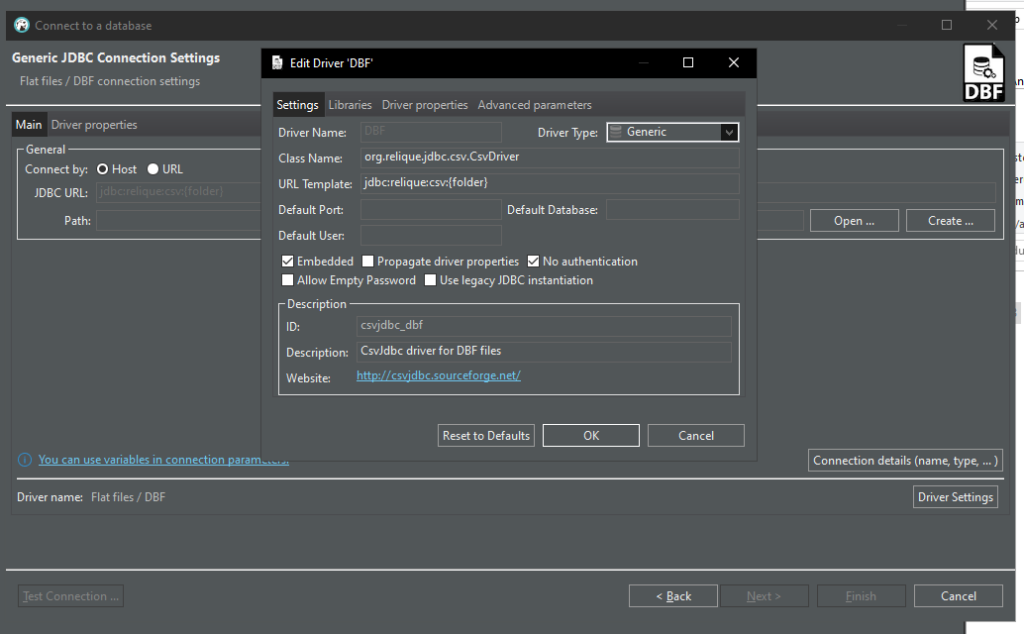
Wenn ich dann aber in die Treiber Details schaue, sieht es nicht so aus, als ob das DANS DBF Driver ist:
Andererseits erscheint das jar dann doch bei den Libraries, also sollte das doch richtig sein?
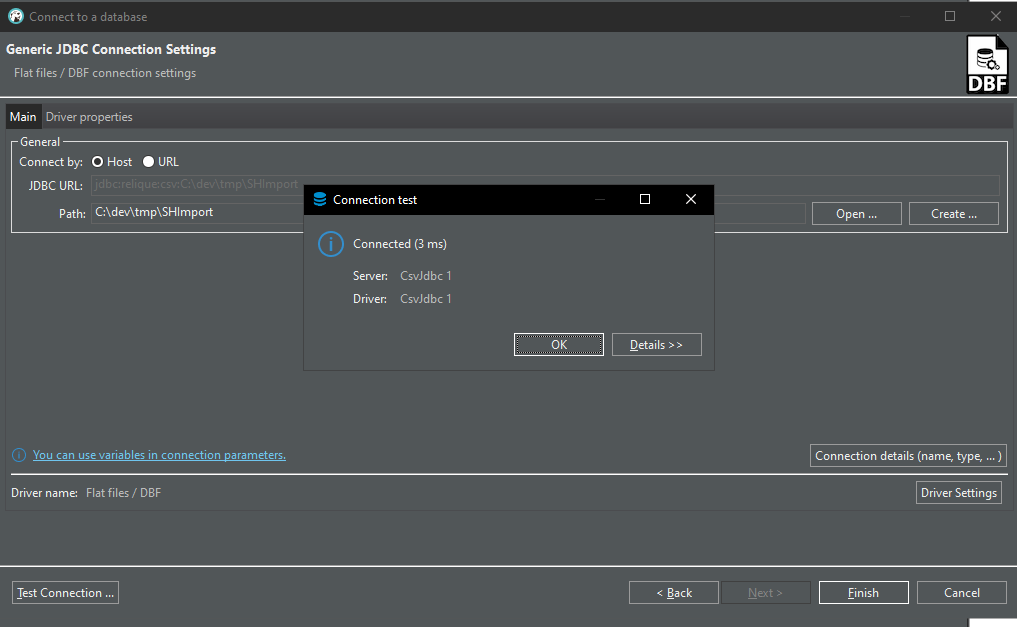
Ich gebe den Pfad zum Ordner mit der .dbf Datei an und rufe Test Connection auf, was sogar funktioniert:
Mit Finish beenden.
