In meinem letzten Blogeintrag habe ich eine geDockerte Anwendung auf einem Server mit Ubuntu 18 zum laufen gebracht. Aus verschiedenen Gründen war das aber nur ein Zwischenschritt, um zu testen, ob die Anwendung grundsätzlich in solch einer Umgebung lauffähig ist. Neben den beschriebenen Problemen gab es noch viele weitere, die gelöst werden mussten.
Als nächsten Schritt möchte ich die Anwendung in die AWS umziehen, immerhin bin ich ja inzwischen ein zertifizierter Cloud Practitioner.
AWS User
Mit dem Stammbenutzer einen neuen IAM Nutzer für die Anwendung anlegen. Dieser bekommt erstmal umfangreiche Rechte, was nicht best Practice ist und später sollte ich diese Rechte auf das unbedingt benötigte zurücksetzen.
EC2 Server
Die Anwendung soll erstmal mit dem Docker Setup auf einem EC2 Server laufen.
Mit dem neuen IAM Nutzer wechsele ich zuerst auf die Europa Zone ec-central-1.
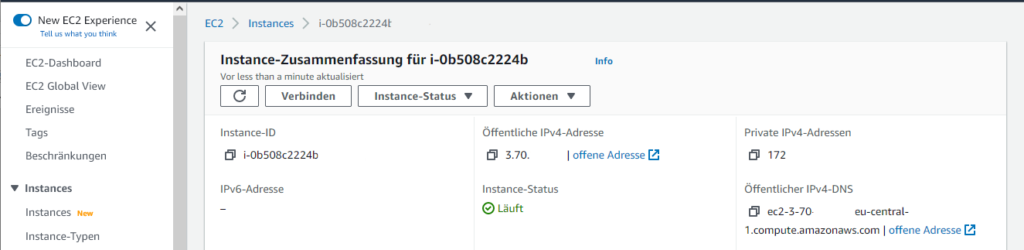
Ich lege eine neue EC2 Server Instanz an, wobei ich als Sparfuchs nach "nur kostenloses Kontingent" filtere und ein AMI für Ubuntu Server 20.04 LTS (x64) und Typ t2.micro auswähle. Es wird ein neues Schlüsselpaar erzeugt und ich speichere den privaten Schlüssel.
Über EC2 > Instances > Server-Instanz auswählen.
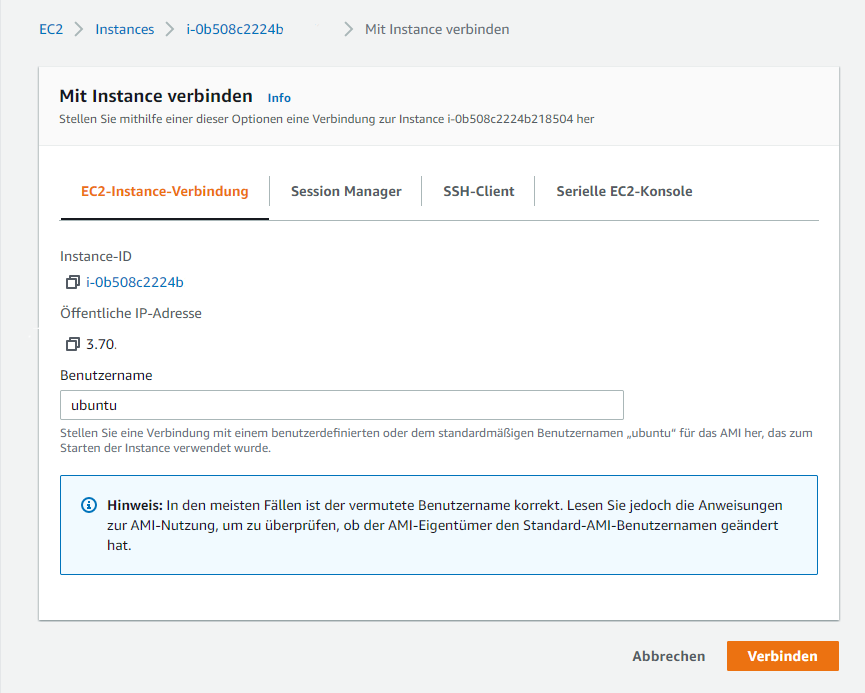
Über Verbinden lässt sich im Browser ein Terminal öffnen. Hier lässt sich aber auch am einfachsten die öffentliche IP und vor allem der Benutzername finden:
Ich habe allerdings nicht die Web Shell verwendet, sondern die Daten, sowie den privaten Schlüssel genommen, um eine Verbindung in WinSCP einzurichten. So kann ich später leicht die Daten auf den Server kopieren und per Klick eine PuTTY-Shell öffnen.
Port Freigabe
Standardmäßig ist für den Server nur Port 22 für SSH frei gegeben.
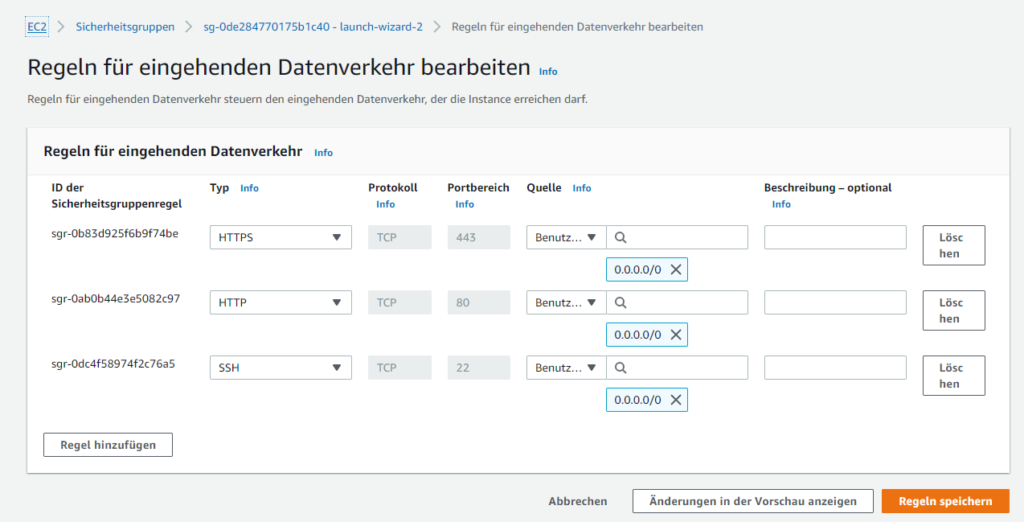
Weitere Ports, wie zB der benötigte HTTP Port 80 oder HTTPS 443, lassen sich über die AWS Management Console frei geben.
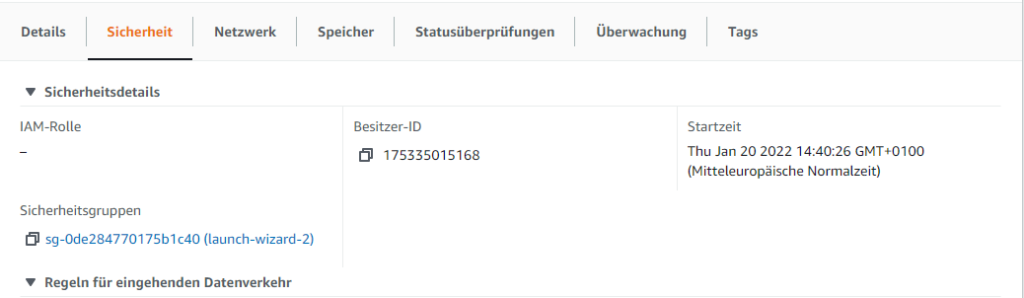
Die EC2-Server-Instanz auswählen und unter Sicherheit findet sich die Sicherheitsgruppe:
In der Sicherheitsgruppe können die Regeln für den eingehenden Datenverkehr erweitert werden. Dabei ist zu beachten, dass man weitere Regeln hinzufügen muss und nicht den bestehenden Typ SSH auf zB HTTP ändert und speichert, weil das diesen nur ändert und nicht als neue, weitere Regel hinzufügt. Dann kann man zwar die Seiten des Webservers bewundern, aber sich nicht mehr per SSH einloggen.
