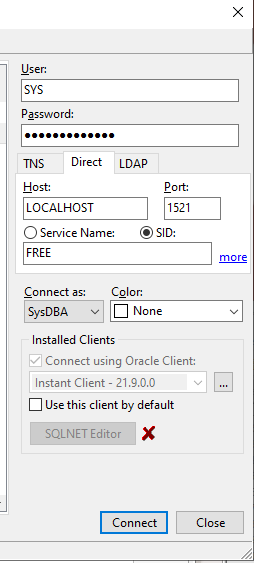
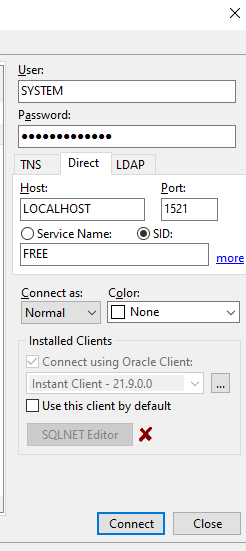
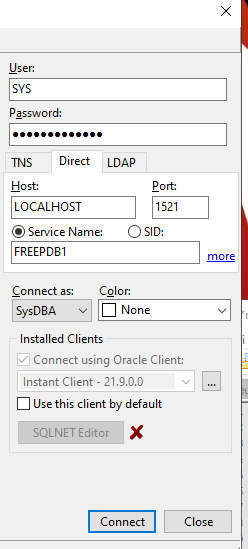
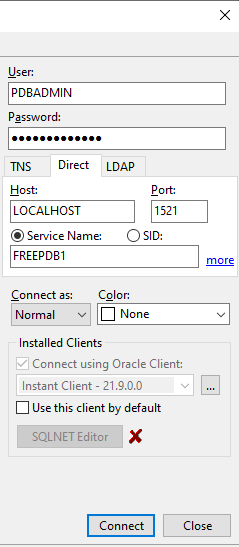
Für ein Projekt musste ich ein PDF erzeugen und habe das dann mit iText umgesetzt.
Um mich in die Technik einzuarbeiten habe ich mir ein paar Bilder von Pixabay heruntergeladen, ein Projekt auf GitHub angelegt und dann schrittweise ein PDF mit Bildern erzeugt:
Am Wochenende habe ich zum ersten Mal einen Escape Room spielen dürfen und ich muss sagen, heute habe ich mich ähnlich gefühlt, denn das Bugfixing ähnelt auch einer kreativen rätselratenden Schnitzeljagd.
Der Bug
Die von mir entwickelte Anwendung ist mittlerweile im Pilot-Betrieb und ein Benutzer meldet, dass er einen Vorgang nicht beenden kann: Vermeindlich hochgeladene Bilder, die zwingend erforderlich sind, 'verschwinden' und so kann er nicht abschließend speichern.
Die Bilder werden dankenswerterweise mitgeliefert, so dass ich auch versuchen kann, das Problem nachzustellen.
Es gibt auch einen Hinweis, das das Ausführen einer bestimmten Funktion während des Vorgangs das Problem verursacht haben könnte. ERROR-Einträge in den Logfiles unterstützen diese These, aber letztendlich hatte es damit nichts zu tun. Es war nur eine falsche Fährte, eine Ablenkung, wie bei jedem guten Spiel 😉 Und die Erkenntnis, dass da noch irgendwo ein weiterer Bug schlummert, der von mir gejagt und entdeckt werden will.
Bug reproduzieren
Als erstes versuche ich, den Bug lokal nachstellen zu können, also auf meinem Entwickler-Laptop. Das funktioniert aber nicht, da alles fehlerfrei funktioniert, incl. Upload der beiden Bilder.
Hier wäre jetzt eine gute Gelegenheit, das Ticket mit "Works on my machine" zu schließen.
Aber ich forsche weiter und versuche, das Problem auf dem Server nachzustellen. Und hier gelingt es: Die Bilder verschwinden auf magische Art und Weise. Und ohne Einträge in den Logs.
Analyse
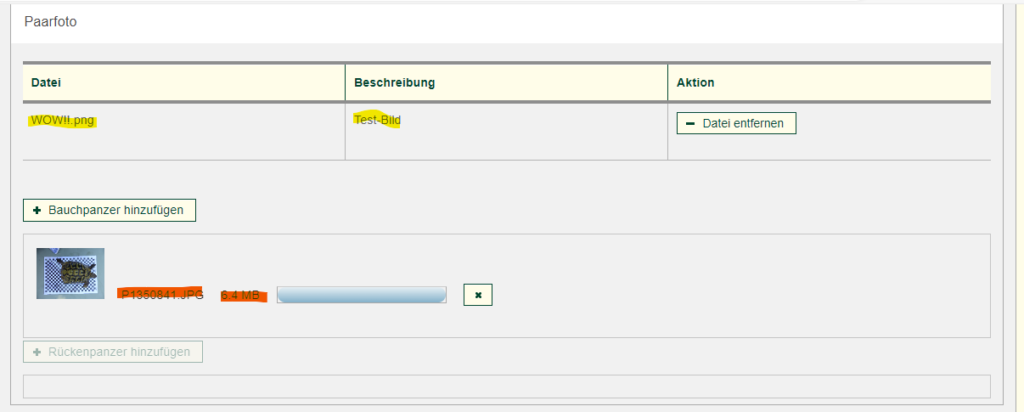
Der Vorgang durchläuft einen Wizard, und nachdem man die Bilder hochgeladen hat, kann man einen Schritt weiter. Wenn man dann einen Schritt zurück geht, sind die Bilder weg.
Mit meiner Testdatei (WOW!!.png) funktioniert es hingegen.
Auffällig ist, dass die andere Datei nicht korrekt in die Tabelle der Dateien übertragen wird, sondern ewig in der Upload-Ansicht verharrt. Es gibt aber keine Fehlermeldung. Die Datei ist 6,4 MB groß, erlaubt sind Dateigrößen bis 10 MB; bei größeren Dateien kommt auch ein entsprechender Hinweis. Hier scheint der Upload nie enden zu wollen, was auch ein Hinweis ist, warum sie später verschwindet: sie war nie auf dem Server.
Mein erster Verdacht war, dass vielleicht ein Virenscanner dazwischenfunkt und die Datei auf dem Server direkt wieder löscht. Alles schon mal vorgekommen. Also lade ich die beiden Bilder per FTP auf den Server, was auch funktioniert und somit gegen die Virenscannerhypothese spricht.
Also zurück in den Browser und mal schauen, was sich so in der Entwicklerkonsole tut. Und dort ist auch ein Eintrag:
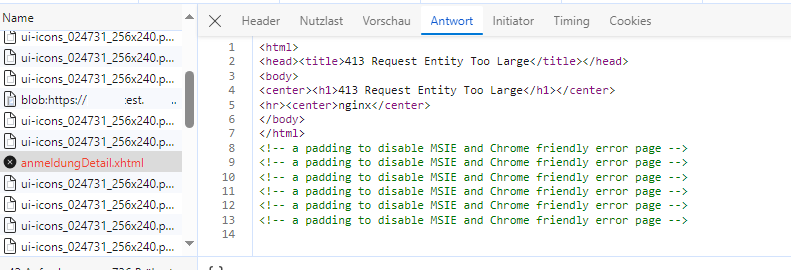
Der Upload wurde abgebrochen (413 - Request Entity Too Large). Das hat das JQuery- bzw. PrimeFaces-Framework nicht richtig erkannt und keine Fehlermeldung auf der Oberfläche angezeigt. Ein Bug im Framework, dass dieser spezielle Fall nicht richtig erkannt wird. Das interessiert mich aber nicht so sehr, viel spannender ist der Fehler 413. Erlaubt sind 10 MB, die Datei sind keine 7 MB. Es müsste also eigentlich passen.