Im Database Navigator erscheint die ".dbf Datenbank" und ich kann die enthaltene Tabelle mit ihren Spalten erkennen. Wenn ich dann allerdings View Data auf der Tabelle aufrufe gibt es eine Fehlermeldung:
SQL Error: nl.knaw.dans.common.dbflib.CorruptedTableException: Could not find file 'C:\dev\tmp\SHImport\adress.dbt' (or multiple matches for the file)
Möglicherweise habe ich keinen ordentlichen Export bekommen?
Ich werde dem nachgehen und wenn es noch relevante Informationen zum DBeaver Import geben sollte werde ich diese hier anfügen.
Die Sourcen des JEXIEPORTER finden sich wie immer im GitHub.
Der JEXIEPORTER ist ein PoC um Java Objekt in XML oder JSON Strings zu transformieren und aus den XML/JSON-Strings wieder Java Objekte zu transformieren. Außerdem um CSV-Dateien sowie Excel- und ODF/ODS-Dateien zu lesen und zu schreiben.
Der JEXIEPORTER führt folgende Schritte durch:
import sampledata.csv
convert data to xml
convert data to json
convert xml to objects
convert json to objects
export data as CSV to a temporary file and opens system csv-viewer
export data as xls to a temporary file and opens system xls-viewer
import temporary xlx file
Beispieldaten
Die Beispieldaten sampledata.csv habe ich auf GenerateData generieren lassen und habe dann die trennenden Komma durch Semikolon ersetzt.
Ich möchte ein Programm aus dem Internet testen und es dazu in einer abgeschotteten Umgebung laufen lassen, damit alles, was das Programm in dieser Sandbox anstellt keinerlei Auswirkungen auf das umgebende System hat.
Vor vielen Jahren hatte ich schon einmal das Programm Sandboxie verwendet, um einen Browser in einer isolierten Umgebung laufen zu lassen.
Eine andere Alternative wäre es, ein virtuelles System mittels VMware oder VirtualBox aufzusetzen und Windows zu installieren, bzw. eine virtuelle Entwickler Maschine von Microsoft zu verwenden. Das hatte ich in der Vergangenheit öfters verwendet, das funktioniert sehr gut, ist aber auch etwas aufwändiger.
Für Windows 10 und 11 Pro (bzw. Enterprise, was ich verwende) gibt es inzwischen eine einfacherer Alternative: Die Windows Sandbox, die direkt in das Betriebssystem integriert ist. Und diese Sandbox möchte ich jetzt testen.
Installation
Ich verwende Windows 10 Enterprise und die Virtualisierungsfunktionen im BIOS sind aktiviert.
Um Sandbox mit PowerShell zu aktivieren, öffnen ich PowerShell als Administrator, und führe den folgenden Befehl aus:
Anschließend ist ein Neustart erforderlich, um den Vorgang abzuschließen.
Nach dem Neustart ist die Windows-Sandbox im Startmenü zu finden:
Verwendung
Aus dem Startmenü heraus Windows Sandbox starten:
Per Copy&Paste lassen sich Dateien vom Host in das Sandbox Fenster kopieren. Per Drag&Drop funktioniert es leider nicht. Alternativ lassen sich die benötigten Dateien auch innerhalb der Sandbox herunterladen, so wie im nachfolgenden Beispiel.
Test
In der Sandbox den Browser öffnen, die zu installierende Software suchen und herunterladen. In meinem Test wird es der foxit PDF Editor sein.