Server einrichten
Auf der Linux Konsole des EC2-Servers wird dieser eingerichtet, dazu wird Docker Compose installiert, was als Abhängigkeit Docker mitbringt.
apt list --upgradable
sudo apt update
sudo apt upgrade -y
sudo apt install docker-compose -y
sudo docker version # -> 20.10.7
sudo docker-compose version # -> 1.25.0
sudo service docker status # -> running
sudo docker run hello-world
Docker läuft und es werden die Daten der Anwendung auf den Server kopiert und anschließend über Docker Compose gestartet.
sudo docker-compose up
Leider führte das zu einem Fehler, wie er schon bei der Ubuntu 18 Installation aufgetreten ist. Das zuvor gewonnene Wissen kann ich jetzt zur schnellen Fehlerbehebung anwenden:
sudo apt-get remove docker-compose -y
sudo curl -L https://github.com/docker/compose/releases/download/v2.2.3/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
docker-compose --version
# Output:
-bash: /usr/bin/docker-compose: No such file or directory
# Lösung: neue Shell, zb per tmux, starten
# und dann nochmals testen
docker-compose --version
# Output:
Docker Compose version v2.2.3
Anschließend ließ sich die Anwendung per Docker Compose starten und per cURL, bzw. HTTPie, über localhost:80 und <öffentlicheIP>:80 aufrufen. Der Aufruf <öffentlicheIP>:80 vom Entwickler Laptop funktioniert auch.
Der Start dauerte etwas länger, die Webanwendung selbst ließ sich anschließend aber angenehm schnell bedienen. Zumindest als Test-Server scheint der "Gratis"-EC2-Server völlig auszureichen.
Ausblick
Auf dem kostenfreien Server laufen ein Tomcat Webserver, eine PostgreSQL Datenbank und PGAdmin und das, zumindest den ersten Tests nach, mit völlig ausreichender Performance.
Als nächstes möchte ich dem Docker Compose Konstrukt noch um einen Reverse Proxy erweitern, der eine (vermutlich nur selbstsignierte) verschlüsselte Verbindung per HTTPS anbietet und über Port 80 und 443 die Anwendung und den PGAdmin erreichbar macht. Außerdem soll es einen einfachen Authentifizierungs- und ggf. Authorisierungsmechanismus geben. Das wird mit einem Apache HTTP Server realisiert werden und sollte keinen besonderen Ressourcenbedarf haben.
Falls sich die Zeit findet, möchte ich das um Keycloak erweitern und den Zugriff auf Anwendung und PGAdmin erst nach erfolgreicher Authentifizierung und Authorisierung erlauben. Vielleicht ist das noch mit dem Apache HTTP Server realisierbar, ggf. werde ich aber auf zB Traefik umstellen. Bei dem Setup kann ich mir schon vorstellen, dass die Ressourcen des kleinen Server nicht mehr ausreichen und es zu spürbaren Performanceeinbrüchen kommen wird.
Eine ansprechendere URL, anstelle der generierten AWS URL, wäre wünschenswert.
Docker Compose Datei vom Entwicklungsrechner auf den Server kopieren, kleinere Anpassungen vornehmen und ausführen. So einfach habe ich es mir vorgestellt, aber es gab dann leider doch noch Herausforderungen zu bewältigen:
Docker Compose Updaten
Ich habe einen Server mit dem nicht mehr ganz taufrischen Ubuntu 18 am laufen und wollte dort ein Docker Compose Skript ausführen.
Das Skript läuft auf meinem Entwicklungsrechner, aber auf dem Server wurde lediglich eine Fehlermeldung ausgegeben:
dockeruser@myServer:~/myproject$ docker-compose up
ERROR: Version in "./docker-compose.yml" is unsupported. You might be seeing this error because you're using the wrong Compose file version. Either specify a supported version (e.g "2.2" or "3.3") and place your service definitions under the `services` key, or omit the `version` key and place your service definitions at the root of the file to use version 1.
For more on the Compose file format versions, see https://docs.docker.com/compose/compose-file/
Wie sich herausstellte, war für Ubuntu 18 bei Docker Compose 1.17.1 Schluss und ich muss händisch upgraden:
Docker Compose entfernen:
sudo apt-get remove docker-compose
Die aktuelle Docker Compose Version ermitteln (heute: 2.2.3): https://github.com/docker/compose/releases
Auf dieser Seite kann man auch den direkten Link zum Download finden, falls es beim ausführen des nächsten Befehls zu Problemen kommt.
Beispielsweise ist die Versionsnummer v2.2.3, also mit einem kleinen "v" am Anfang und wenn das fehlt, schlägt der Download fehl.
So lautet der Link für mein Ubuntu: https://github.com/docker/compose/releases/download/v2.2.3/docker-compose-linux-x86_64
Looks like this is because it defaults to use the secretservice executable which seems to have some sort of X11 dependency for some reason. If you install and configure pass docker will use that instead which seems to solve the problem.
# substitute with the latest version
url=https://github.com/docker/docker-credential-helpers/releases/download/v0.6.4/docker-credential-pass-v0.6.4-amd64.tar.gz
# download and untar the binary
wget $url
tar -xzvf $(basename $url)
# move the binary to a dir in your $PATH
sudo mv docker-credential-pass /usr/local/bin
# verify it works
docker-credential-pass list
# cleanup
rm docker-credential-pass-v0.6.4-amd64.tar.gz
gpg: agent_genkey failed: Keine Berechtigung Schlüsselerzeugung fehlgeschlagen: Keine Berechtigung
Und eine Erklärung mit Lösungsvorschlag findet sich hier:
Expected behavior. Here's why. At the point of failure, gen-key is about to ask the user for a passphrase. For security purposes, rather than using stdin/stdout, it wants to directly open the controlling terminal for the session and use that handle to write the prompt and receive the passphrase. When you use su to switch to some other user, the owner of the controlling terminal device file does not change; it remains associated with the user who actually logged in (i.e. received a real terminal from getty or got a pty from telnet or ssh or whatever). That device file is protected mode 600, so it can't be opened by anyone else.
The solution is to sudo-chown the device file to the user-who-needs-to-gen-the-key before su'ing to that user. Create the key within the su'd environment, then exit back to the original environment. Then, finally, sudo-chown the terminal back to yourself.
Glücklicherweise geht es auch einfacher, indem man einfach das Programm tmux verwendet. 🙂
tmux
# create a gpg2 key
gpg2 --gen-key
# list key information
gpg2 -k
# Copy the key id (from the line labelled [uid]) and do
pass init "whatever key id you have"
Jetzt sollte der Docker Login funktionieren, aber:
Auch wieder kein neues Problem, dass zB bereits hier und hier diskutiert wurde.
mkdir ~/.docker
touch ~/.docker/config.json
# brachte jeweils keine Änderung
/usr/local/bin/docker-credential-pass
# Output:
-bash: /usr/local/bin/docker-credential-pass: Keine Berechtigung
# Erfolg kam mit diesem Befehl:
sudo chmod +x /usr/local/bin/docker-credential-pass
#Zumindest funktioniert dieser Aufruf:
docker-credential-pass list
# Ein weiterer Fehler ließ sich beheben durch:
export GPG_TTY=$(tty)
Ich musste die einzelnen Images per docker pull imagename ziehen, erst danach konnte ich docker-compose ausführen.
Die Konfiguration in Java war für mich jahrelang kein Problem, denn ich durfte mit einem Framework arbeiten, dass die Konfiguration sehr flexibel und komfortabel gelöst hat.
Beispielsweise konnte die URL für ein angebundenes System für die verschiedenen Stages ganz einfach in einer ini-Datei hinterlegt werden:
Diese ini-Datei ist Teil des Java Projekts und liegt im Classpath.
In der ini-Datei sind alle Informationen zu allen Stages zum OtherSystem gespeichert, was ich immer sehr übersichtlich und leicht zu pflegen fand.
Für die laufende Anwendung muss dann lediglich die Stage festgelegt werden, in welcher sie läuft und dann wird die Konfiguration passend zur Stage gezogen. Die Stage kann definiert werden über eine Konfiguration mit der Zuweisung über den HostName, eine System Property (zB im Tomcat definiert) oder über eine lokale Konfigurationsdatei.
Praktisch ist auch die Möglichkeit, über die lokale Konfigurationsdatei einzelne Konfigurationen überschreiben zu können. So ist es beispielsweise möglich, auf dem Entwicklerrechner in der DEV-Stage zu laufen, aber die Verbindung zur PROD DB zu konfigurieren um einen Bug zu reproduzieren.
