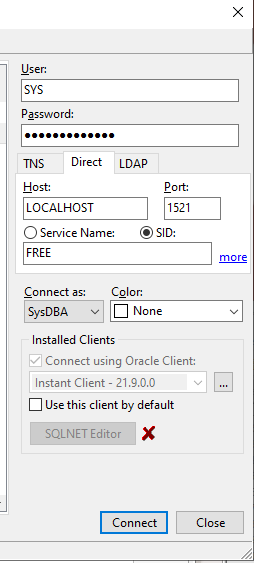
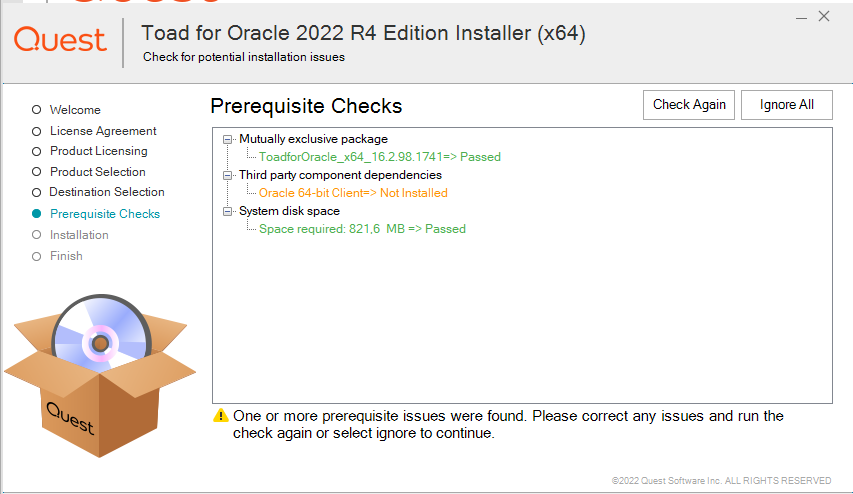
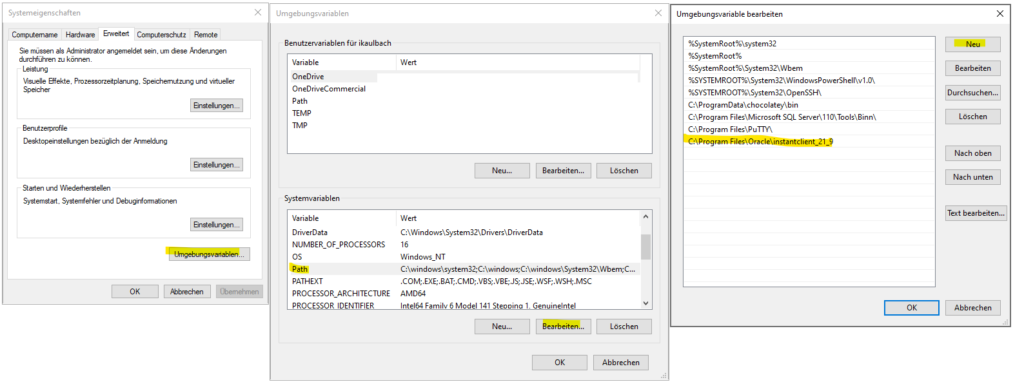
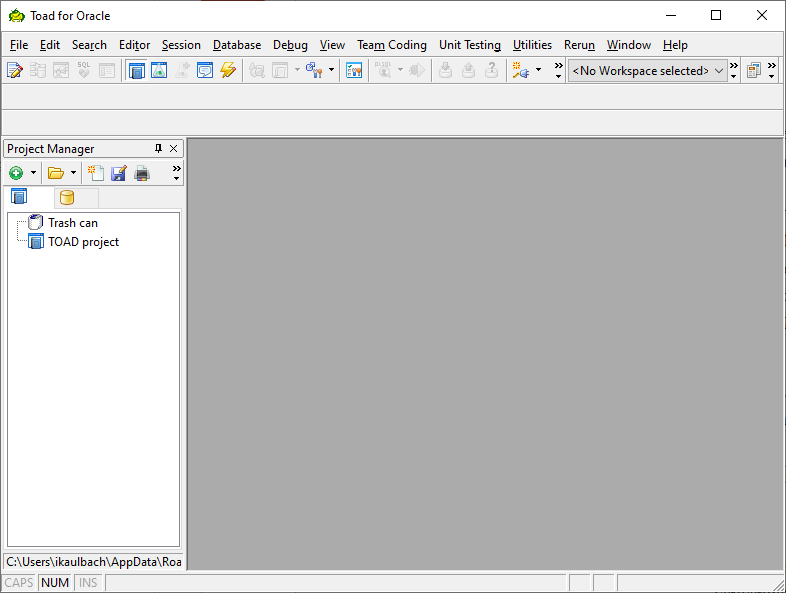
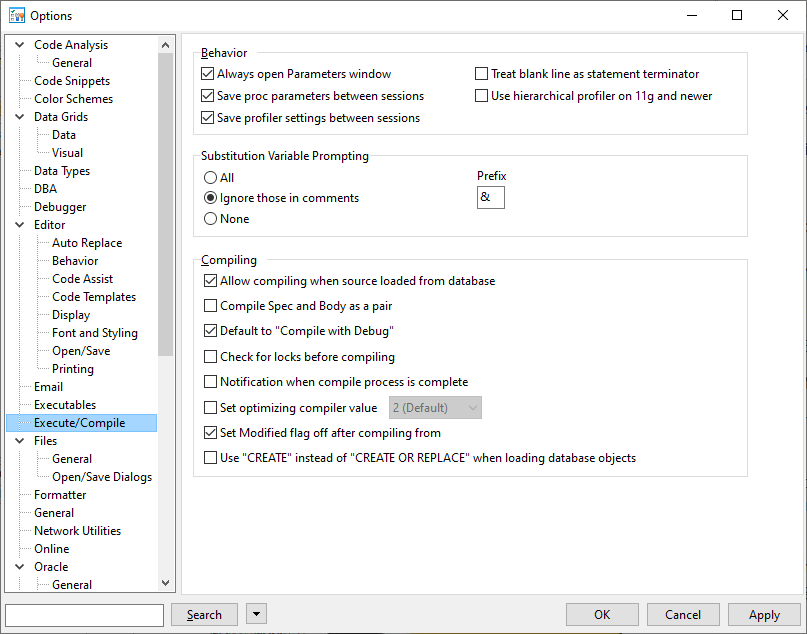
Bisher hatte ich auf meine Postgres Datenbank per PG-Admin zugegriffen.
Ein Kollege hat mir heute DBeaver als Datenbanktool empfohlen.
Installation
Die Installation der DBeaver Community Version war in meinem Fall einfach das ZIP-File herunterladen, und nach C:\Program Files\dbeaver entpacken.
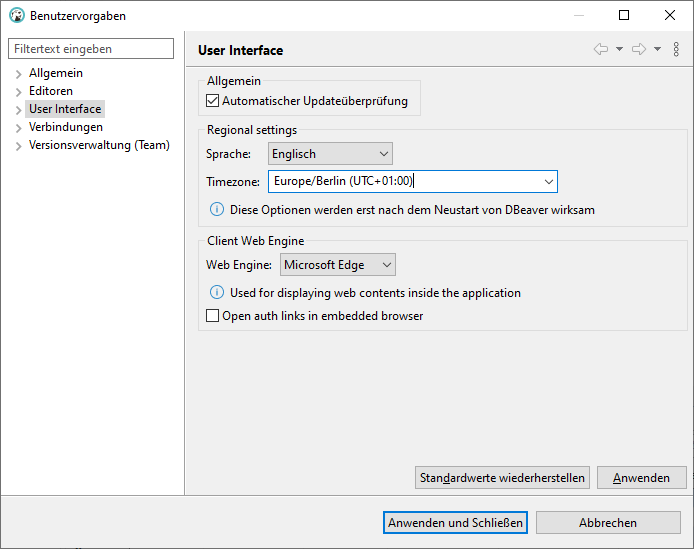
DBeaver erscheint in deutscher Lokalisation. Da aber die meisten Artikel über DBeaver auf Englisch sind, stelle ich auf Englisch um.
Dazu auf Fenster -> Einstellungen gehen und im User Interface die Regional settings anpassen:
Im Unterpunkt User Interface -> Appearance stelle ich testweise das Theme auf Dark.
Meine Postgres Datenbank konnte ich mit den Verbindungsparametern anbinden, benötigte Treiber konnte DBeaver selbst nachladen.
CSV Export
Für den CSV Export im Result-Tab auf "Ergebnis exportieren" klicken:
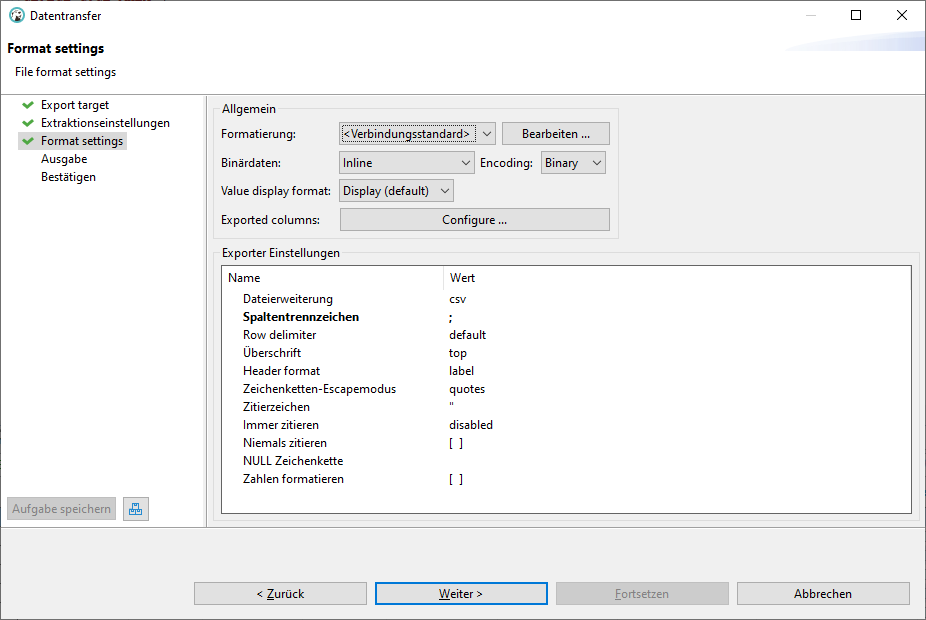
In den Format settings noch das Spaltentrennzeichen auf ";" für mein deutsches Excel ändern:
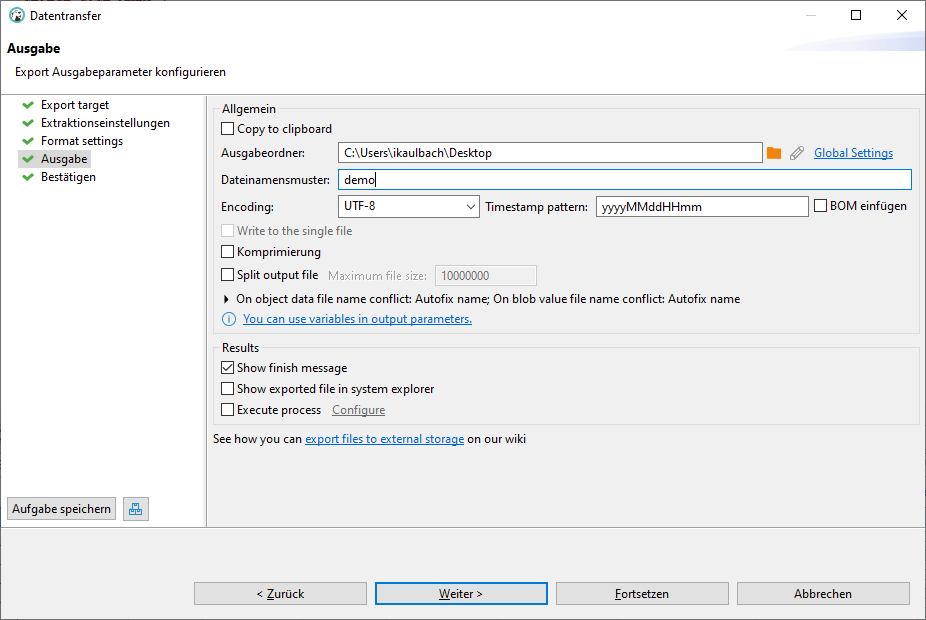
Im Ausgabetab den Ausgabeordner und Dateinamen, ohne Endung .csv, eingeben, Encoding auf UTF-8 belassen:
Trotz UTF-8 zeigt Excel die Umlaute nicht richtig an:

Die Ursache / Lösung konnte ich auf die Schnelle nicht finden. Zum Glück ist das grade nicht so wichtig, daher kann ich die Recherche vertragen.
dBase
Ich habe eine .dbf-Datei erhalten. Dabei handelt es sich anscheinend um einen dBase-Datenbank-Export. Diese Datei/Datenbank möchte ich mir mit DBeaver ansehen.
Dazu muss ich zuerst einen JDBC-Driver herunterladen. Nach kurzer Suche habe ich dieses Maven-Dependency gefunden, die ich in mein Maven Repository herunterlade:
<dependency>
<groupId>com.wisecoders</groupId>
<artifactId>dbf-jdbc-driver</artifactId>
<version>1.1.2</version>
</dependency>Um den Treiber zu DBeaver hinzuzufügen auf Database -> Driver Manager gehen:
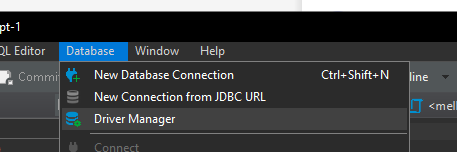
und da mir das im Driver Manager zu viele Einstellungen waren, habe ich das erstmal gelassen und erstmal einen anderen Ansatz probiert:
Ein Kommentar auf Stack Overflow beschreibt es so:
- download dans-dbf-lib-1.0.0-beta-10.jar (e.g. from sourceforge)
- in Drivers location, Local folder (in Windows: C:\Users\user\AppData\Roaming\DBeaverData\drivers) create the \drivers\dbf directory. NB 'drivers' must be created under drivers, so ...\DBeaverData\drivers\drivers\...
- put dans-dbf-lib-1.0.0-beta-10.jar in this folder
- now you can create a new connection using the Embedded/DBF driver
Connection anlegen:
Im Database Navigator:
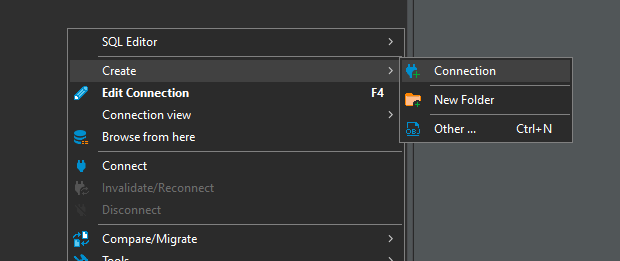
DBF Database auswählen:
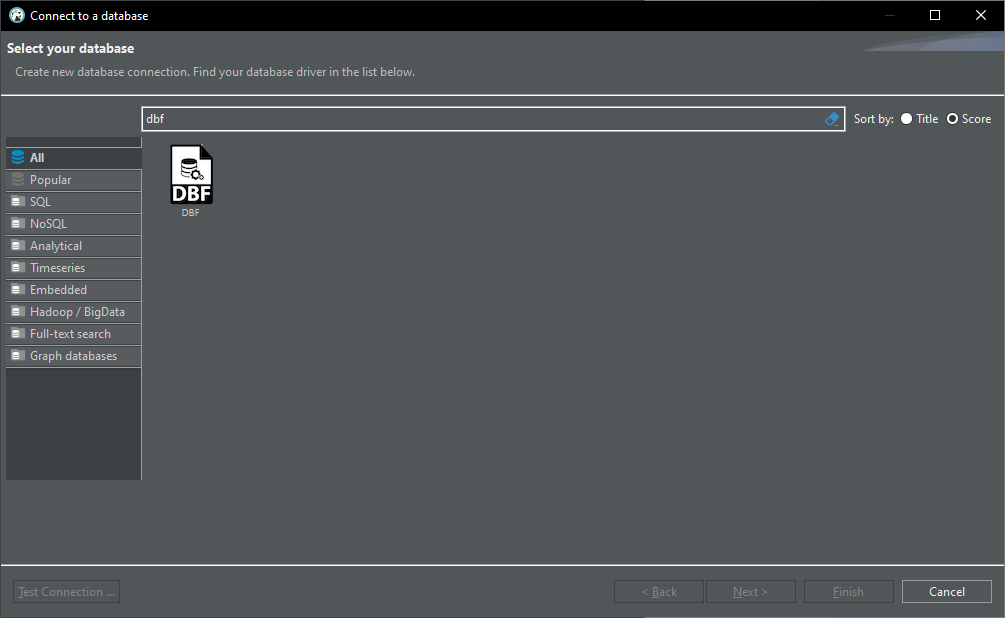
Wenn ich dann aber in die Treiber Details schaue, sieht es nicht so aus, als ob das DANS DBF Driver ist:
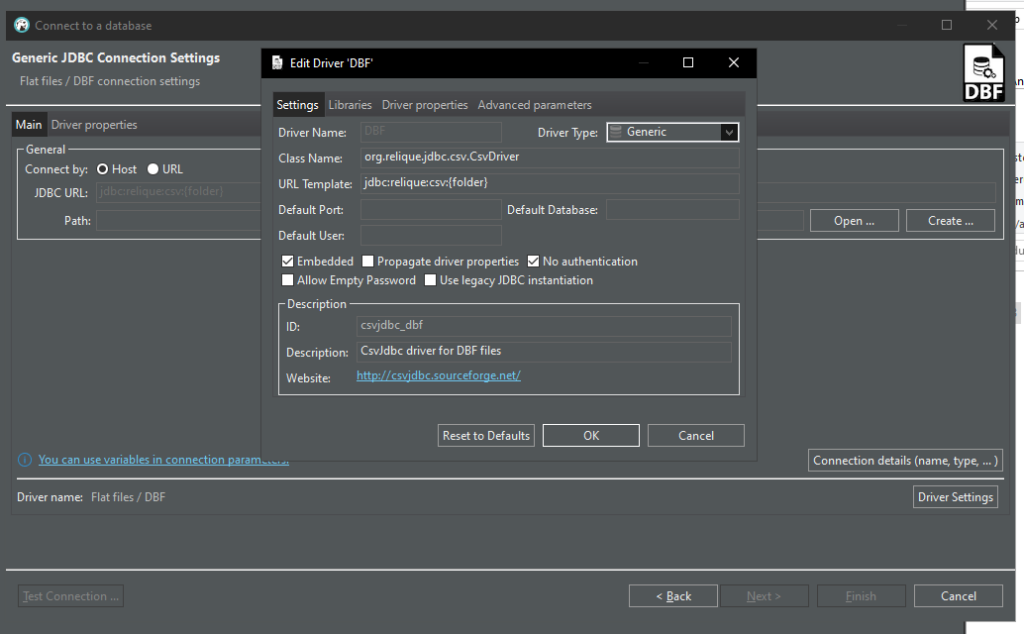
Andererseits erscheint das jar dann doch bei den Libraries, also sollte das doch richtig sein?
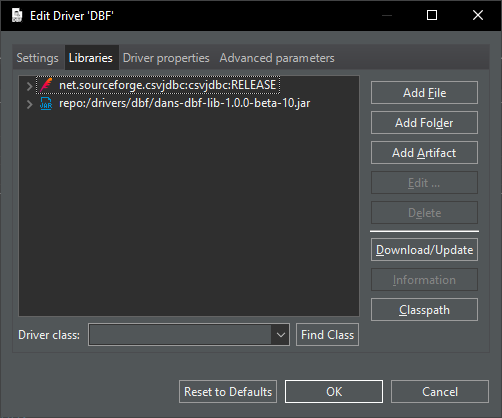
Ich gebe den Pfad zum Ordner mit der .dbf Datei an und rufe Test Connection auf, was sogar funktioniert:
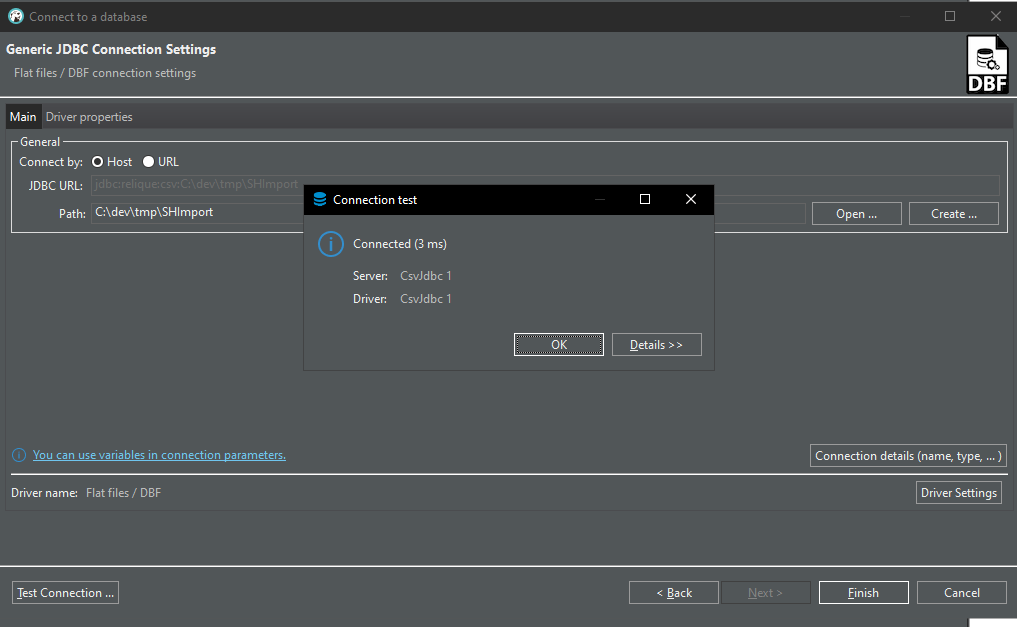
Mit Finish beenden.
Im Database Navigator erscheint die ".dbf Datenbank" und ich kann die enthaltene Tabelle mit ihren Spalten erkennen. Wenn ich dann allerdings View Data auf der Tabelle aufrufe gibt es eine Fehlermeldung:
SQL Error: nl.knaw.dans.common.dbflib.CorruptedTableException: Could not find file 'C:\dev\tmp\SHImport\adress.dbt' (or multiple matches for the file)
Möglicherweise habe ich keinen ordentlichen Export bekommen?
Ich werde dem nachgehen und wenn es noch relevante Informationen zum DBeaver Import geben sollte werde ich diese hier anfügen.