Ich entscheide mich für die Version: PDF EDITOR PRO 13
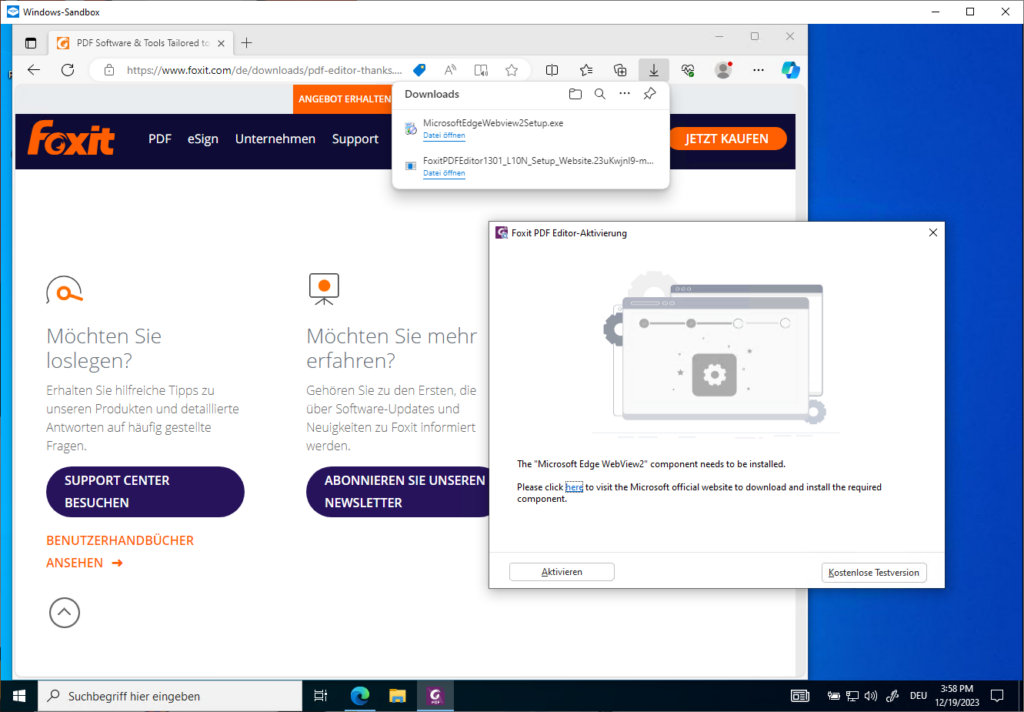
Nach dem Herunterladen und Installieren wird noch eine "Microsoft Edge WebView2" Komponente benötigt. Diese lässt sich bequem innerhalb der Sandbox installieren.
Sobald die Komponente installiert ist lässt sich der PDF Editor in der kostenlosen Testversion starten.
Ich teste den PDF Editor. [TODO nächster Post]
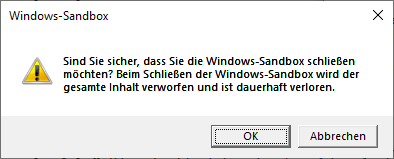
Nach Abschluss der Test kann ich die Sandbox wieder schließen. Dabei gehen alle Daten verloren, so dass beim nächsten Start der Sandbox wieder ein frisches System zur Verfügung steht.
Fazit
Die Windows Sandbox ist ein tolles, leicht zu bedienendes Tool, um schnell Software oder dubiose Webseiten zu testen.
Dass am Ende immer alle Daten gelöscht werden hat den Vorteil, dass man beim nächsten Start mit einem frischen System neu starten kann. Aber es ist auf der anderen Seite auch ein Nachteil, dass man keine Software dauerhaft speichern kann, um sie bei der nächsten Verwendung wieder verwenden zu können. Beispielsweise wenn ich einen bestimmten Browser mit ausgewählten Erweiterungen verwenden möchte.
Ich weiß nicht mehr ganz genau, wie das mit Sandboxie war, soweit ich mich erinnern kann, wurde zB der Browser in Sandboxie installiert und und konnte dann direkt aufgerufen werden, wie eine normale Anwendung. Ob die Einstellungen, Browserverlauf etc. gespeichert wurden weiß ich nicht mehr.