Das Thema Sicherheit lasse ich bewusst außen vor, denn hier soll es einzig um die Konfiguration gehen.
Als ich dann ein Projekt in einem anderen Kundenkreis startete, und das propritäre Framework nicht mehr verwenden konnte, war ich schon sehr erstaunt, dass es anscheinend keine schlanke, flexible Möglichkeit der Konfiguration im Java SE Umfeld gibt.
Also muss ich selbst etwas basteln, etwas kleines, leichtgewichtiges und trotzdem flexibles.
Anforderung
Von dem Luxus, sämtliche Konfigurationen per Präfix in verschiedenen Dateien im Projekt zu hinterlegen, muss ich mich verabschieden. Statt dessen wird es eine Konfigurationsdatei im Projekt geben, deren Konfiguration dann von außen überschrieben werden muss. Beispielsweise mit den Datenbankverbindungsparametern auf dem PROD Server. Aufgrund der geringeren Komplexität des Projektes ist das aber durchaus ausreichend.
Die im Projekt hinterlegte Standard-Konfiguration soll über eine lokale Konfigurationsdatei überschrieben werden können. Dazu muss eine Umgebungsvariable (System Environment, bzw. System Property) "localconf" gesetzt werden, die auf diese Datei zeigt.
Außerdem sollen einzelne Konfigurationen über Umgebungsvariablen (System Environment, bzw. System Property) gesetzt werden können.
In den Umgebungsvariablen stehen sehr viele Konfigurationen, wie zB JAVA_HOME,TMP, user.name etc., welche nicht direkt mit der Anwendung zu tun haben. Ob diese Werte auch in unserer Anwendungskonfiguration aufgenommen werden sollen, wird über eine Property "config.includeSystemEnvironmentAndProperties" gesteuert.
Umsetzung
Zum Nachlesen dokumentiere ich hier ein paar Schritte aus dem Code, das Ganze soll später auch in einem GitHub Projekt landen.
Zuerst die Properties aus System Environment und System Properties sammeln:
// System Environment
Properties systemEnvironmentProperties = new Properties();
systemEnvironmentProperties.putAll(System.getenv());
// System Properties
Properties systemPropertiesProperties = new Properties();
systemPropertiesProperties.putAll(System.getProperties());
Die BaseProperties / Standard Properties aus dem ClassPath der Anwendung laden, sie müssen unter: /src/main/resources/application.properties gespeichert sein:
String basePropertiesFilename = "application.properties";
Properties baseProperties = new Properties();
try {
InputStream is = Config.class.getClassLoader().getResourceAsStream(basePropertiesFilename);
baseProperties.load(is);
} catch (Exception e) {
logger.error("Could not read {} from ClassLoader", basePropertiesFilename, e);
}
Falls LocalProperties geladen werden sollen, muss der Pfad zu der Datei in der Umgebungsvariablen "localconf" übergeben werden:
String localPropertiesProperty = "localconf";
Properties localProperties = new Properties();
logger.debug("----------------------------------------------------------------------------------");
logger.debug("LocalProperties Path from System Environment: {}", systemEnvironmentProperties.getProperty(localPropertiesProperty));
logger.debug("LocalProperties Path from System Properties: {}", systemPropertiesProperties.getProperty(localPropertiesProperty));
String localPropertiesPath = systemPropertiesProperties.getProperty(localPropertiesProperty) != null ? systemPropertiesProperties.getProperty(localPropertiesProperty) : systemEnvironmentProperties.getProperty(localPropertiesProperty);
if (localPropertiesPath == null) {
logger.debug("LocalProperties Path is not set, skip loading Local Properties");
} else {
logger.debug("Load LocalProperties from {}", localPropertiesPath);
try {
localProperties.load(new FileInputStream(localPropertiesPath));
} catch (Exception e) {
logger.error("Could not read {} from File", localPropertiesPath, e);
}
}
Sollen die Umgebungsvariablen auch übernommen werden:
String includeSystemEnvironmentAndPropertiesProperty = "config.includeSystemEnvironmentAndProperties";
String includeS = Stream.of(
systemPropertiesProperties.getProperty(includeSystemEnvironmentAndPropertiesProperty),
systemEnvironmentProperties.getProperty(includeSystemEnvironmentAndPropertiesProperty),
localProperties.getProperty(includeSystemEnvironmentAndPropertiesProperty),
baseProperties.getProperty(includeSystemEnvironmentAndPropertiesProperty))
.filter(Objects::nonNull)
.findFirst()
.orElse(null);
Boolean include = Boolean.parseBoolean(includeS);
Abschließend alle Properties mergen:
Properties mergedProperties = new Properties();
mergedProperties.putAll(baseProperties);
mergedProperties.putAll(localProperties);
if (include) {
mergedProperties.putAll(systemEnvironmentProperties);
mergedProperties.putAll(systemPropertiesProperties);
} else {
mergedProperties.forEach((key, value) -> {
value = systemEnvironmentProperties.getProperty((String)key, (String)value);
value = systemPropertiesProperties.getProperty((String)key, (String)value);
mergedProperties.setProperty((String)key, (String)value);
});
}
Beispiel
In dem vorherigen Post hatte ich die Konfigurierbarkeit von JPA EntityManagerFactory im Code so gelöst:
import static org.hibernate.cfg.AvailableSettings.SHOW_SQL;
Properties properties = new Properties();
Optional.ofNullable(System.getenv(SHOW_SQL)).ifPresent( value -> properties.put(SHOW_SQL, value));
Optional.ofNullable(System.getenv(JPA_JDBC_URL)).ifPresent( value -> properties.put(JPA_JDBC_URL, value));
Optional.ofNullable(System.getenv(JPA_JDBC_USER)).ifPresent( value -> properties.put(JPA_JDBC_USER, value));
Optional.ofNullable(System.getenv(JPA_JDBC_PASSWORD)).ifPresent( value -> properties.put(JPA_JDBC_PASSWORD, value));
EntityManagerFactory emf = Persistence.createEntityManagerFactory("myapp-persistence-unit", properties);
Das lässt sich jetzt einfacher über die Config lösen:
Zuletzt kochte die Log4J Lücke hoch, so dass man sich mit dem Thema Logging auseinander setzen musste.
Mich betraf der Bug nicht besonders, nach eingehender Analyse stellte sich heraus, dass keines meiner im Betrieb befindlichen Projekte Log4J verwendet. Ein Paar Projekte, die ich jahrelang betreuen durfte, waren betroffen, aber für die bin ich nicht mehr verantwortlich und war nur beratend tätig und habe meine Einschätzung und Handlungsempfehlung abgegeben.
Allerdings trägt das grade in der Entwicklung, aber noch nicht in Betrieb gegangene, Projekt Log4J in sich, so dass das Thema vor dem GoLive angegangen werden muss.
Java Logging
Einen sehr schönen, pragmatischen Einstieg in Java Util Logging habe ich auf Java Code Geeks gefunden.
Das einfachste Beispiel, um einen Ausgabe auf der Console zu erhalten:
package deringo.jpa;
import java.util.logging.Logger;
public class TestMain {
public static void main(String[] args) throws Exception {
Logger logger = Logger.getLogger(TestMain.class.getName());
logger.warning("Dies ist nur ein Test!");
}
}
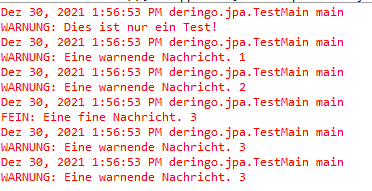
Ein paar Code Beispiele:
package deringo.jpa;
import java.util.logging.ConsoleHandler;
import java.util.logging.Handler;
import java.util.logging.Level;
import java.util.logging.Logger;
public class TestMain {
public static void main(String[] args) throws Exception {
Logger logger = Logger.getLogger(TestMain.class.getName());
logger.warning("Dies ist nur ein Test!");
// Warnung wird ausgegeben, Fine nicht
logger.fine("Eine fine Nachricht. 1");
logger.warning("Eine warnende Nachricht. 1");
// Das Level des Loggers auf ALL setzen
logger.setLevel(Level.ALL);
// Trotzdem: Warnung wird ausgegeben, Fine nicht
logger.fine("Eine fine Nachricht. 2");
logger.warning("Eine warnende Nachricht. 2");
// Einen Handler für den Logger definieren, der Handler Level wird auf ALL gesetzt
Handler consoleHandler = new ConsoleHandler();
consoleHandler.setLevel(Level.ALL);
logger.addHandler(consoleHandler);
// Warnung wird ausgegeben, Fine wird ausgegeben
// ABER: Warnung wird doppelt ausgegeben
logger.fine("Eine fine Nachricht. 3");
logger.warning("Eine warnende Nachricht. 3");
}
}
Überraschend ist erstmal, dass die dritte Ausgabe, zumindest für die Warnung, doppelt erscheint.