In der Anwendung sind 10 MB erlaubt, das sollte nicht das Problem sein, bliebe noch der Anwendungsserver, ein Apache Tomcat, oder der davorgeschaltete ReverseProxy, ein Apache HTTP-Server.
Wenn man dem Netzwerkverkehr folgt sieht man, dass folgende Antwort beim Upload-Versuch zurück kommt:
Das Indiz für die Ursache des Problems ist das unscheinbare Wort: "nginx"
Der Verdacht erhärtet sich beim weiteren Testen: Wenn ich die WOW-Testdatei in der Anwendung hochlade, erscheint das POST in den Logs des vorgelagerten Apache-ReverseProxies:
Der Versuch des Hochladens des Problembildes erzeugt keinen Log-Eintrag.
Es scheint also so zu sein, dass der Upload bereits vor meiner Anwendung abgebrochen wird.
Der Server
Schauen wir mal, wie es auf dem Test Server aussieht:
Meine Anwendung starte ich über ein Docker-Compose, bestehend aus:
Apache HTTP als Reverse Proxy
Apache Tomcat
PG Admin
PostgreSQL Datenbank
Auf dem Server selbst läuft aber nicht nur meine Anwendung, sondern auch noch weitere, die uA über unterschiedliche Domainnamen erreichbar sind. Und das steuert ein Nginx-Server:
Und was finde ich, wenn ich das default File Limit für Nginx suche:
By default, Nginx has a limit of 1MB on file uploads.
Die Lösung
Wir müssen also den file upload für die Anwendung erhöhten auf 10MB, besser 15MB:
Nach der Änderung die Konfiguration prüfen, um sicher zu gehen, dass keine Fehler eingebaut wurden und beim Neustart (bzw. Reload) der ganze Nginx-Server lahm gelegt wird:
nginx -t
Erst dann den Neustart, bzw. Reload durchführen:
service nginx reload
Test
Abschließend muss natürlich noch der Test erfolgen, ob wir damit erfolgreich waren: Der Upload funktioniert jetzt! 🥳
Vor ca. zwei Jahren durfte ich einen Impusvortrag zum Thema Redis halten. Den Inhalt der Folien kopiere ich hierher.
Durch welches Problem bin ich auf Redis gestoßen?
• Migration einer Anwendung von SAP Application Server mit drei Application Server Instanzen auf zwei Apache Tomcat Server • Session Data ging durch Wechsel der Tomcat Server verloren • Lösung: Sticky Session [im LoadBalancer] • Alternative Lösung: Persistieren den Session in der Application Datenbank • • zB in PROJECT_XYZ umgesetzt • • Problem bei der aktuellen Application: DB hat bereits Performanceprobleme • Erweiterte alternative Lösung: • • Speichern der Session Daten in einer eigenen Datenbank • • -> Fragestellung: Gibt es für so ein Scenario spezialisierte Datenbanken?
[Anmerkung aus 2023: Es gibt beim Tomcat ein Clustering/Session Replication Feature, das hatten wir aber aus Gründen nicht in Erwägung gezogen]
Was ist Redis
Der Name Redis steht für Remote Dictionary Server.
In-Memory-Datenbank • Alle Daten werden direkt im Arbeitsspeicher gespeichert • Dadurch sehr kurze Zugriffszeiten • Auch bei großen, unstrukturierten Datenmengen
Key-Value-Store • Hohe Performanz • Dank einfacher Struktur leicht skalierbar • Zu jedem Eintrag wird ein Schlüssel erstellt, über den die Informationen dann wieder aufgerufen werden können.
Redis ist über Module erweiterbar. Mitbewerber der Key-Value-Datenbanken: Amazon DynamoDB
Weitere Optionen • Inkrementelle Vergrößerung oder Verkleinerung • Lebenszeit von Werten setzen • Mit append dem hinterlegten Wert einen weiteren hinzufügen • Einträge mit rename umbenennen
Heute durfte ich einen Impusvortrag zum Thema Quarkus halten. Den Inhalt der Folien incl. Kommentare und die Notizen der Live Demo kopiere ich hierher.
Quarkus
https://quarkus.io/
Was ist Quarkus?
• Open-Source-Framework • Um Anwendungen für eine moderne, Cloud-native Welt zu erstellen • Kubernetes-natives Java-Framework • auf GraalVM und HotSpot zugeschnitten • aus den besten Java-Bibliotheken und -Standards entwickelt
https://quarkus.io/about/
Was ist Quarkus?
Traditionelle Java-Stacks wurden für monolithische Anwendungen mit langen Startzeiten und großem Speicherbedarf in einer Welt entwickelt, in der es noch keine Cloud, Container und Kubernetes gab. Java-Frameworks mussten sich weiterentwickeln, um den Anforderungen dieser neuen Welt gerecht zu werden.
Quarkus wurde entwickelt, um Java-Entwicklern die Möglichkeit zu geben, Anwendungen für eine moderne, Cloud-native Welt zu erstellen. Quarkus ist ein Kubernetes-natives Java-Framework, das auf GraalVM und HotSpot zugeschnitten ist und aus den besten Java-Bibliotheken und -Standards entwickelt wurde. Ziel ist es, Java zur führenden Plattform in Kubernetes- und Serverless-Umgebungen zu machen und Entwicklern ein Framework zu bieten, das eine größere Bandbreite an verteilten Anwendungsarchitekturen abdeckt.
Vollständig und absolut Open Source
https://quarkus.io/about/
Ausgewählte Features
• Live-Coding mit Dev-Modus • Microprofile-Integration für Cloud-native Anwendungen • Nutzung von Quarkus für RESTful-Anwendungen • Serverless Funktionen mit Quarkus Funqy • Integration mit Datenbanken • Performance • Erweiterungen
Live-Coding mit Dev-Modus
Eine der herausragenden Eigenschaften von Quarkus ist die Möglichkeit des Live-Codings. Mit dem Dev-Modus können Entwickler Änderungen am Code vornehmen und diese Änderungen werden sofort in der laufenden Anwendung wirksam, ohne dass ein Neustart erforderlich ist. Dies beschleunigt den Entwicklungsprozess erheblich und ermöglicht eine iterative Entwicklung in Echtzeit.
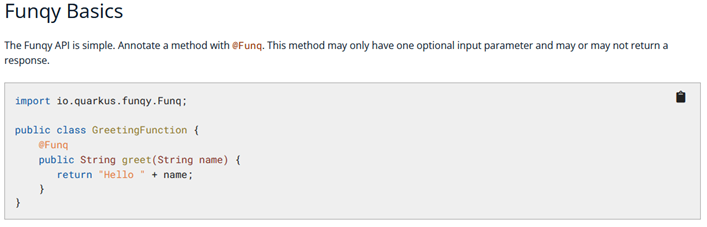
Serverless Funktionen mit Quarkus Funqy
Eine API für verschiedenen FaaS-Umgebungen wie AWS Lambda, Azure Functions, Google Cloud Functions, Knative und Knative Events (Cloud Events), daher eine sehr einfache API.
https://quarkus.io/guides/funqy
Quarkus Funqy ist Teil der serverlosen Strategie von Quarkus und zielt darauf ab, eine portable Java-API zum Schreiben von Funktionen bereitzustellen, die in verschiedenen FaaS-Umgebungen wie AWS Lambda, Azure Functions, Google Cloud Functions, Knative und Knative Events (Cloud Events) eingesetzt werden können. Es ist auch als eigenständiger Dienst nutzbar.
Da es sich bei Funqy um eine Abstraktion handelt, die mehrere verschiedene Cloud-/Funktionsanbieter und Protokolle umfasst, muss es eine sehr einfache API sein und verfügt daher möglicherweise nicht über alle Funktionen, die Sie von anderen Remoting-Abstraktionen gewohnt sind. Ein schöner Nebeneffekt ist jedoch, dass Funqy so optimiert und so klein wie möglich ist. Das bedeutet, dass Funqy zwar ein wenig an Flexibilität einbüßt, dafür aber einen Rahmen bietet, der wenig bis gar keinen Overhead hat.