Mit einer richtigen virtuellen Maschine ist man flexibler: Windows und Lieblingssoftware installieren und einrichten, VM herunterfahren und dann die virtuelle Festplatte auf nicht persistent stellen. Dann startet man immer mit seiner eigenen vorkonfigurierten Umgebung, kann ebenfalls nach herzenslust testen und nach einem Neustart ist alles wieder frisch. In der Praxis ist das aber nicht immer ganz so unproblematisch: Es gibt immer wieder neue Windows und Software Updates, die dann nach einem Neustart im Hintergrund gezogen und ggf. sogar installiert werden. Das kann man sicherlich auch anders konfigurieren, ist aber wieder weiterer Aufwand. Oder man startet regelmäßig neu, nachdem man die virtuelle Festplatte auf persistent umgestellt hat, installiert alle Updates, fährt herunter und dann wieder die virtuelle Festplatte auf nicht persistent umstellen. Wenn man aber nur alle paar Monate die VM verwenden möchte, ist man uU genausolange mit updaten beschäftigt, wie man sie für das Testen verwenden möchte. Da ist dann die Windows Sandbox doch schneller und unkomplizierter.
Nachdem ich mich vor ca. zwei Jahren mal mit Redis auseinander gesetzt hatte, hat es sich jetzt ergeben, ein Beispielsetup in der Praxis umzusetzen.
Eine Anwendung, die auf einem Tomcat Server läuft, soll vorbereitet werden skalierbar gemacht zu werden. Dazu wird im ersten Schritt Redis als Session Cache für den Tomcat eingebunden und ein zweiter Tomcat daneben gestellt, der ebenfalls auf den Redis Session Cache zugreift. Zur Lastverteilung wird ein Reverse Proxy vor die beiden Tomcats gestellt.
Die Server laufen alle in Docker Containern und werden über eine Docker-Compose Datei gesteuert.
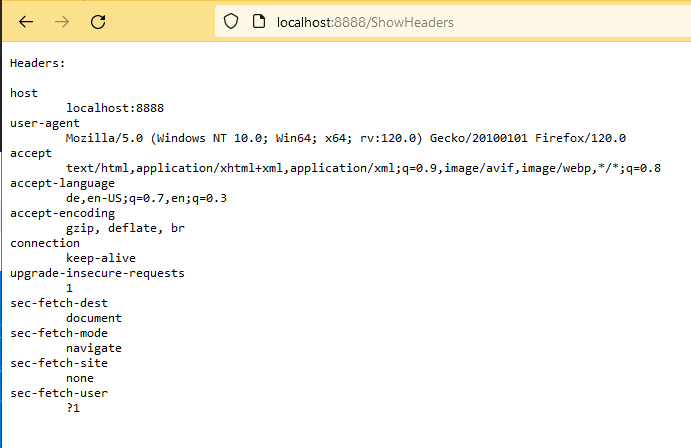
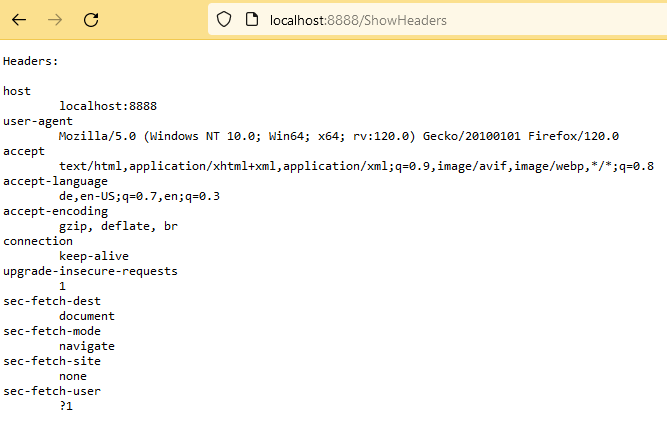
Als Beispielanwendung für dieses Projekt kommt mal wieder Show Headers zum Einsatz.
Für die Verbindung von Tomcat zu Redis wird Redisson verwendet.
Step 1
context.xml von einem Tomcat 9 in das tomcat Verzeichnis kopieren und den RedissonSessionManager einrichten:
<Context>
<!-- Default set of monitored resources. If one of these changes, the -->
<!-- web application will be reloaded. -->
<WatchedResource>WEB-INF/web.xml</WatchedResource>
<WatchedResource>WEB-INF/tomcat-web.xml</WatchedResource>
<WatchedResource>${catalina.base}/conf/web.xml</WatchedResource>
<!-- Redis Session Manager -->
<!-- https://redisson.org/articles/redis-based-tomcat-session-management.html -->
<Manager className="org.redisson.tomcat.RedissonSessionManager"
configPath="${catalina.base}/conf/redisson.yaml"
readMode="MEMORY"
updateMode="DEFAULT"/>
</Context>
Die beiden Redisson Dateien von Redisson herunterladen und ebenfalls in das tomcat Verzeichnis kopieren.
Step 3
Es muss ein neues Tomcat Image inklusive Redisson gebaut werden, dazu ein neues Dockerfile im tomcat Ordner anlegen:
# https://hub.docker.com/_/tomcat
FROM tomcat:9.0.83-jre21
# Add Redis session manager dependencies
COPY ./redisson-all-3.22.0.jar $CATALINA_HOME/lib/
COPY ./redisson-tomcat-9-3.22.0.jar $CATALINA_HOME/lib/
# Replace the default Tomcat context.xml with custom context.xml
COPY ./context.xml $CATALINA_HOME/conf/
# Add Redisson configuration
COPY ./redisson.yaml $CATALINA_HOME/conf/
# Expose the port Tomcat will run on
EXPOSE 8080
# Start Tomcat
CMD ["catalina.sh", "run"]
Anstelle des image Eintrags in der docker-compose den build Eintrag setzen: "build: ./tomcat"
Testen
Erneut starten:
docker-compose up --detach
Und es läuft immer noch im Browser:
Redis
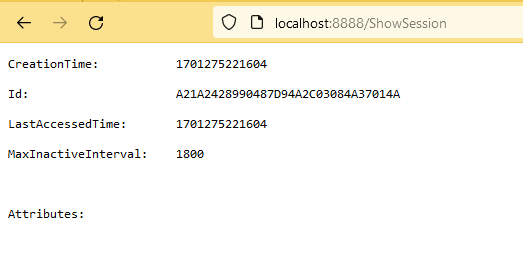
So weit so gut, aber wird auch wirklich der Redis Cache verwendet? Nein, denn bisher wurde noch gar keine Session erzeugt. Holen wir das nach, indem wir ShowSession aufrufen:
Schauen wir in der Redis Datenbank nach, indem wir uns zuerst in den Container connecten:
docker exec -it tomcatredissample-redis-1 bash
Dort die redis-cli starten und die Keys aller Einträge zeigen lassen mittels "keys *":
Dort ist ein Eintrag mit der Session ID aus meinem Browser zu finden. Es funktioniert!
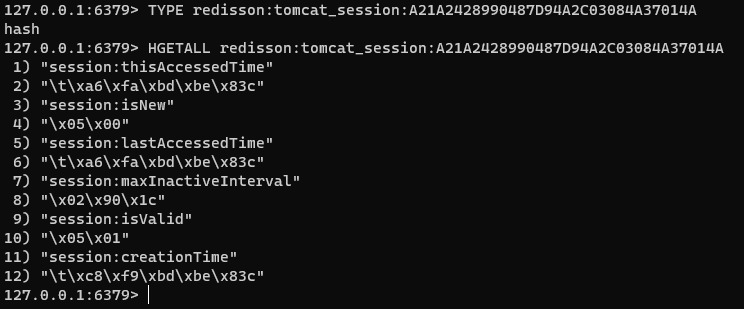
Welche Daten stehen in der Session? Um die Daten auslesen zu können, müssen wir erst den Datentyp mittels "TYPE" herausfinden, in diesem Fall ein "hash" und dann mit "HGETALL" anzeigen lassen:
Die seltsamen oder unlesbaren Informationen, die man sieht, wie z.B. "\t\xa6\xfa\xbd\xbe\x83c" für "session:thisAccessedTime", sind wahrscheinlich auf die Art und Weise zurückzuführen, wie Sitzungsdaten serialisiert werden, bevor sie in Redis gespeichert werden. Viele auf Java basierende Systeme, einschließlich solcher, die Tomcat für die Sitzungsverwaltung verwenden, serialisieren Objekte in ein binäres Format, bevor sie in einem Sitzungsspeicher wie Redis gespeichert werden. Diese binären Daten sind nicht direkt lesbar, wenn Sie sie mit Redis-Befehlen abrufen.