Die Erklärung ist, dass es noch einen Root Logger gibt, welcher der Parent des TestMain Loggers ist. Standardmäßig gibt ein Logger seine Einträge an den Parent Logger weiter. Bzw. an die Handler des Parent Loggers. Der Root Logger hat die ersten Logs ausgegeben, als der TestMain Logger noch gar keinen Handler hatte, der die Log Einträge verarbeiten konnte.
Wird die Weitergabe an den Parent Handler deaktiviert, wird nicht mehr doppelt geloggt:
package deringo.jpa;
import java.util.logging.ConsoleHandler;
import java.util.logging.Handler;
import java.util.logging.Level;
import java.util.logging.Logger;
public class TestMain {
public static void main(String[] args) throws Exception {
Logger logger = Logger.getLogger(TestMain.class.getName());
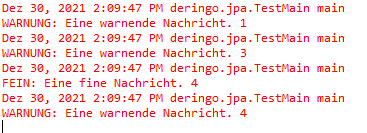
// Warnung wird ausgegeben, Fine nicht
logger.fine("Eine fine Nachricht. 1");
logger.warning("Eine warnende Nachricht. 1");
// Nicht an Parent Handler weiter reichen
logger.setUseParentHandlers(false);
// Warnung wird NICHT mehr ausgegeben, Fine ebenfalls nicht
logger.fine("Eine fine Nachricht. 2");
logger.warning("Eine warnende Nachricht. 2");
// Eigenen Handler definieren
Handler consoleHandler = new ConsoleHandler();
consoleHandler.setLevel(Level.ALL);
logger.addHandler(consoleHandler);
// Warnung wird ausgegeben, Fine wird NICHT ausgegeben
// Warnung wird NICHT doppelt ausgegeben
logger.fine("Eine fine Nachricht. 3");
logger.warning("Eine warnende Nachricht. 3");
// Das Level des Loggers auf ALL setzen
logger.setLevel(Level.ALL);
// Warnung wird ausgegeben, Fine wird ausgegeben
// Warnung wird NICHT doppelt ausgegeben
logger.fine("Eine fine Nachricht. 4");
logger.warning("Eine warnende Nachricht. 4");
}
}
Java Logging - Konfiguration per Datei
Möchte man die Konfiguration des Java Util Loggers nicht per Code, wie oben, vornehmen, sondern per Datei findet sich ein guter Einstieg auf Wikibooks.
Davon abgeleitet meine Konfigurationsdatei logging.properties, die ich in src/main/resources abgelegt habe:
# Der ConsoleHandler gibt die Nachrichten auf std.err aus
#handlers= java.util.logging.ConsoleHandler
# Alternativ können weitere Handler hinzugenommen werden. Hier z.B. der Filehandler
handlers= java.util.logging.FileHandler, java.util.logging.ConsoleHandler
# Festlegen des Standard Loglevels
.level= INFO
############################################################
# Handler specific properties.
# Describes specific configuration info for Handlers.
############################################################
# Die Nachrichten in eine Datei im Benutzerverzeichnis schreiben
java.util.logging.FileHandler.pattern = d:/java%u.log
java.util.logging.FileHandler.limit = 50000
java.util.logging.FileHandler.count = 1
java.util.logging.FileHandler.formatter = java.util.logging.XMLFormatter
java.util.logging.FileHandler.level = ALL
# Zusätzlich zu den normalen Logleveln kann für jeden Handler noch ein eigener Filter
# vergeben werden. Das ist nützlich wenn beispielsweise alle Nachrichten auf der Konsole ausgeben werden sollen
# aber nur ab INFO in das Logfile geschrieben werden soll.
java.util.logging.ConsoleHandler.level = ALL
java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter
############################################################
# Extraeinstellungen für einzelne Logger
############################################################
# Für einzelne Logger kann ein eigenes Loglevel festgelegt werden.
deringo.jpa.TestMain.level = FINEST
Leider funktionierte es nicht. Es wird nach wie vor die originale logging.properties von Java genommen, die im Java Installationsverzeichnis $JAVA_HOME/jre unterhalb des lib Verzeichnises liegt, bzw. ab Java 9 in $JAVA_HOME/conf. Vgl. Mkyong
Falls nicht die Original-logging.properties-Datei benutzt werden soll, kann über die System-Property java.util.logging.config.file die stattdessen zu verwendende Datei angegeben werden.
Wie das praktisch geht, kann bei Mkyong nachgesehen werden.
Ich habe folgenden Code verwendet:
package deringo.jpa;
import java.util.logging.Logger;
public class TestMain {
public static void main(String[] args) throws Exception {
String path = TestMain.class.getClassLoader().getResource("logging.properties").getFile();
System.setProperty("java.util.logging.config.file", path);
Logger logger = Logger.getLogger(TestMain.class.getName());
// Warnung wird ausgegeben, Fine wird ausgegeben
// Beides auf der Console und in der Datei D:/java0.log
logger.fine("Eine fine Nachricht. 1");
logger.warning("Eine warnende Nachricht. 1");
}
}
Es wird in der Console und der definierten Datei geloggt.
Warum die logging.properties des Projektes nicht standartmäßig anstelle der Java logging.properties gezogen wird, kann ich mir nicht erklären.
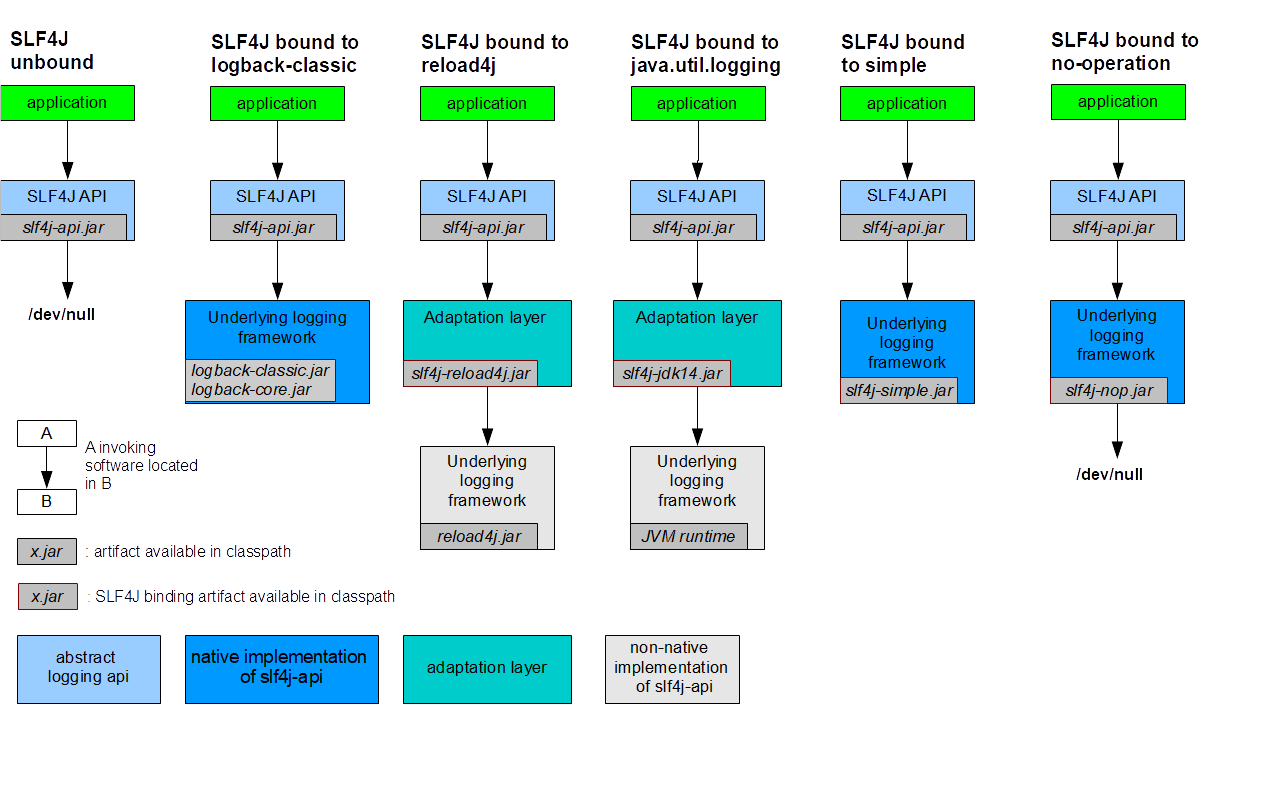
SLF4J
SLF4J ist kein Logging Framework, sondern eine Fassade vor der eigentlichen Implementierung. Man kann also im Code mit SLF4J loggen und SLF4J leitet das dann an das gewählte Framework, zB Java Util Logging oder Log4J weiter. So kann man das Logging Framework austauschen ohne den Code anfassen zu müssen.