Integration mit Datenbanken
Quarkus bietet Erweiterungen für verschiedene Datenbanken, wie z.B. PostgreSQL, MySQL, MongoDB und viele mehr.
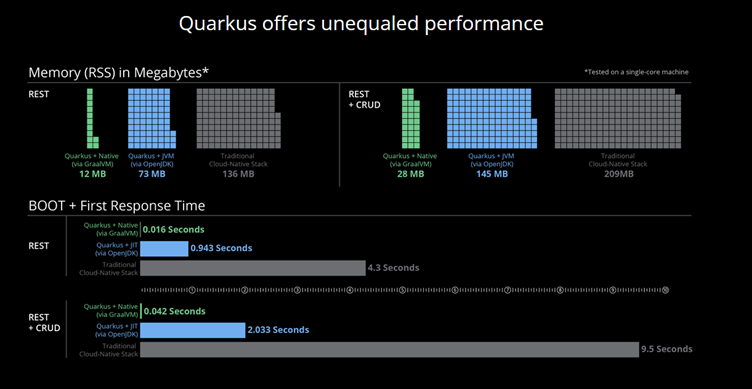
Performance
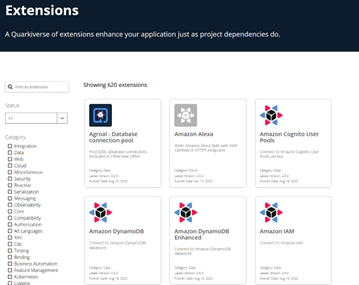
Erweiterungen
Live Demo
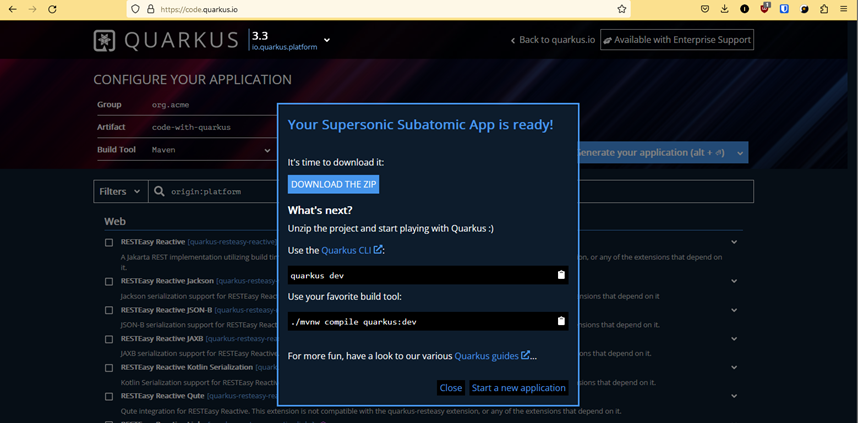
Download
https://code.quarkus.io/
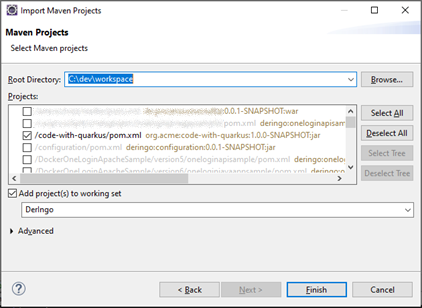
Import into Eclipse IDE
Prerequisites
Eclipse öffnen, Terminal mit Ubuntu (WSL) öffnen
Java und Maven Versionen überprüfen:
java --version
echo $JAVA_HOME
mvn --version
# bei mir wird die Maven Version nicht angezeigt, wohl aber der Pfad der Installation, über den prüfe ich die Version
ls - lisah /opt/maven
cd /mnt/c/dev/workspace/code-with-quarkus/
clear
Start Quarkus
Starte Projekt:
./mvnw compile quarkus:dev
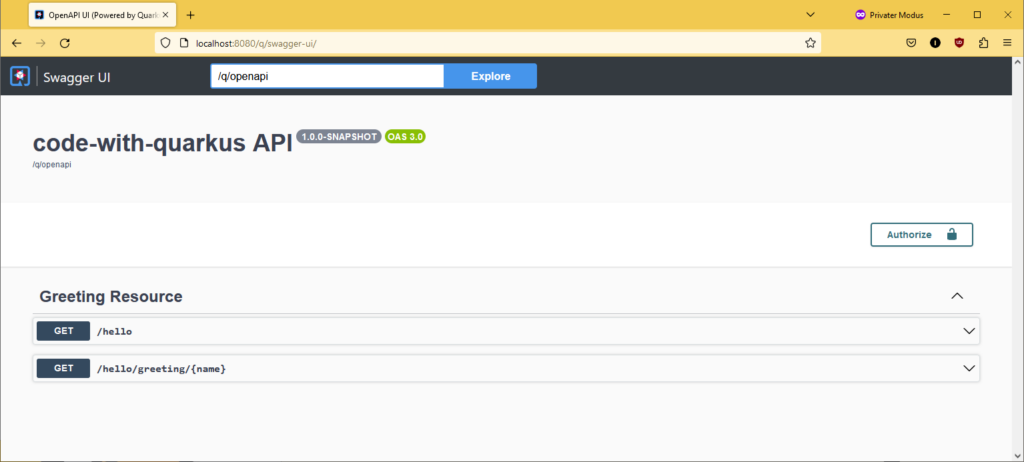
Internal Web Browser öffnen: http://localhost:8080/ „Visit the DEV UI“ funktioniert nicht im Eclipse Browser
Return String ändern und hello-Seite neu laden -> kein Neustart notwendig!
curl http://localhost:8080/hello
# In Klasse GreetingResource ändern von:
@Produces(MediaType.TEXT_PLAIN)
# nach:
@Produces(MediaType.APPLICATION_JSON)
Änderung wird auch hier ohne Neustart übernommen, um sie zu zeigen verwende ich HTTPie statt cURL:
http http://localhost:8080/hello
Um das Hot Deployment für JUnit Tests zu zeigen gehe ich in das Terminal, mit dem ich Quarkus gestartet habe und drücke "r" für "re-run test". Der Test schlägt fehlt, da ich in GreetingResource den Rückgabestring geändert hatte. Ich passe den zu erwartenden Wert in GreetingResourceTest an und drücke dann wieder "r" im Terminal. Alle Tests sind jetzt grün. Es war kein Neustart notwendig.
Contexts and Dependency Injection (CDI)
Klasse GreetingService hinzufügen:
package org.acme;
import jakarta.enterprise.context.ApplicationScoped;
@ApplicationScoped
public class GreetingService {
private String greeting = "Hallo";
public String greeting(String name) {
return greeting + " " + name;
}
}
Die Klasse GreetingResource erweitern:
package org.acme;
import jakarta.inject.Inject;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
@Path("/hello")
public class GreetingResource {
@Inject
GreetingService service;
@GET
@Produces(MediaType.TEXT_PLAIN)
public String hello() {
return "Hello from Welt";
}
@GET
@Produces(MediaType.TEXT_PLAIN)
@Path("/greeting/{name}")
public String greeting(String name) {
return service.greeting(name);
}
}
Und wieder ohne Neustart testen:
http http://localhost:8080/hello/greeting/Welt
Configuration
Klasse GreetingService ändern:
package org.acme;
import jakarta.enterprise.context.ApplicationScoped;
@ApplicationScoped
public class GreetingService {
@ConfigProperty(name = "greeting")
private String greeting;
public String greeting(String name) {
return greeting + " " + name;
}
}
Testen:
http http://localhost:8080/hello/greeting/Welt
Der Test schlägt fehl, da die Property greeting noch nicht gesetzt wurde, was wir jetzt nachholen:
greeting=Huhu
Testen:
http http://localhost:8080/hello/greeting/Welt
Jetzt funktioniert es und es kommt "Huhu Welt" zurück.
Staged Properties: In DEV Modus möchten wir eine andere Begrüßung sehen:
greeting=Huhu
%%dev.greeting=Moin
Testen:
http http://localhost:8080/hello/greeting/Welt
Es funktioniert und es kommt "Moin Welt" zurück.
Metrics
Testen:
http http://localhost:8080/q/metrics
Fehler: Not Found
Mit Maven nachinstallieren (alternativ: Gradle oder Quarkus CLI):
Everyone talks about Kubernetes, therefore I thought, it might be a good idea to get some experiences with this tool and install it on my developer machine.
To run a single node cluster of Kubernetes on my machine I will install Minikube.
My developer machine is a Windows computer with Ubuntu 20.04 on WSL 2.
$ minikube start
😄 minikube v1.30.1 on Ubuntu 20.04
✨ Automatically selected the docker driver. Other choices: none, ssh
📌 Using Docker driver with root privileges
👍 Starting control plane node minikube in cluster minikube
🚜 Pulling base image ...
💾 Downloading Kubernetes v1.26.3 preload ...
> preloaded-images-k8s-v18-v1...: 397.02 MiB / 397.02 MiB 100.00%% 3.21 Mi
> gcr.io/k8s-minikube/kicbase...: 373.53 MiB / 373.53 MiB 100.00%% 2.76 Mi
🔥 Creating docker container (CPUs=2, Memory=6300MB) ...
🐳 Preparing Kubernetes v1.26.3 on Docker 23.0.2 ...
▪ Generating certificates and keys ...
▪ Booting up control plane ...
▪ Configuring RBAC rules ...
🔗 Configuring bridge CNI (Container Networking Interface) ...
▪ Using image gcr.io/k8s-minikube/storage-provisioner:v5
🔎 Verifying Kubernetes components...
🌟 Enabled addons: default-storageclass, storage-provisioner
🏄 Done! kubectl is now configured to use "minikube" cluster and "default" namespace by default
Step 6: Minikube Basic operations
To check cluster status, run:
$ kubectl cluster-info
Kubernetes control plane is running at https://127.0.0.1:32769
CoreDNS is running at https://127.0.0.1:32769/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
Note that Minikube configuration file is located under ~/.minikube/machines/minikube/config.json
Let's doublecheck that minikube is a running Docker container:
$ sudo docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e36590b3ea7e gcr.io/k8s-minikube/kicbase:v0.0.39 "/usr/local/bin/entr…" 28 minutes ago Up 28 minutes 127.0.0.1:32772->22/tcp, 127.0.0.1:32771->2376/tcp, 127.0.0.1:32770->5000/tcp, 127.0.0.1:32769->8443/tcp, 127.0.0.1:32768->32443/tcp minikube
ingo:~$ minikube dashboard --port=42827 &
[6] 55787
ingo:~$ 🤔 Verifying dashboard health ...
🚀 Launching proxy ...
🤔 Verifying proxy health ...
🎉 Opening http://127.0.0.1:42827/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/ in your default browser...
👉 http://127.0.0.1:42827/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/
Open URL in Browser:
kubernetes dashboard
To enable a module use command:
minikube addons enable <module>
Example:
$ minikube addons enable portainer
❗ portainer is a 3rd party addon and is not maintained or verified by minikube maintainers, enable at your own risk.
❗ portainer does not currently have an associated maintainer.
▪ Using image docker.io/portainer/portainer-ce:2.15.1
🌟 The 'portainer' addon is enabled
But I have no clue, what to do with the enabled 'portainer' addon. 🤷♂️
Deployments are the recommended way to manage the creation and scaling of Pods.
Use the kubectl create command to create a Deployment that manages a Pod. The Pod runs a Container based on the provided Docker image.
# Run a test container image that includes a webserver
kubectl create deployment hello-node --image=registry.k8s.io/e2e-test-images/agnhost:2.39 -- /agnhost netexec --http-port=8080
2. View the Deployment:
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
hello-node 0/1 1 0 9s
3. View the Pod:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
hello-node-7b87cd5f68-rj79x 1/1 Running 0 67s
4. View cluster events:
kubectl get events
5. View the kubectl configuration:
kubectl config view
Create a Service
By default, the Pod is only accessible by its internal IP address within the Kubernetes cluster. To make the hello-node Container accessible from outside the Kubernetes virtual network, you have to expose the Pod as a Kubernetes Service.
Expose the Pod to the public internet using the kubectl expose command:
The --type=LoadBalancer flag indicates that you want to expose your Service outside of the cluster.
The application code inside the test image only listens on TCP port 8080. If you used kubectl expose to expose a different port, clients could not connect to that other port.
2. View the Service you created:
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-node LoadBalancer 10.101.148.235 <pending> 8080:31331/TCP 2m52s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 71m
On cloud providers that support load balancers, an external IP address would be provisioned to access the Service. On minikube, the LoadBalancer type makes the Service accessible through the minikube service command.
3. Run the following command:
$ minikube service hello-node
|-----------|------------|-------------|---------------------------|
| NAMESPACE | NAME | TARGET PORT | URL |
|-----------|------------|-------------|---------------------------|
| default | hello-node | 8080 | http://192.168.49.2:31331 |
|-----------|------------|-------------|---------------------------|
🏃 Starting tunnel for service hello-node.
|-----------|------------|-------------|------------------------|
| NAMESPACE | NAME | TARGET PORT | URL |
|-----------|------------|-------------|------------------------|
| default | hello-node | | http://127.0.0.1:34597 |
|-----------|------------|-------------|------------------------|
🎉 Opening service default/hello-node in default browser...
👉 http://127.0.0.1:34597
❗ Because you are using a Docker driver on linux, the terminal needs to be open to run it.
Open http://127.0.0.1:34597/ in a browser:
hello-node
4. View Pods and Services created in 'default' namespace:
$ kubectl get pod,svc -n default
NAME READY STATUS RESTARTS AGE
pod/hello-node-7b87cd5f68-rj79x 1/1 Running 0 12m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/hello-node LoadBalancer 10.101.148.235 <pending> 8080:31331/TCP 8m54s
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 77m
5. Cleanup
$ kubectl delete service hello-node
service "hello-node" deleted
$ kubectl delete deployment hello-node
deployment.apps "hello-node" deleted
kubectl apply -f deployment.yaml
kubectl get deployment
kubectl get service
Start Service:
minikube service nginx-service &
Check in Terminal:
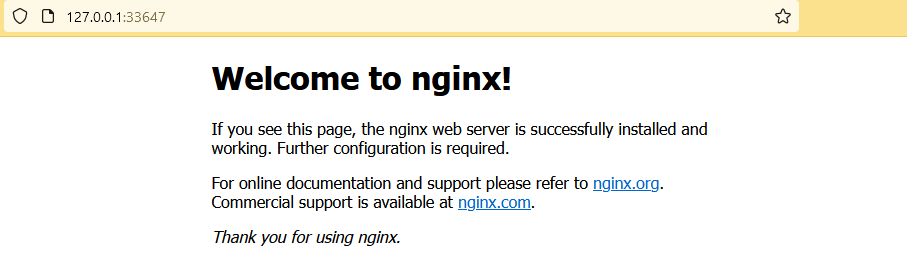
$ http http://127.0.0.1:45137
HTTP/1.1 200 OK
Accept-Ranges: bytes
Connection: keep-alive
Content-Length: 615
Content-Type: text/html
Date: Thu, 29 Jun 2023 14:57:23 GMT
ETag: "6488865a-267"
Last-Modified: Tue, 13 Jun 2023 15:08:10 GMT
Server: nginx/1.25.1
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<title>Page Title</title>
</head>
<body>
<h1>This is a Heading</h1>
<p style="color: green;">This is a paragraph.</p>
<p>Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet.</p>
</body>
</html>
Dockerfile for an nginx webserver to deliver this website:
FROM nginx
COPY index.html /usr/share/nginx/html
EXPOSE 80
Build, run and test image:
docker build -t myweb-image .
docker run -it -p 80:80 --name myweb-container myweb-image
$ http http://localhost
HTTP/1.1 200 OK
Accept-Ranges: bytes
Connection: keep-alive
Content-Length: 763
Content-Type: text/html
Date: Thu, 29 Jun 2023 15:57:54 GMT
ETag: "649da8a5-2fb"
Last-Modified: Thu, 29 Jun 2023 15:52:05 GMT
Server: nginx/1.25.1
<!DOCTYPE html>
<html>
<head>
<title>Page Title</title>
</head>
<body>
<h1>This is a Heading</h1>
<p style="color: green;">This is a paragraph.</p>
<p>Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet.</p>
</body>
</html>
kubectl apply -f myweb.yaml
kubectl get deployment
kubectl get service
Start Service:
minikube service myweb-service &
Check in Terminal:
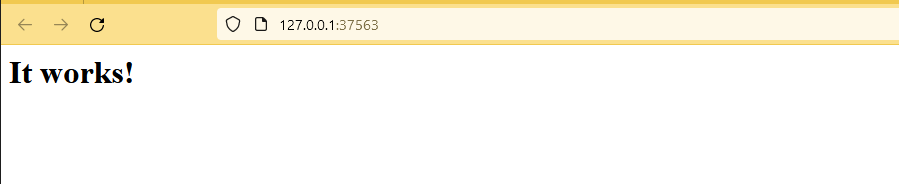
$ http http://127.0.0.1:38915
HTTP/1.1 200 OK
Accept-Ranges: bytes
Connection: keep-alive
Content-Length: 763
Content-Type: text/html
Date: Thu, 29 Jun 2023 16:19:18 GMT
ETag: "649da8a5-2fb"
Last-Modified: Thu, 29 Jun 2023 15:52:05 GMT
Server: nginx/1.25.1
<!DOCTYPE html>
<html>
<head>
<title>Page Title</title>
</head>
<body>
<h1>This is a Heading</h1>
<p style="color: green;">This is a paragraph.</p>
<p>Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet.</p>
</body>
</html>
Cleanup:
$ kubectl delete -f myweb.yaml
Work in a pod
Start some pods & service and display them:
kubectl apply -f myweb.yaml
kubectl get all -o wide
Output:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/myweb-deployment-565b64686c-2nnrl 1/1 Running 0 3m42s 10.244.0.39 minikube <none> <none>
pod/myweb-deployment-565b64686c-m4p4c 1/1 Running 0 3m42s 10.244.0.41 minikube <none> <none>
pod/myweb-deployment-565b64686c-sx6sx 1/1 Running 0 3m42s 10.244.0.40 minikube <none> <none>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 23h <none>
service/myweb-service NodePort 10.97.251.106 <none> 80:32715/TCP 3m42s app=myweb-app
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment.apps/myweb-deployment 3/3 3 3 3m42s myweb-container myweb-image:1.0 app=myweb-app
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
replicaset.apps/myweb-deployment-565b64686c 3 3 3 3m42s myweb-container myweb-image:1.0 app=myweb-app,pod-template-hash=565b64686c
i
apt update
apt install httpie inetutils-ping -y
# Connect to another Pod via IP
http 10.244.0.39
# Connect to Service via IP
http 10.97.251.106
# Connect to Service via Service Name
http myweb-service
# Check IP of Service
ping myweb-service
## OUTPUT:
# PING myweb-service.default.svc.cluster.local (10.97.251.106): 56 data bytes
exit
Cleanup:
$ kubectl delete -f myweb.yaml
Environment Variable
Sample how to set an environment variable via deployment file:
Add env section to deployment file:
[...]
spec:
containers:
- name: myweb-container
image: myweb-image:1.0
ports:
- containerPort: 80
env:
- name: MY_ENV_1
value: My Value No 1
- name: MY_ENV_2
value: My Value No 2
---
[...]
Start Pods, jump into Pod and check values:
kubectl apply -f myweb.yaml
kubectl get all -o wide
kubectl exec -it myweb-deployment-864984686b-5p7dn -- /bin/bash
## Inside Pod:
echo $MY_ENV_1
# Output: My Value No 1
echo $MY_ENV_2
# Output: My Value No 2
exit
# Cleanup:
kubectl delete -f myweb.yaml
Ich möchte eine lokale Oracle Datenbank mit Docker laufen lassen um so einige Sachen schnell lokal testen zu können. Hintergrund ist eine anstehende Cloud zu Cloud Migration einer bestehenden Anwendung, bei der zugleich die Oracle DB und Java aktualisiert werden wird.
Docker Image
Bei PostgreSQL war das mit der gedockerten Datenbank relativ einfach. Oracle macht es etwas schwieriger. Einfache Images, die man auf dem Docker Hub finden kann, existieren nicht. Statt dessen muss man ein GitHub Repository clonen und ein Shell Script ausführen, um ein Image zu erzeugen und in die lokale Registry zu schieben.
Frei verfügbar sind nur die Versionen Oracle Database 18c XE, 21c XE and 23c FREE. Ich entscheide mich, für die beiden Versionen 21c XE und 23c FREE das Image zu erzeugen und dann zuerst mit Version 23c FREE zu testen und ggf. später weitere Tests mit Version 21c XE machen zu können.
cd <workspace>
mkdir oracle
cd oracle
git clone https://github.com/oracle/docker-images.git
cd docker-images/OracleDatabase/SingleInstance/dockerfiles/
./buildContainerImage.sh -h
./buildContainerImage.sh -f 23.2.0
# Oracle Database container image for 'free' version 23.2.0 is ready to be extended:
#
# --> oracle/database:23.2.0-free
#
# Build completed in 608 seconds.
./buildContainerImage.sh -x 21.3.0
# Version 23.2.0 does not have Express Edition available.
Die Erzeugung des zweiten Images hat leider nicht funktioniert. Da das erste Image schon so lange gebraucht hat und ich das zweite Image nur proaktiv anlegen wollte, bin ich auch momentan nicht großartig motiviert, dem jetzt weiter nachzugehen. Version 23c FREE reicht erst einmal.
Image direkt von Oracle
Nach dieser Doku kann man das Image auch direkt aus der Oracle Registry ziehen. Zumindest für Oracle Database 23c Free – Developer Release.
Docker Container
Die Dokumentation hat einen speziellen Abschnitt für 23c FREE
Den Abschnitt auf jeden Fall gut ansehen, ich habe den Container mit folgendem Befehl erzeugt:
Die Wahl der Library fiel auf ZXing (“zebra crossing”), denn das ist die main library that supports QR codes in Java. und ich habe keine Anhaltspunkte finden können, warum ich eine andere Library nehmen sollte.
package deringo;
import java.awt.Desktop;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.HashMap;
import java.util.Map;
import com.google.zxing.BarcodeFormat;
import com.google.zxing.EncodeHintType;
import com.google.zxing.MultiFormatWriter;
import com.google.zxing.NotFoundException;
import com.google.zxing.WriterException;
import com.google.zxing.client.j2se.MatrixToImageWriter;
import com.google.zxing.common.BitMatrix;
import com.google.zxing.qrcode.decoder.ErrorCorrectionLevel;
public class TestMain {
public static void main(String args[]) throws WriterException, IOException, NotFoundException {
String data = "Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam";
Path path = Paths.get("./test.png");
// Encoding charset to be used
String charset = "UTF-8";
Map<EncodeHintType, ErrorCorrectionLevel> hashMap = new HashMap<EncodeHintType, ErrorCorrectionLevel>();
// generates QR code with Low level(L) error correction capability
hashMap.put(EncodeHintType.ERROR_CORRECTION, ErrorCorrectionLevel.L);
// invoking the user-defined method that creates the QR code
generateQRcode(data, path, charset, hashMap, 200, 200);// increase or decrease height and width accodingly
System.out.println("QR Code created successfully.");
Desktop.getDesktop().open(path.toFile());
}
public static void generateQRcode(String data, Path path, String charset, Map<EncodeHintType, ErrorCorrectionLevel> map, int h, int w)
throws WriterException, IOException {
BitMatrix matrix = new MultiFormatWriter().encode(new String(data.getBytes(charset), charset),
BarcodeFormat.QR_CODE, w, h);
MatrixToImageWriter.writeToPath(matrix, getExtension(path), path);
}
/**
* Own function until we have this in JDK<br>
* Finally, there is a new method Path#getExtension available right in the JDK as of Java 21:<br>
* https://stackoverflow.com/questions/3571223/how-do-i-get-the-file-extension-of-a-file-in-java/74315488#74315488
*/
public static String getExtension(Path path) {
String extension = path.getFileName().toString().substring(path.getFileName().toString().lastIndexOf('.') + 1);
return extension;
}
}
ZXing und Docx4J
Der QR Code lässt sich schön als PNG generieren. Allerdings brauche ich den QR Code in einem Word Dokument. Das Word Dokument wird mit Docx4J generiert.
package deringo;
import java.awt.Desktop;
import java.io.File;
import java.nio.file.Files;
import org.docx4j.dml.wordprocessingDrawing.Inline;
import org.docx4j.openpackaging.packages.WordprocessingMLPackage;
import org.docx4j.openpackaging.parts.WordprocessingML.BinaryPartAbstractImage;
import org.docx4j.openpackaging.parts.WordprocessingML.MainDocumentPart;
import org.docx4j.wml.Drawing;
import org.docx4j.wml.Jc;
import org.docx4j.wml.JcEnumeration;
import org.docx4j.wml.ObjectFactory;
import org.docx4j.wml.P;
import org.docx4j.wml.PPr;
import org.docx4j.wml.R;
public class TestMain {
public static void main(String[] args) throws Exception {
WordprocessingMLPackage wordPackage = WordprocessingMLPackage.createPackage();
MainDocumentPart mainDocumentPart = wordPackage.getMainDocumentPart();
mainDocumentPart.addStyledParagraphOfText("Title", "Welcome to my QR Code");
mainDocumentPart.addParagraphOfText("Welcome to my QR Code");
File image = new File("test.png" );
byte[] fileContent = Files.readAllBytes(image.toPath());
BinaryPartAbstractImage imagePart = BinaryPartAbstractImage
.createImagePart(wordPackage, fileContent);
Inline inline = imagePart.createImageInline(
"QR Code Image (filename hint)", "Alt Text", 1, 2, false);
P Imageparagraph = addImageToParagraph(inline);
mainDocumentPart.getContent().add(Imageparagraph);
File exportFile = new File("welcome.docx");
wordPackage.save(exportFile);
Desktop.getDesktop().open(exportFile);
}
private static P addImageToParagraph(Inline inline) {
ObjectFactory factory = new ObjectFactory();
P p = factory.createP();
R r = factory.createR();
p.getContent().add(r);
Drawing drawing = factory.createDrawing();
r.getContent().add(drawing);
drawing.getAnchorOrInline().add(inline);
// center image
PPr paragraphProperties = factory.createPPr();
Jc justification = factory.createJc();
justification.setVal(JcEnumeration.CENTER);
paragraphProperties.setJc(justification);
p.setPPr(paragraphProperties);
return p;
}
}
Das Ergebnis sieht brauchbar aus:
Allerdings habe ich die zuvor gespeicherte Datei verwendet. Ich möchte das aber on the fly machen, also ohne, dass ich den QR Code erst speichere und dann in das Word Dokument übernehme.
package deringo;
import java.awt.Desktop;
import java.awt.image.BufferedImage;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.util.HashMap;
import java.util.Map;
import javax.imageio.ImageIO;
import org.docx4j.dml.wordprocessingDrawing.Inline;
import org.docx4j.openpackaging.packages.WordprocessingMLPackage;
import org.docx4j.openpackaging.parts.WordprocessingML.BinaryPartAbstractImage;
import org.docx4j.openpackaging.parts.WordprocessingML.MainDocumentPart;
import org.docx4j.wml.Drawing;
import org.docx4j.wml.Jc;
import org.docx4j.wml.JcEnumeration;
import org.docx4j.wml.ObjectFactory;
import org.docx4j.wml.P;
import org.docx4j.wml.PPr;
import org.docx4j.wml.R;
import com.google.zxing.BarcodeFormat;
import com.google.zxing.EncodeHintType;
import com.google.zxing.MultiFormatWriter;
import com.google.zxing.client.j2se.MatrixToImageWriter;
import com.google.zxing.common.BitMatrix;
import com.google.zxing.qrcode.decoder.ErrorCorrectionLevel;
public class TestMain {
public static void main(String[] args) throws Exception {
WordprocessingMLPackage wordPackage = WordprocessingMLPackage.createPackage();
MainDocumentPart mainDocumentPart = wordPackage.getMainDocumentPart();
mainDocumentPart.addStyledParagraphOfText("Title", "Welcome to my QR Code");
mainDocumentPart.addParagraphOfText("Welcome to my QR Code");
BinaryPartAbstractImage imagePart = BinaryPartAbstractImage
.createImagePart(wordPackage, getQRCode());
Inline inline = imagePart.createImageInline(
"QR Code Image (filename hint)", "Alt Text", 1, 2, false);
P Imageparagraph = addImageToParagraph(inline);
mainDocumentPart.getContent().add(Imageparagraph);
File exportFile = new File("welcome.docx");
wordPackage.save(exportFile);
Desktop.getDesktop().open(exportFile);
}
private static P addImageToParagraph(Inline inline) {
ObjectFactory factory = new ObjectFactory();
P p = factory.createP();
R r = factory.createR();
p.getContent().add(r);
Drawing drawing = factory.createDrawing();
r.getContent().add(drawing);
drawing.getAnchorOrInline().add(inline);
// center image
PPr paragraphProperties = factory.createPPr();
Jc justification = factory.createJc();
justification.setVal(JcEnumeration.CENTER);
paragraphProperties.setJc(justification);
p.setPPr(paragraphProperties);
return p;
}
public static byte[] getQRCode() throws Exception {
String data = "Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam";
// Encoding charset to be used
String charset = "UTF-8";
Map<EncodeHintType, ErrorCorrectionLevel> hashMap = new HashMap<EncodeHintType, ErrorCorrectionLevel>();
// generates QR code with Low level(L) error correction capability
hashMap.put(EncodeHintType.ERROR_CORRECTION, ErrorCorrectionLevel.L);
BitMatrix matrix = new MultiFormatWriter().encode(new String(data.getBytes(charset), charset),
BarcodeFormat.QR_CODE, 200, 200);
BufferedImage bi = MatrixToImageWriter.toBufferedImage(matrix);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ImageIO.write(bi, "png", baos);
byte[] bytes = baos.toByteArray();
return bytes;
}
}
Allerdings ändert sich bei jedem Durchlauf der Initialization Vector (IV). Dadurch kann man den verschlüsselten Wert (der in dem Beispielcode nicht ausgegeben wird) nicht in einem zweiten Durchlauf wieder entschlüsseln. Das entspricht somit noch nicht dem, was ich brauche.
Mein Code
Ich möchte lediglich einen String verschlüsseln, über den QR-Code weitergeben und später soll der verschlüsselte Wert wieder entschlüsselt werden. Daher muss ich, anders als in dem Beispiel oben, Passwort, Salt und IV speichern.
Dazu brauche ich einen IV im String Format, den ich mir als erstes generieren lasse:
public static String generateIV() {
byte[] iv = new byte[16];
new SecureRandom().nextBytes(iv);
return Base64.getEncoder().encodeToString(iv);
}
Passwort, Salt und IV-String werden in den Properties gespeichert:
Damit kann ich die Methoden zum Erstellen von SecretKey und IvParameterSpec erstellen und darauf aufbauend die Methoden encrypt(String) und decrypt(String):
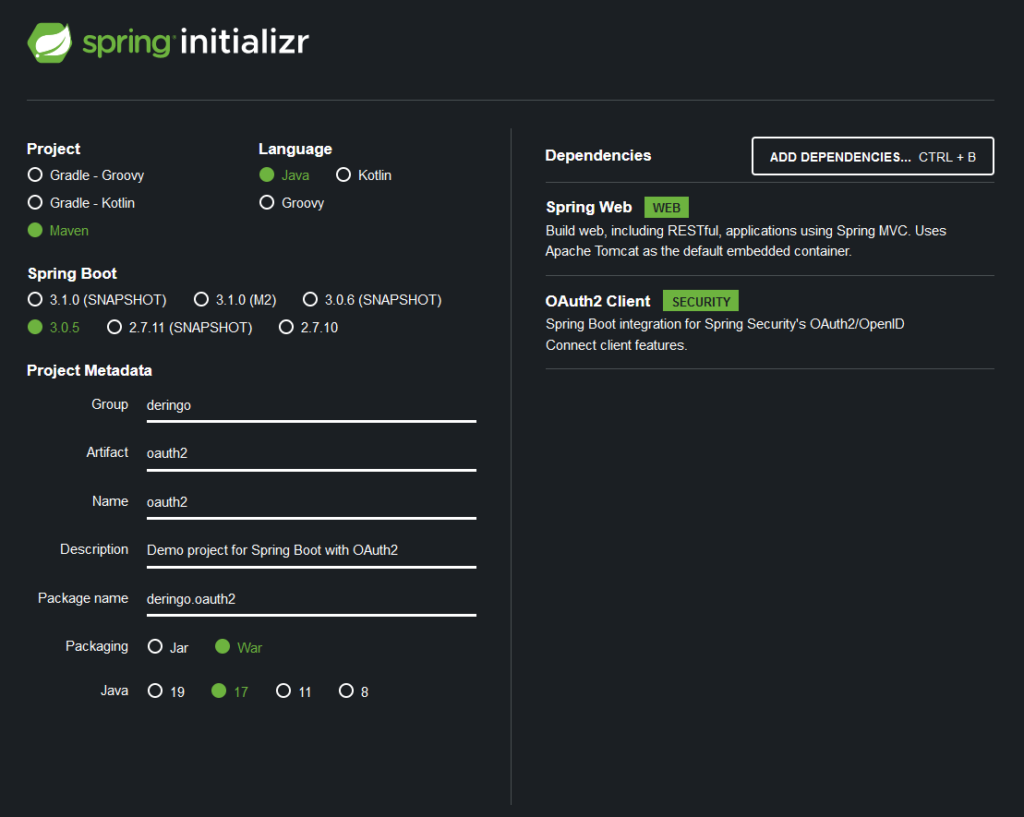
Spring Initializr verwenden. Als Dependencies Spring Web und OAuth2 Client hinzufügen.
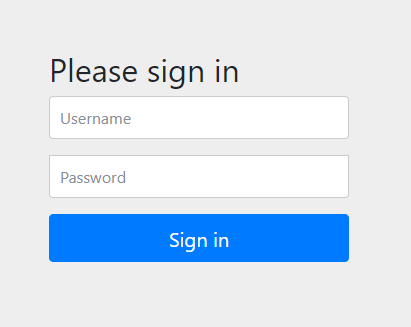
Zip-File herunterladen und in das Projekt entpacken. Warten bis Maven alle Dependencies heruntergeladen hat und anschließend Oauth2Application starten.
Unter http://localhost:8080 wird eine Login-Seite angezeigt:
Add a Home Page
Hier halte ich mich an den Guide. Die WebJars kannte ich bereits, aber noch nicht deren Locator. Den muss ich mal in meinem JSF Projekt ausprobieren.
In your new project, create index.html in the src/main/resources/static folder. You should add some stylesheets and JavaScript links so the result looks like this:
None of this is necessary to demonstrate the OAuth 2.0 login features, but it’ll be nice to have a pleasant UI in the end, so you might as well start with some basic stuff in the home page.
If you start the app and load the home page, you’ll notice that the stylesheets have not been loaded. So, you need to add those as well by adding jQuery and Twitter Bootstrap:
The final dependency is the webjars "locator" which is provided as a library by the webjars site. Spring can use the locator to locate static assets in webjars without needing to know the exact versions (hence the versionless /webjars/** links in the index.html). The webjar locator is activated by default in a Spring Boot app, as long as you don’t switch off the MVC autoconfiguration.
With those changes in place, you should have a nice looking home page for your app.
Oauth2Application starten. Mir wird wieder die Login-Seite angezeigt. Ich nehme die spring-boot-starter-oauth2-client Dependency aus der pom.xml heraus, starte Oauth2Application neu und sehe eine leere Seite.
Mir ist nicht ganz klar, woran das liegt, also mache ich erstmal weiter mit dem Guide, in der Hoffnung dass es am Ende laufen wird.
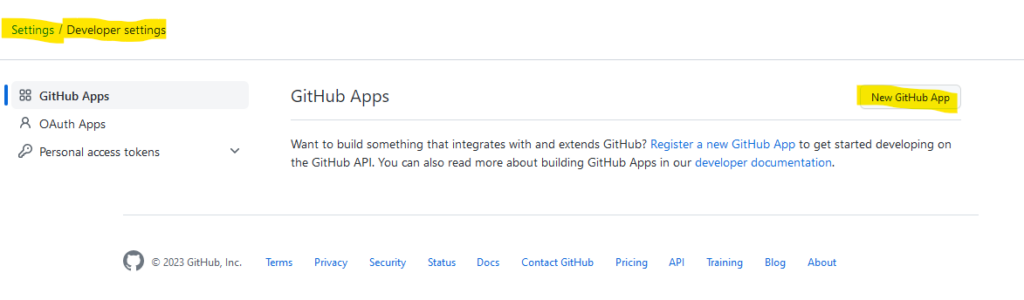
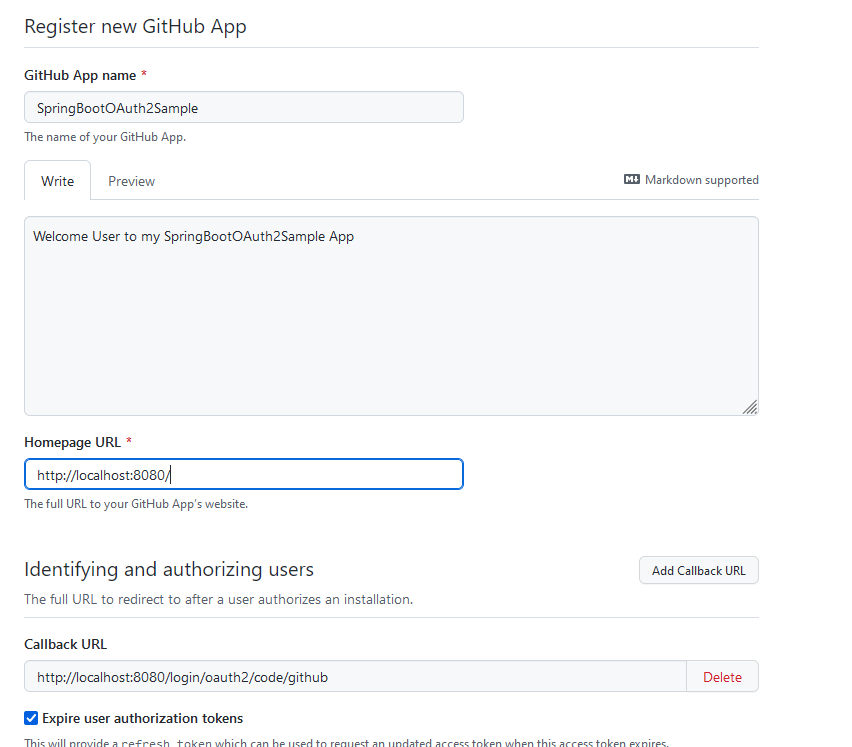
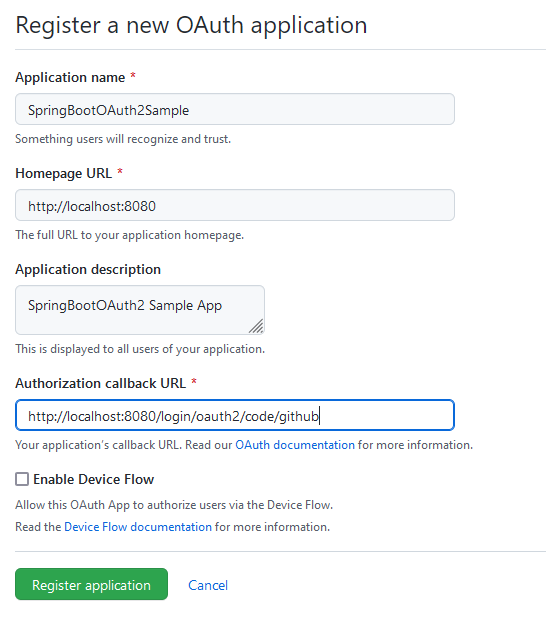
Add a New GitHub App
Webhook: Active Flag deaktivieren
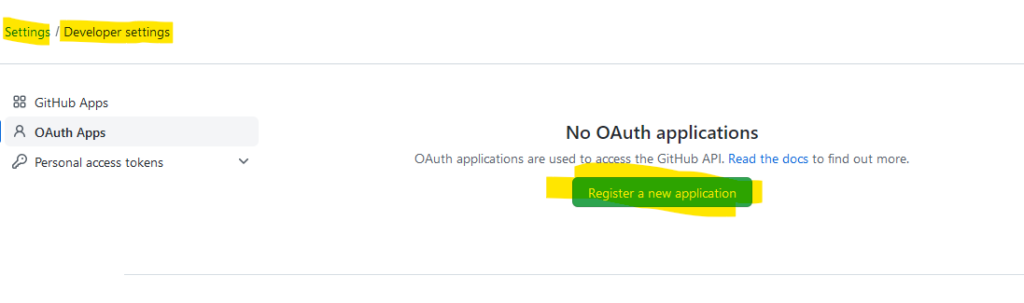
MÖÖÖÖÖÖP FALSCH
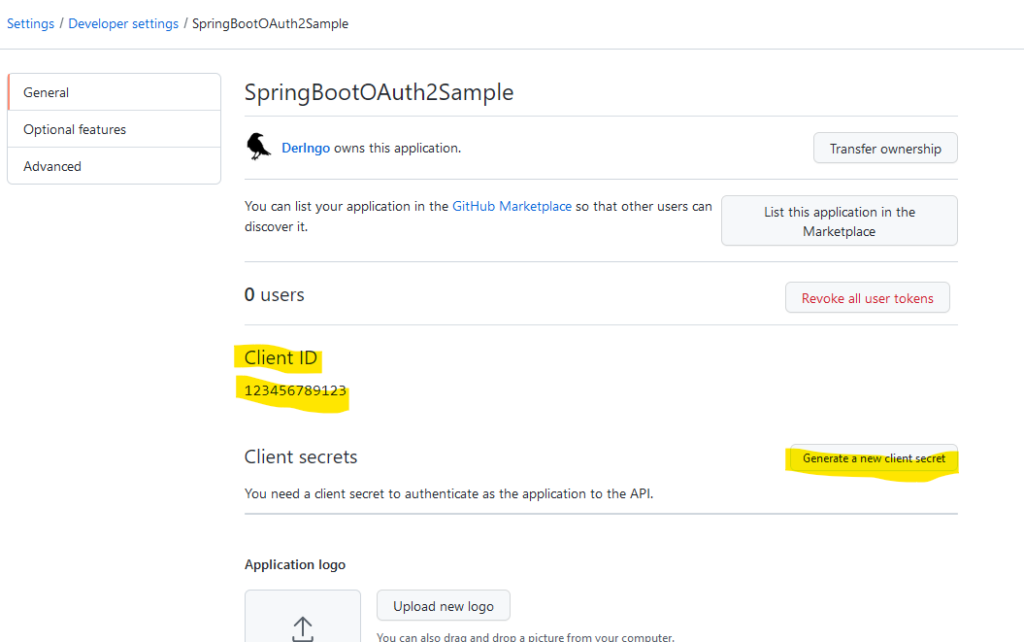
Ich habe oben eine GitHub App angelegt und keine OAuth App. Also nochmal von vorn:
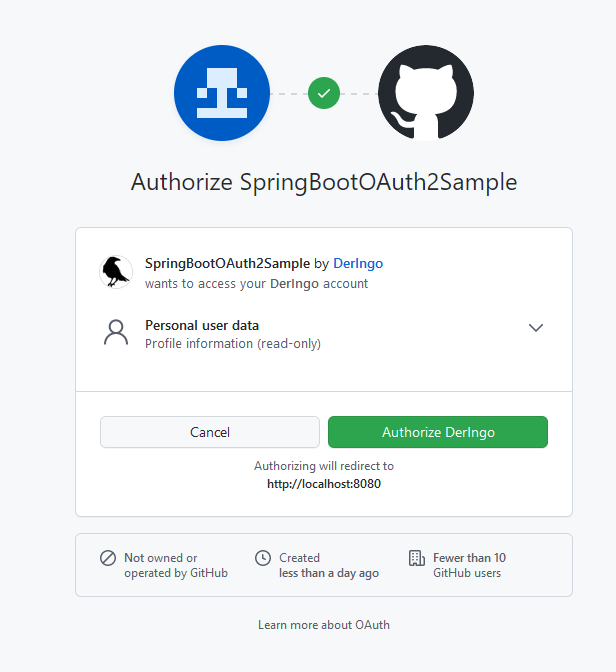
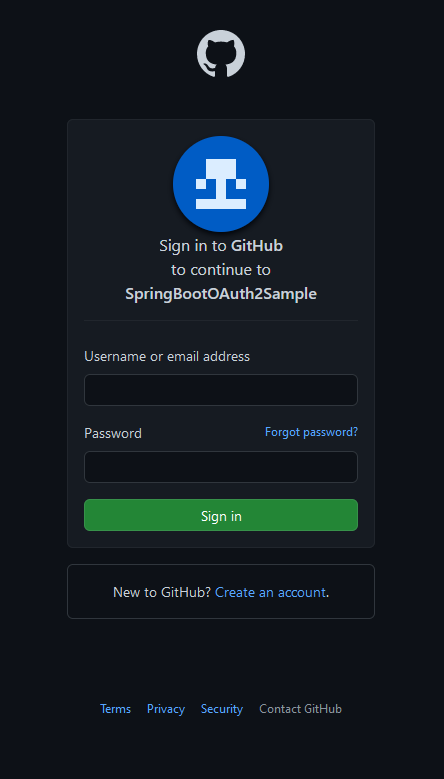
In einem anderen Tab des Browsers war ich bereits in GitHub eingeloggt:
Wenn ich den Seitenaufruf in einem neuen privaten Browserfenster tätige, sieht die Anmeldung so aus:
In beiden Fällen wird anschließend eine leere Seite angezeigt:
Auch die index.html bleibt leer:
Also irgendwas ist da noch nicht richtig. Anscheinend hatte ich die index.html nicht richtig gespeichert, die Datei war noch leer. Also den Code hinzugefügt und gespeichert.
Anschließend funktioniert es auch:
Sehr schön, da kann der Zukunftsingo sich ja freuen, hier weiter herumzuexperimentieren, sobald wieder etwas Zeit ist.