Um diese Daten zu interpretieren, müssen sie in ein lesbares Format deserialisiert werden. Darauf gehe ich hier aber nicht weiter ein.
Reverse Proxy
Der Reverse Proxy basiert auf Apache HTTPD 2.4 und wird der docker-compose Datei hinzugefügt.
Die httpd.conf Datei aus dem Container wird in den reverseproxy Ordner kopiert und am Ende erweitert:
Der anschließende Aufruf von http://localhost:8888/ShowSession funktioniert immer noch, Test bestanden.
Load Balancer
Im nächsten Schritt fügen wir einen Load Balancer hinzu, der erstmal auf genau den einen Tomcat "loadbalanced". Nach erfolgreichem Test wissen wir dann, dass der Load Balancer generell funktioniert und können dann weitere Server hinzufügen. Die erweiterte Apache Konfiguration:
Die einfachste Möglichkeit, mehrere Tomcat Server zu erzeugen, ist im Docker Compose weitere Replicas zu starten.
Docker Compose managed dann auch das Load Balancing, so dass alle Tomcat Instanzen über den Service Namen "tomcat" ansprechbar sind.
Wir haben damit ein doppeltes Load Balancing: Zuerst der Apache HTTPD der immer auf den "tomcat" loadbalanced und dann das wirkliche Load Balancing durch Docker auf die Replikas.
Jetzt die Variante ohne Replikas und mit zwei dedizierten Tomcat Servern. Die Zuteilung zum Server erfolgt beim Sessionaufbau sticky, aber wir können über Manipulation des Session Cookies den Server wechseln und so gezielt ansteuern.
In Docker Compose legen wir zwei Tomcat Server an:
Ggf. Session Cookies im Browser löschen, dann http://localhost:8888/ShowServer bzw. http://localhost:8888/ShowHeaders aufrufen. Man kann erkennen, dass bei jedem Aufruf der Server gewechselt wird.
Beim erstmaligen Aufruf von http://localhost:8888/ShowSession wird die Session erzeugt und man wird einem Server zugewiesen.
Man kann sehen, dass die Session ID ein Postfix ".tomcat-1" bzw. ".tomcat-2" hat.
Man kann im Browser den Session Cookie editieren und den Postfix auf den anderen Server ändern, zb von "SESSIONID.tomcat-1" auf "SESSIONID.tomcat-2". Dadurch kann man dann den Server auswählen, auf den man gelangen möchte. Eigentlich zumindest, denn leider hat es nicht funktioniert.
Entweder muss noch irgendwo irgendwas konfiguriert werden, oder es könnte auch ein Bug in Redisson sein: Der Postfix wird als Teil der Session ID durch Redisson in Redis als Key gespeichert. Wenn man nun also lediglich den Postfix verändert, hat man eine ungültige Session ID und es wird eine neue Session generiert. Und so kann es irgendwie passieren, dass man wieder auf dem ursprünglichen Server landet, mit einer neuen Session. Es könnte auch am Reverse Proxy liegen, dass dort der Postfix abgeschnitten werden muss, bei der Kommunikation RP zu Tomcat und lediglich auf der Strecke RP zum Browser gesetzt werden muss.
Vielleicht werde ich die Ursache des Problems und deren Behebung ermitteln können, dann gibt es hier ein Update. Allerdings werde ich nicht allzuviel Energie hineinstecken können, da andere Sachen wichtiger sind, zumal die Lösung mit den Replikas und dem durch Docker bereitgestellten Load Balancing durchaus ausreichend sein sollten.