Ob das jemals jemand vor dem Log4J Bug gemacht hat lasse ich mal dahingestellt, mir gefällt aber das eingebaute Templating, bzw. Parameterisierung, von SLF4J:
Object entry = new SomeObject();
logger.debug("The entry is {}.", entry);
package deringo.jpa.repository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SLF4JTest {
public static void main(String[] args) {
Logger logger = LoggerFactory.getLogger(SLF4JTest.class);
logger.info("Hallo Welt!");
}
}
Folgende Grafik aus dem SLF4J Manual zeigt, dass nach /dev/null geloggt wurde:
Es wird also eine Logging Framework Implementierung benötigt.
Ich entscheide mich für das Java Util Logging Framework, denn dieses ist in Java bereits enthalten und ich muss keine weitere Bibliothek, wie zB Log4J, in mein Projekt einbinden.
Es kommt also eine weitere Maven Abhängigkeit hinzu:
package deringo.jpa.repository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SLF4JTest {
public static void main(String[] args) {
Logger logger = LoggerFactory.getLogger(SLF4JTest.class);
logger.info("Hallo Welt!");
}
}
Führt jetzt zu folgender Ausgabe:
Äquivalent zu dem Code Beispiel zu Java Util Logging - Konfiguration per Datei weiter oben, führt folgender Code zusätzlich zu einem Logging in einer Datei:
package deringo.jpa.repository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SLF4JTest {
public static void main(String[] args) {
String path = SLF4JTest.class.getClassLoader().getResource("logging.properties").getFile();
System.setProperty("java.util.logging.config.file", path);
Logger logger = LoggerFactory.getLogger(SLF4JTest.class);
logger.info("Hallo Welt!");
}
}
Mein Ziel war es, JPA konfigurativ ohne persistence.xml zu verwenden. Das habe ich nicht ganz geschafft, aber schon mal den Weg erarbeitet, wie es prinzipiell funktionieren könnte.
Hintergrund ist einfach der, dass ich in der persistence.xml die Konfiguration meiner Datenbank hinterlegen kann, aber wenn ich das war-File baue und auf den produktiven Server schiebe, dann möchte ich, dass diese Konfiguration durch die der produktiven Datenbank überschrieben werden kann.
Nach meiner Mittagspause hat sich der Test auf einmal anders verhalten und es wurde kein NoClassDefFoundError geschmissen, sondern ein ExceptionInInizlialisationError. Warum dem so ist 🤷♂️.
Beide Errors erweitern allerdings den LinkageError, also ist mein Test fix gefixt:
Bisher habe ich für den Datenbankzugriff mit einem proprietärem Framework gearbeitet, das ich jedoch für das aktuelle Projekt nicht verwenden kann. Bei der Wahl einer frei zugänglichen Alternative entschied ich mich für JPA, die Java/Jakarta Persistence API.
Die Datenbank
Als Datenbank benutze ich einfach das Setup aus meinem letzten Post.
Projekt Setup
Es wird ein neues Maven Projekt angelegt. Java Version 1.8.
Es wird die Javax Persistence API benötigt und eine Implementierung, hier: Hibernate. Als DB wird PostgreSQL verwendet, dazu wird der entsprechende Treiber benötigt.
Die beiden Tabellen Adresse und Person werden jeweils in eine Java Klasse überführt. Dabei handelt es sich um POJOs mit Default Constructor, (generierter) toString, hashCode und equals Methoden. Annotation als Entity und für die ID, die uA objectID heißen soll und nicht wie in der DB object_id.
package deringo.jpa.entity;
import java.io.Serializable;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Adresse implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "object_id")
private int objectID;
private String strasse;
private String ort;
public Adresse() {
// default constructor
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + objectID;
result = prime * result + ((ort == null) ? 0 : ort.hashCode());
result = prime * result + ((strasse == null) ? 0 : strasse.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Adresse other = (Adresse) obj;
if (objectID != other.objectID)
return false;
if (ort == null) {
if (other.ort != null)
return false;
} else if (!ort.equals(other.ort))
return false;
if (strasse == null) {
if (other.strasse != null)
return false;
} else if (!strasse.equals(other.strasse))
return false;
return true;
}
@Override
public String toString() {
return String.format("Adresse [objectID=%s, strasse=%s, ort=%s]", objectID, strasse, ort);
}
public int getObjectID() {
return objectID;
}
public void setObjectID(int objectID) {
this.objectID = objectID;
}
public String getStrasse() {
return strasse;
}
public void setStrasse(String strasse) {
this.strasse = strasse;
}
public String getOrt() {
return ort;
}
public void setOrt(String ort) {
this.ort = ort;
}
}
Für den Zugriff auf die Tabellen werden die jeweiligen Repository Klassen angelegt.
package deringo.jpa.repository;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
import deringo.jpa.entity.Adresse;
public class AdresseRepository {
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("myapp-persistence-unit");
public static Adresse getAdresseById(int id) {
EntityManager em = emf.createEntityManager();
return em.find(Adresse.class, id);
}
}
"Geschäftslogik" um zu testen, ob es funktioniert:
package deringo.jpa;
import deringo.jpa.entity.Adresse;
import deringo.jpa.repository.AdresseRepository;
public class TestMain {
public static void main(String[] args) {
int adresseID = 4;
Adresse adresse = AdresseRepository.getAdresseById(adresseID);
System.out.println(adresse);
}
}
Test Driven
Den Zugriff über die Repositories (und später auch Service Klassen) habe ich Test Driven entwickelt mit JUnit. Zur Entwicklung mit JUnit hatte ich schon mal einen Post verfasst.
Folgende Dependencies wurden der pom.xml hinzugefügt:
public static List<Adresse> getAdresseByOrt(String ort) {
EntityManager em = emf.createEntityManager();
TypedQuery<Adresse> query = em.createQuery("SELECT a FROM Adresse a WHERE a.ort = :ort", Adresse.class);
query.setParameter("ort", ort);
return query.getResultList();
}
Native Query
Um zB herauszufinden, wie die zuletzt vergebene ObjectID lautet, kann ein native Query verwendet werden:
public static int getLastObjectID() {
String sequenceName = "public.object_id_seq";
String sql = "SELECT s.last_value FROM " + sequenceName + " s";
EntityManager em = emf.createEntityManager();
BigInteger value = (BigInteger)em.createNativeQuery(sql).getSingleResult();
return value.intValue();
}
Kreuztabelle
Nehmen wir mal an, eine Person kann mehrere Adressen haben und an eine Adresse können mehrere Personen gemeldet sein.
Um das abzubilden benötigen wir zunächst eine Kreuztabelle, die wir in der DB anlegen:
DROP TABLE IF EXISTS public.adresse_person;
CREATE TABLE public.adresse_person (
adresse_object_id integer NOT NULL,
person_object_id integer NOT NULL
);
Solch eine Relation programmatisch anlegen:
public static void createAdressePersonRelation(int adresseId, int personId) {
String sql = "INSERT INTO adresse_person (adresse_object_id, person_object_id) VALUES (?, ?)";//, adresseId, personId);
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
em.createNativeQuery(sql)
.setParameter(1, adresseId)
.setParameter(2, personId)
.executeUpdate();
em.getTransaction().commit();
}
Die Adresse zu einer Person(enID) lässt sich ermitteln:
Das funktioniert nur, solange die Person nur eine Adresse hat.
Das kann man so machen, schöner ist es aber über entsprechend ausmodellierte ManyToMany Beziehungen in den Entities. Das Beispiel vervollständige ich hier erstmal nicht, da ich bisher es in meinem Projekt nur so wie oben beschrieben benötigte.
OneToMany
Wandeln wir obiges Beispiel mal ab: An einer Adresse können mehrere Personen gemeldet sein, aber eine Person immer nur an einer Adresse.
Wir fügen also der Person eine zusätzliche Spalte für die Adresse hinzu:
ALTER TABLE person ADD COLUMN adresse_object_id integer;
--
UPDATE person SET adresse_object_id = 4
public class Person implements Serializable {
[...]
@ManyToOne
@JoinColumn(name="adresse_object_id")
private Adresse adresse;
[...]
}
public class Adresse implements Serializable {
[..]
@OneToMany
@JoinColumn(name="adresse_object_id")
private List<Person> personen = new ArrayList<>();
[...]
}
Anschließend noch die Getter&Setter, toString, hashCode&equals neu generieren und einen Test ausführen:
Es soll das Objekt adresse ausgegeben werden, in welchem in der toString-Methode das Objekt person ausgegeben werden soll, in welchem das Objekt adresse ausgegeben werden, in welchem in der toString-Methode das Objekt person ausgegeben werden soll, in welchem das Objekt adresse ... usw.
Als Lösung muss die toString-Methode von Person händisch angepasst werden, so dass nicht mehr das Objekt adresse, sondern lediglich dessen ID ausgegeben wird:
Man möchte meinen, dass der Code zum löschen einer Adresse wie folgt lautet:
public static void deleteAdresse(Adresse adresse) {
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
em.remove(adresse);
em.getTransaction().commit();
}
Testen:
@Test
public void deleteAdresse() {
int adresseID = 8;
Adresse adresse = AdresseRepository.getAdresseById(adresseID);
assertNotNull(adresse);
AdresseRepository.deleteAdresse(adresse);
assertNull(adresse);
}
Der Test schlägt fehl mit der Nachricht: "Removing a detached instance".
Das Problem besteht darin, dass die Adresse zuerst über einen EntityManager gezogen wird, aber das Löschen in einem anderen EntityManager, bzw. dessen neuer Transaktion, erfolgen soll. Dadurch ist die Entität detached und muss erst wieder hinzugefügt werden, um sie schließlich löschen zu können:
public static void deleteAdresse(Adresse adresse) {
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
em.remove(em.contains(adresse) ? adresse : em.merge(adresse));
em.getTransaction().commit();
}
Im vorletzten Post: PostgreSQL hatte ich beschrieben, wie ich zwei Bestandsdatenbanken analysiert und in eine PostgreSQL-DB in einem Docker Container gebracht habe, samt PGAdmin.
Jetzt möchte ich einen Schritt weiter gehen und das komplette Setup über ein Script starten können: DB, PGAdmin & SQL-Scripte. Dazu verwende ich Docker-Compose.
Ausgangslage
In PostgreSQL hatte ich bereits die zugrundeliegenden Docker-Images ermittelt: postgres:13.4-buster für die DB und dpage/pgadmin4 für PGAdmin. Inzwischen gibt es aber ein aktuelleres Image für die DB, das ich verwenden werde: postgres:13.5-bullseye
Für die SQL-Daten werde ich auf den Artikel PostgreSQL IDs zurückgreifen und daraus zwei Scripte machen, eines für das Schema der DB und eines mit den "Masterdaten" mit denen das Schema initial befüllt werden soll.
CREATE SEQUENCE object_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
CREATE TABLE person (
object_id integer NOT NULL DEFAULT nextval('object_id_seq'::regclass),
vorname varchar(255),
nachname varchar(255),
CONSTRAINT person_pkey PRIMARY KEY (object_id)
);
CREATE TABLE adresse (
object_id integer NOT NULL DEFAULT nextval('object_id_seq'::regclass),
strasse varchar(255),
ort varchar(255),
CONSTRAINT adresse_pkey PRIMARY KEY (object_id)
);
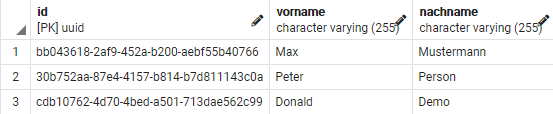
INSERT INTO person (vorname, nachname) VALUES ('Max', 'Mustermann');
INSERT INTO person (vorname, nachname) VALUES ('Peter', 'Person');
INSERT INTO person (vorname, nachname) VALUES ('Donald', 'Demo');
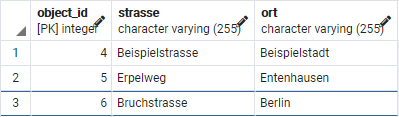
INSERT INTO adresse (strasse, ort) VALUES ('Beispielstrasse', 'Beispielstadt');
INSERT INTO adresse (strasse, ort) VALUES ('Erpelweg', 'Entenhausen');
INSERT INTO adresse (strasse, ort) VALUES ('Bruchstrasse', 'Berlin');
Auf der Seite von Docker Compose bringe ich in Erfahrung, dass die aktuelle Version von Docker Compose 3.9 ist und erstelle schon mal die Datei:
version: "3.9" # optional since v1.27.0
Ordernstrucktur:
Images starten
Bisher habe ich PostgreSQL und PGAdmin über folgende Kommandos gestartet:
docker run --name myapp-db -p 5432:5432 -e POSTGRES_PASSWORD=PASSWORD -d postgres:13.4-buster
Jetzt können beide Images mit einem einfachen Befehl gestartet werden:
\myapp> docker-compose up
Creating network "myapp_default" with the default driver
Creating myapp_myapp-db_1 ... done
Creating myapp_myapp-pgadmin_1 ... done
Attaching to myapp_myapp-db_1, myapp_myapp-pgadmin_1
PGAdmin im Browser starten: http://localhost:80 Login wie bisher mit admin@admin.com / admin
Im nächsten Schritt gibt es bereits eine entscheidende Änderung: Während bisher beide Container isoliert nebeneinander liefen und nur über den Host-Rechner kommunizieren konnten, wurde durch Docker-Compose automatisch beim Start ein Netzwerk ("myapp_default") angelegt, in dem beide Container laufen. Außerdem sind beide Container über ihren Servicenamen ("myapp-db" & "myapp-pgadmin") erreichbar.
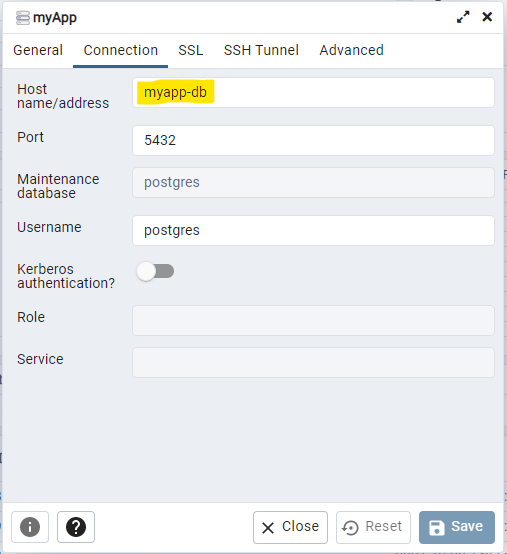
Dadurch muss nicht mehr die IP des Host-Rechners ermittelt werden (die sich manchmal ändert), sondern es kann der Name genommen werden:
Datenbank erstellen
In der PostgreSQL Instanz muss jetzt eine Datenbank erzeugt werden, in der die Anwendungsdaten gespeichert werden.
Hierzu gehen wir in den DB Container. Allerdings ist der Name anders als bisher: Es wurde der Verzeichnisname als Präfix davor und eine 1 (für die 1. und in unserem Fall einzige Instanz) als Postfix dahinter gehangen und so lautet der Name : myapp_myapp-db_1
docker exec -it myapp_myapp-db_1 bash
Im Container erzeugen wir die DB:
su postgres
createdb myappdb
exit
So war es zumindest bisher, einfacher geht es mit Docker-Compose und dem Setzten der Environment-Variablen POSTGRES_DB wodurch die DB automatisch angelegt und verwendet wird. Sicherlich hätte ich das auch bisher im Docker Kommando so nehmen können, aber im letzten Post hatte ich es zum einen mit zwei DBs zu tun und zum anderen musste ich eh auf die Kommandozeile um die DBs einzuspielen.
Einfacher geht es über Docker-Compose und den Mechanismus, dass PostgreSQL automatisch die Dateien importiert, die im Verzeichnis /docker-entrypoint-initdb.d/ liegen. Und zwar in alphabetischer Reihenfolge.
Während der Entwicklung öfters mal die DB platt macht und komplett neu aufsetzt: Mit Docker ist das schnell gemacht. Mit Docker-Compose sind es jetzt nur noch zwei Befehle:
# stop and remove stopped containers
docker-compose down
# start containers
docker-compose up
Einen Nachteil gibt es allerdings: Die Einstellungen im PGAdmin gehen ebenfalls flöten und müssen neu eingegeben werden. Die Lösung: Der PGAdmin Container bekommt ein persistentes Volume, das ein docker-compose down übersteht. Und wenn es doch mal neu aufgesetzt werden muss, ist das einfach über das -v Flag umsetzbar: docker-compose down -v
An Schema und Stammdaten wird sich erstmal nichts ändern. Daher wäre es gut, wenn beim Neubau der Container die DB bereits mit Schema und Stammdaten gestartet wird und nicht diese erst aufbauen muss.
Das wird dadurch erreicht, dass ein Image gebaut wird, dass die PostgreSQL DB sowie Schema und Stammdaten enthält.
Im Verzeichnis database wird eine Datei Dockerfile angelegt. Dieses Dockerfile enthält die Informationen zum Bau des DB Images.
Sollte es erforderlich sein, das Image neu zu bauen, zB wenn ich das Schema verändert hat:
docker-compose up --build
# or
docker-compose build
UPDATE: Das war leider nix mit dem vorgefüllten Image
Das Dockerfile enthält zwar den Schritt die SQL Dateien in das Image zu kopieren. Es fehlt aber der Schritt, bei dem diese Dateien in die Datenbank hineinmigriert werden. Das geschieht wie zuvor auch erst beim Starten des Containers. Mein Ziel, einen Image zu haben, dass diese Daten bereits enthält, habe ich damit also leider nicht erreicht. Das Dockerfile enthält keine Informationen, die nicht zuvor auch schon im Docker Compose enthalten waren.
Da mich das herumkaspern mit diesem Problem heute den ganzen Tag gekostet und abgesehen vom Erkenntnisgewinn leider nichts gebracht hat, kehre ich zur Docker Compose Variante zurück, bei der die DB beim Starten des Containers gebaut wird. Für das Beispiel auf dieser Seite macht das praktisch gesehen keinen Unterschied, da die Scripte winzig sind. Für mein Projekt leider schon, da benötigt der Aufbau der DB ein paar Minuten. Für die Anwendungsentwicklung, bei der ich die DB alle paar Tage mal neu aufsetze, ist das durchaus OK. Für Tests, die mit einer frischen DB starten sollen, die am Ende weggeschmissen wird, ist das schon ein Problem.
Also Rückkehr zu Docker Compose, diesmal mit einem extra Volume für die DB. Das kann ich dann gezielt löschen.
# Create and start containers
docker-compose up
# Image neu bauen
docker-compose up --build
# or
docker-compose build
# Stop containers
docker-compose stop
# Start containers
docker-compose start
# Stop containers and remove them
docker-compose down
# Stop containers, remove them and remove volumes
docker-compose down -v
CREATE TABLE person (
vorname varchar(255),
nachname varchar(255)
);
Diese Personen sollen alle eine eindeutige ID bekommen und diese soll automatisch beim Einfügen generiert werden.
Sequenz
Dazu kann man eine Sequenz anlegen und aus dieser die ID befüllen:
CREATE SEQUENCE person_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
CREATE TABLE person (
id integer NOT NULL DEFAULT nextval('person_id_seq'::regclass),
vorname varchar(255),
nachname varchar(255),
CONSTRAINT person_pkey PRIMARY KEY (id)
);
Anschließend ein paar Personen hinzufügen:
INSERT INTO person (vorname, nachname) VALUES ('Max', 'Mustermann');
INSERT INTO person (vorname, nachname) VALUES ('Peter', 'Person');
INSERT INTO person (vorname, nachname) VALUES ('Donald', 'Demo');
Und anzeigen lassen:
SELECT * FROM person;
Identity
Da es etwas lästig ist, immer für jede Tabelle jeweils eine eigene Sequenz anlegen und mit der ID verknüpfen zu müssen, wurde die Frage an mich herangetragen, ob es da nicht soetwas wie autoincrement gäbe, wie man es von MySQL kennen würde.
Nach kurze Recherche fand sich, dass es soetwas natürlich auch für PostgreSQL gibt und zwar seit der Version 10 als "IDENTITY".
CREATE TABLE adresse (
id int GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
strasse varchar(255),
ort varchar(255)
);
Anschließend ein paar Adressen hinzufügen:
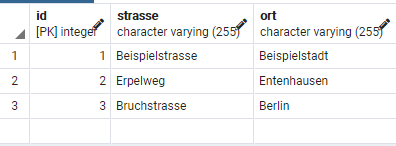
INSERT INTO adresse (strasse, ort) VALUES ('Beispielstrasse', 'Beispielstadt');
INSERT INTO adresse (strasse, ort) VALUES ('Erpelweg', 'Entenhausen');
INSERT INTO adresse (strasse, ort) VALUES ('Bruchstrasse', 'Berlin');
Und anzeigen lassen:
SELECT * FROM adresse;
Der Vorteil der Identity, was man so auf den ersten Blick sieht, ist also, dass man sich etwas stumpfe Tipparbeit spart und keine Sequenz anlegen, mit der ID verknüpfen und die ID als Primary Key definieren muss.
Eine Betrachtung der Unterschiede zwischen SEQUENCE und IDENTITY habe ich leider nicht finden können.
Vermutlich gibt es da keine großen technischen Unterschiede, die IDENTITY scheint mir eine anonyme SEQUENCE zu sein.
Object ID Sequenz
Die IDENTITY kann man nur für einen TABLE nutzen, die SEQUENCE könnte man für mehrere Tabellen nutzen und so eine datenbankweite eindeutige ID verwenden.
Beispielsweise eine eindeutige Object ID Sequenz anlegen und für die Tabellen Person und Adresse verwenden:
CREATE SEQUENCE object_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
CREATE TABLE person (
object_id integer NOT NULL DEFAULT nextval('object_id_seq'::regclass),
vorname varchar(255),
nachname varchar(255),
CONSTRAINT person_pkey PRIMARY KEY (object_id)
);
CREATE TABLE adresse (
object_id integer NOT NULL DEFAULT nextval('object_id_seq'::regclass),
strasse varchar(255),
ort varchar(255),
CONSTRAINT adresse_pkey PRIMARY KEY (object_id)
);
Anschließend ein paar Personen und Adressen hinzufügen:
INSERT INTO person (vorname, nachname) VALUES ('Max', 'Mustermann');
INSERT INTO person (vorname, nachname) VALUES ('Peter', 'Person');
INSERT INTO person (vorname, nachname) VALUES ('Donald', 'Demo');
INSERT INTO adresse (strasse, ort) VALUES ('Beispielstrasse', 'Beispielstadt');
INSERT INTO adresse (strasse, ort) VALUES ('Erpelweg', 'Entenhausen');
INSERT INTO adresse (strasse, ort) VALUES ('Bruchstrasse', 'Berlin');
Und anzeigen lassen:
SELECT * FROM person;
SELECT * FROM adresse;
Wie man sehen kann, wurde die ID fortlaufend über beide Tabellen vergeben. Dadurch erhält man eine datenbankweit eindeutige, fortlaufende ID.
UUID
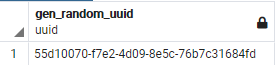
Und weil ich grade schon dabei bin: Seit Version 13 bringt PostgreSQL auch standartmäßig die Möglichkeit einer UUID mit.
Eine UUID ist ein Universally Unique Identifier. Manchmal, typischerweise in Zusammenhang mit Microsoft, wird auch der Ausdruck GUID Globally Unique Identifier verwendet.
SELECT * FROM gen_random_uuid ();
UUIDs sind ebenfalls datenbankweit (und darüber hinaus) eindeutig. Allerdings sind die IDs nicht mehr fortlaufend.
UUIDs sind etwas langsamer als Sequenzen und verbrauchen etwas mehr Speicher.
Das Beispiel von vorhin:
CREATE TABLE person (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
vorname varchar(255),
nachname varchar(255)
);
CREATE TABLE adresse (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
strasse varchar(255),
ort varchar(255)
);
Anschließend ein paar Personen und Adressen hinzufügen:
INSERT INTO person (vorname, nachname) VALUES ('Max', 'Mustermann');
INSERT INTO person (vorname, nachname) VALUES ('Peter', 'Person');
INSERT INTO person (vorname, nachname) VALUES ('Donald', 'Demo');
INSERT INTO adresse (strasse, ort) VALUES ('Beispielstrasse', 'Beispielstadt');
INSERT INTO adresse (strasse, ort) VALUES ('Erpelweg', 'Entenhausen');
INSERT INTO adresse (strasse, ort) VALUES ('Bruchstrasse', 'Berlin');
Für die Neu- und Weiterentwicklung einer Anwendung habe ich zur Analyse die Bestandsanwendung samt Datenbanken bekommen. Für die Analyse musste ich zunächst die Datenbanken zum laufen bekommen und uA mit einem DB-Client einsehen.
Ich habe zum einen eine Datei dump.backup bekommen. Zunächst musste ich herausfinden, um was für eine Datei es sich dabei handelt, dazu nutzte ich das Linux Tool file:
Es handelt sich also um einen Dump einer PostgreSQL Datenbank. Und im Dump konnte ich eine Versionsnummer 13.0 finden.
Die andere Datei mydb.sql.gz beinhaltet eine gezippte Version eines SQL Exports einer PostgreSQL DB Version 13.2 von einem Debian 13.2 Server.
Im Laufe der weiteren Analyse der DB Exporte stellte sich heraus, dass der dump.backup die PostGIS Erweiterung der PostgreSQL DB benötigt, welche mit installiert werden muss.
PostgreSQL Datenbank Docker Image
Ich werde beide Datenbanken in einer Docker Version installieren, dazu werde ich eine DB Instanz starten, in der beide DBs installiert werden.
Da es sich um die Versionsnummer 13.0 und 13.2 handelt, werde ich ein aktuelles Image von Version 13 verwenden, was zum Projektzeitpunkt Version 13.4 war.
Da zumindest eine der beiden DBs auf einem Debian System gehostet ist, werde ich ein Debian Image wählen.
Die Wahl des Images fällt also auf: postgres:13.4-buster
Datenbank installieren
Zuerst das Docker Image ziehen:
docker pull postgres:13.4-buster
Datenbank starten:
docker run --name myapp-db -p 5432:5432 -e POSTGRES_PASSWORD=PASSWORD -d postgres:13.4-buster
DB-Dateien in den laufenden Docker Container kopieren:
su postgres
createdb mydb_dump
pg_restore -d mydb_dump -v /tmp/dump.backup
exit
DB von SQL erstellen:
su postgres
cd /tmp
gunzip mydb.sql.gz
createdb mydb_sql
pg_restore -d mydb_sql -v /tmp/mydb.sql
exit
Die Datenbanken sind installiert und es kann mittels eines letzten exit der Container verlassen werden.
DB Client PGAdmin installieren
Um in die Datenbanken hinein sehen zu können wird ein Client Programm benötigt. Sicherlich es gibt da bereits etwas auf der CommandLine Ebene:
su postgres
psql mydb_sql
Übersichtlich oder komfortabel ist das aber nicht. Daher möchte ich ein Tool mit einer grafischen Oberfläche verwenden. Die Wahl fiel auf pgAdmin, welches sich leicht von einem Docker Image installieren und anschließend über den Browser bedienen lässt.
Für die Konfiguration für die Verbindung zur zuvor gestarteten PostgreSQL Datenbank benötige ich die IP meines Rechners, die ich mittels ipconfig herausfinden kann.
Das Starten des Tomcat-Servers hat für ein Projekt sehr lange gedauert. Im Eclipse kann man die Zeit bis zum Timeout hoch setzen, den Nerven des Entwicklers hilft das aber nur bedingt.
Eine Ursache für die lange Startzeit liegt darin, dass der Tomcat-Server beim Start alle jar-Files nach Taglibs durchsucht. Das Projekt hat sehr viele Libraries.
Eine Abhilfe schafft hier die Konfiguration, dass Tomcat keine jar-Files scannen soll, außer denen, in denen eine Taglib enthalten ist.
Wie man Jars mit Taglibs findet
Tomcat kann anzeigen lassen, welche Jars, die beim Start gescannt werden, Taglibs enthalten. Dazu muss das entsprechende Log-Level gesetzt werden.
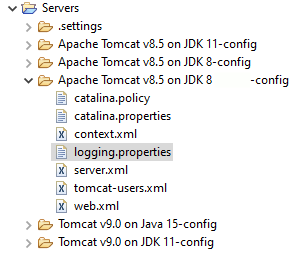
In meinem Fall musste ich lediglich die logging.properties aus dem Original-Tomcat Verzeichnis in das Verzeichnis des Eclipse Tomcats kopieren:
Am Ende der logging.properties das Log-Level für den TLDScanner setzen:
[...]
org.apache.jasper.compiler.TldLocationsCache.level = FINE
org.apache.jasper.servlet.TldScanner.level = FINE
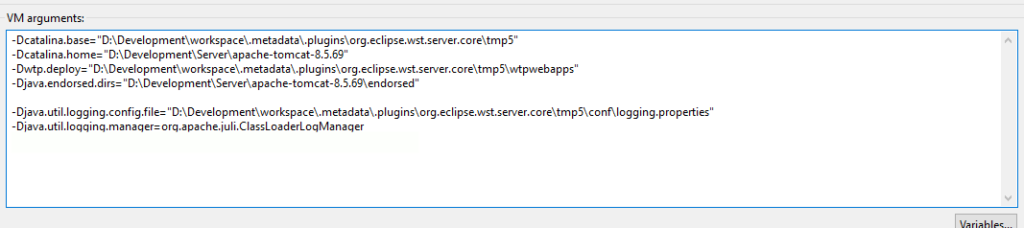
In den VM Arguments des Tomcats muss der Pfad zur logging.properties angegeben werden:
Beim Start wird jetzt angezeigt, in welchen JARs TLDs zu gefunden wurden.
Wie nur noch ausgewählte JARs gescannt werden
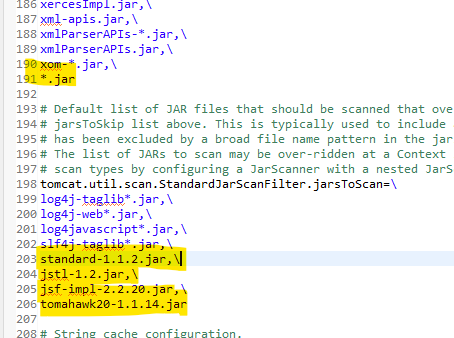
In aktuellen Projekt wurden folgende JARs mit TLDs gefunden:
standard-1.1.2.jar
jstl-1.2.jar
jsf-impl-2.2.20.jar
tomahawk20-1.1.14.jar
Die Konfiguration des JARScanFilters für den Tomcat Server erfolgt in der catalina.properties Datei.
Bei den jarsToSkip lasse ich alle (*.jar) skippen.
Bei den jarsToScan füge ich obige JARs hinzu:
Alleine durch diese Konfigurationsänderung konnte die Startzeit von 25 Sekunden auf 10 Sekunden reduziert werden.
JarScanner Konfiguration im Projekt
Der obige Weg beschreibt die Konfigurationsänderung im Server. Das hat den Nachteil, dass jede Serverinstanz diese Konfiguration gesetzt bekommen muss. Eine Konfiguration im Projekt selbst hat den Vorteil, dass zB alle Mitentwickler direkt mit profitieren können und nicht erst die Konfiguration selbst setzen müssen.
Die Konfiguration im Projekt erfolgt über context.xml: