Was mir in dem Umfang bisher noch nicht wirklich klar war: Man kann für kleine Icons und dergleichen auch Unicode Zeichen verwenden und braucht so keine Grafiken suchen, bearbeiten oder sich um Copyright Gedanken machen 👏.
Ein Nachteil ist allerdings, dass man die konkrete Darstellung nicht mehr in der Hand hat und die Unicodes in unterschiedlichen Browsern oder Betriebssystemen unterschiedlich aussehen können. In meinem geliebten Notepad++ beispielsweise werden die klatschenden Hände 👏 lediglich in Schwarz-Weiß dargestellt.
Die Unicode Zeichen müssen natürlich erstmal gefunden werden, dafür eignen sich Seiten wie CodePoins oder Unicode-Table.
Dann gibt es auch noch Icon-Bibliotheken wie PrimeIcons oder die vielleicht bekannteste Sammlung Font Awesome.
Darüber hinaus gibt es weitere Möglichkeiten und Bibliotheken, eine interessante Suchmaschine dazu ist GlyphSearch.
Wenn Favicons benötigt werden, kann man diese bequem auf favicon.io online generieren lassen.
Die Basic authentication wurde bei GitHub abgeschaltet.
Ein Commit mit Username & Password ist somit nicht mehr möglich. Statt dessen wird der Username & Personal access token benötigt.
Wie man einen Personal access token generiert und über die Command Line verwendet habe ich bereits hier dokumentiert.
Heute habe ich für eine Code Anpassung mit Eclipse gearbeitet und bin in diese Abschaltungsfalle gerannt. Die Generierung des Personal access tokens war leicht, ich brauchte lediglich meiner eigenen Doku folgen.
Schwieriger (nerviger) war es, Eclipse beizubringen, dass anstelle des alten, gespeicherten Passworts ein neues verwendet werden soll. (der zuvor generierte Token)
Die erste Version, mit der ich erfolgreich war:
How do I change my git credentials in eclipse?
Go to the Git Perspective -> Expand your Project -> Expand Remotes -> Expand the remote you want to save your password. Right-click on the Fetch or Push -> Select Change Credentials Enter username and password -> Select Ok.
Das war wirklich umständlich und schräg, hat aber erstmal zum erfolgreichen Commit verholfen.
Ich habe dann noch ein bisschen weiter geforscht und eine zweite Variante gefunden, die sinnvoller erscheint, aber mit einem Eclipse Neustart bezahlt werden muss:
1. From Eclipse toolbar navigate to Window > Preferences > Security > Secure Storage > Contents Tab > [Default Secure Storage] > GIT > "whatever github url" 2. Select the url and delete the current user. 3. Eclipse will ask for a restart. Do it. 4. Push new changes and this time egit will prompt to save credentials in secure storage which was removed from the previous step.
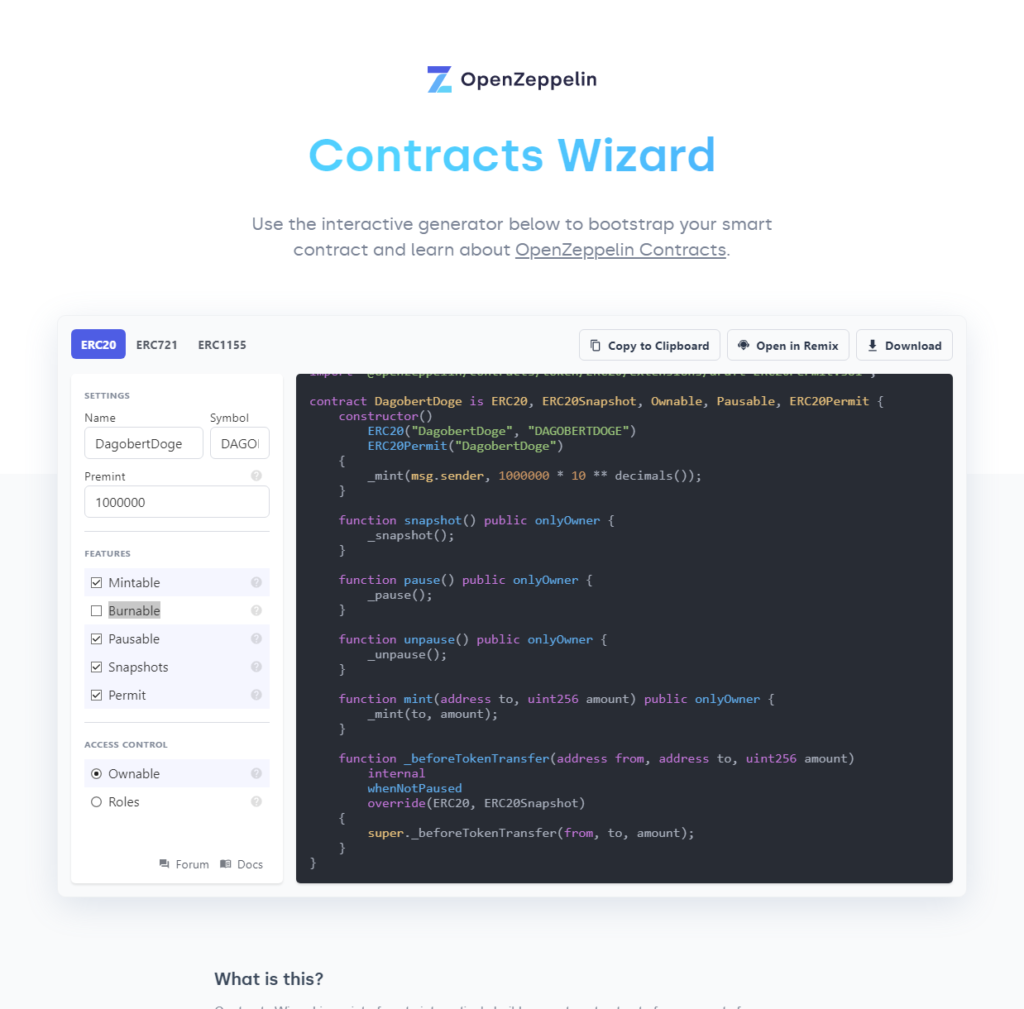
Auf die Seite von dem Wizard gehen, alles anklicken, das wird schon so seine Richtigkeit haben, Name, Symbol und Premint anpassen:
Contract Code sichern
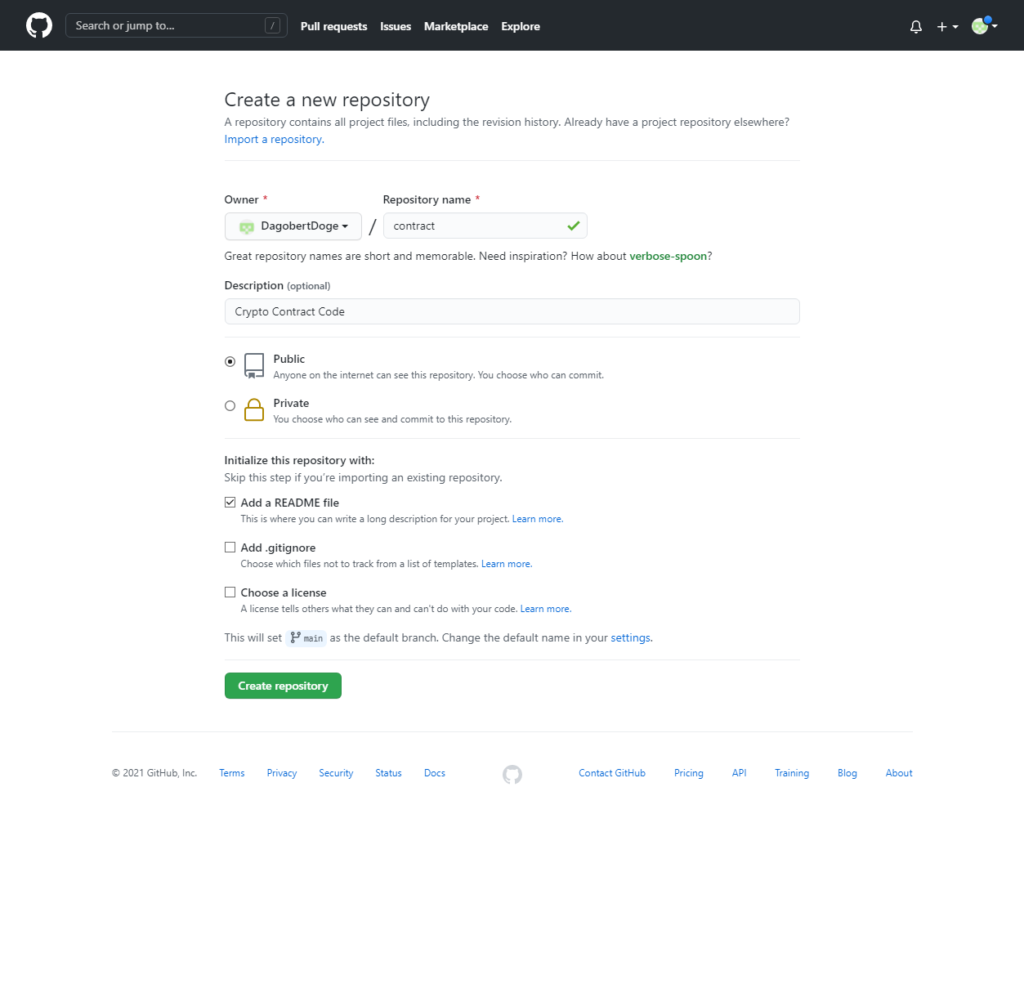
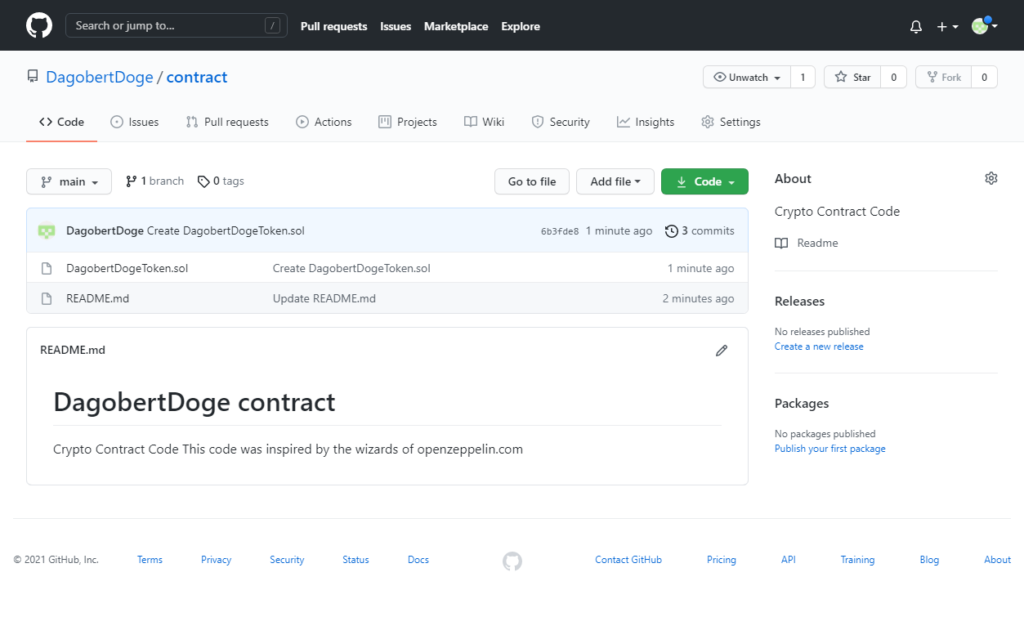
Den so mühsam erarbeiteten Code wollen wir natürlich für die Nachwelt sichern und speichern in in ein eigens dafür angelegtes GitHub Repository:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
import "@openzeppelin/contracts@4.2.0/token/ERC20/ERC20.sol";
import "@openzeppelin/contracts@4.2.0/token/ERC20/extensions/ERC20Snapshot.sol";
import "@openzeppelin/contracts@4.2.0/access/Ownable.sol";
import "@openzeppelin/contracts@4.2.0/security/Pausable.sol";
import "@openzeppelin/contracts@4.2.0/token/ERC20/extensions/draft-ERC20Permit.sol";
contract DagobertDoge is ERC20, ERC20Snapshot, Ownable, Pausable, ERC20Permit {
constructor()
ERC20("DagobertDoge", "DAGOBERTDOGE")
ERC20Permit("DagobertDoge")
{
_mint(msg.sender, 1000000 * 10 ** decimals());
}
function snapshot() public onlyOwner {
_snapshot();
}
function pause() public onlyOwner {
_pause();
}
function unpause() public onlyOwner {
_unpause();
}
function mint(address to, uint256 amount) public onlyOwner {
_mint(to, amount);
}
function _beforeTokenTransfer(address from, address to, uint256 amount)
internal
whenNotPaused
override(ERC20, ERC20Snapshot)
{
super._beforeTokenTransfer(from, to, amount);
}
}
Der DagobertDoge Token
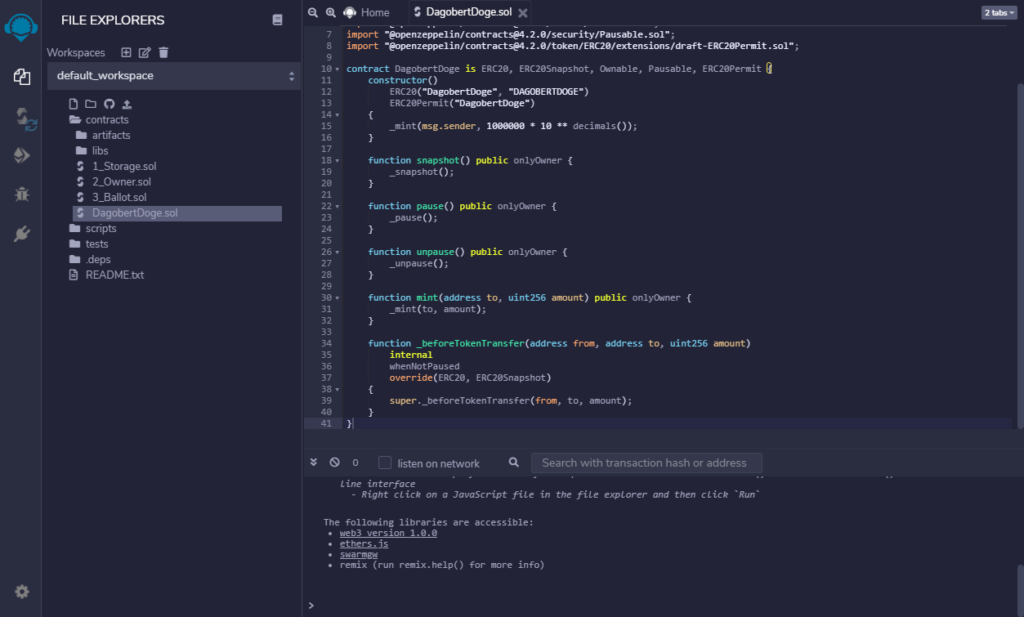
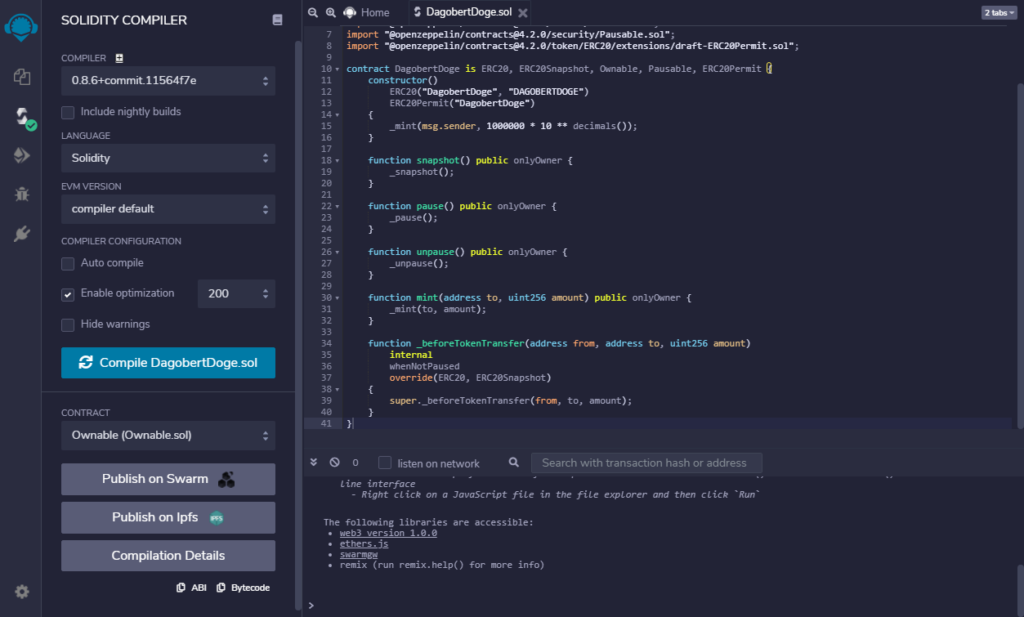
In der Online IDE wird eine neue Contract Datei angelegt und dort der Code gespeichert:
Anschließend wird der Contract compiliert:
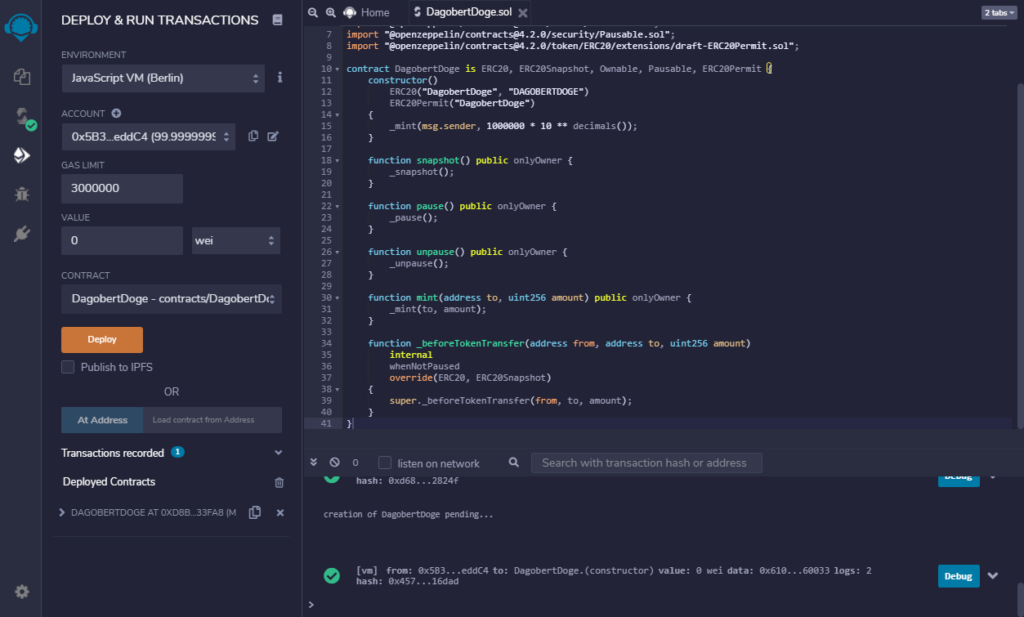
Anschließend wird der Contract (DagobertDoge auswählen) im JavaScript Environment deployed um zu sehen, ob es funktioniert.
Anschließend über Environment Injected Web3 deployen. Dann öffnet sich (zB) das MetaMask Plugin des Browsers und in diesem sollte das BNB Test Netzwerk eingerichtet sein, so dass der Token dann in diesem Test Netzwerk erzeugt wird. Es funktioniert aber auch, wenn man das richtige Smart Chain (BNB) Netzwerk eingerichtet hat.
Da ich grade überlesen habe, dass das Richtige und nicht das Testnetzwerk ausgewählt war, habe ich für 0,077 BNB den DagobertDoge Token erstellt. Glaube ich zumindest. Laut einem Onlineumrechner sind 0,077 BNB ca. 20 Euro:
NACHTRAG: Anscheinend hatte ich mich verguckt; in meiner TrustWallet wird für die Transaktion eine Netzwerkgebühr von 0,00779352 BNB angezeigt, die dort mit 2,74$ bewertet werden.
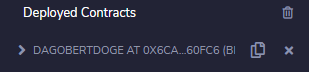
Der DagobertDoge Contract
Die Contract ID des wundervollen DagobertDoge Contracts findet sich nach dem Deployment in der Remix IDE unter Deployed Contracts:
Für ein R&D-Projekt benötige ich eine eigene Domain. Diese soll möglichst günstig zu bekommen sein und das bei einem Anbieter, der eine Bezahlung über Bitcoin oä ermöglicht. Bei der Recherche bin ich dabei auf diesen Anbieter gestoßen: Porkbun
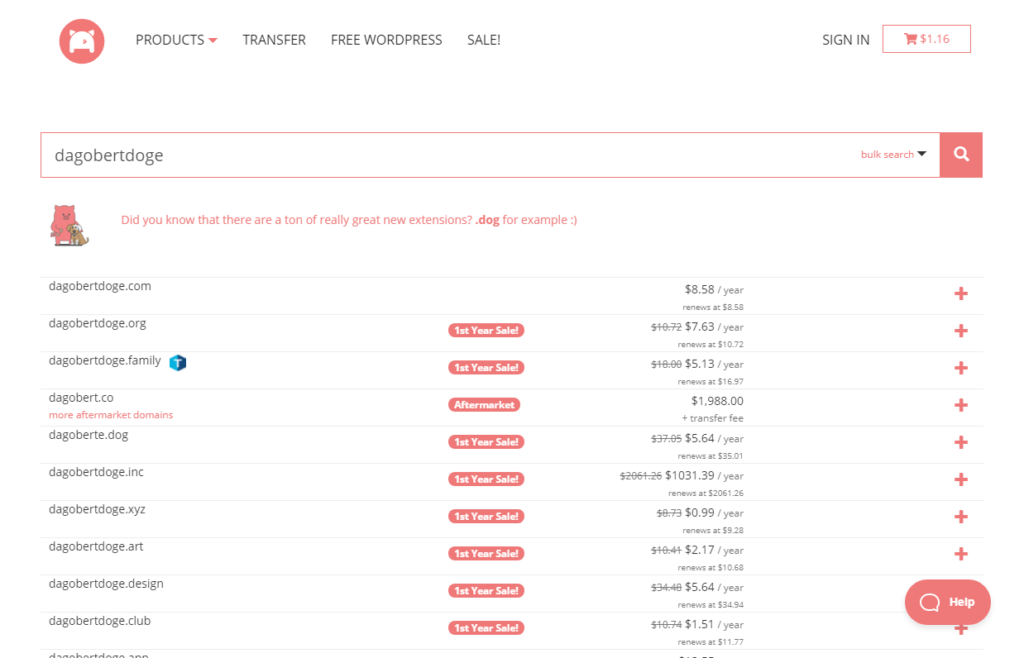
Das Projekt läuft unter dem Arbeitstitel: Dagobert Doge. Also suche ich nach einer entsprechenden Domain:
Es werden einige verfügbare Domains angezeigt:
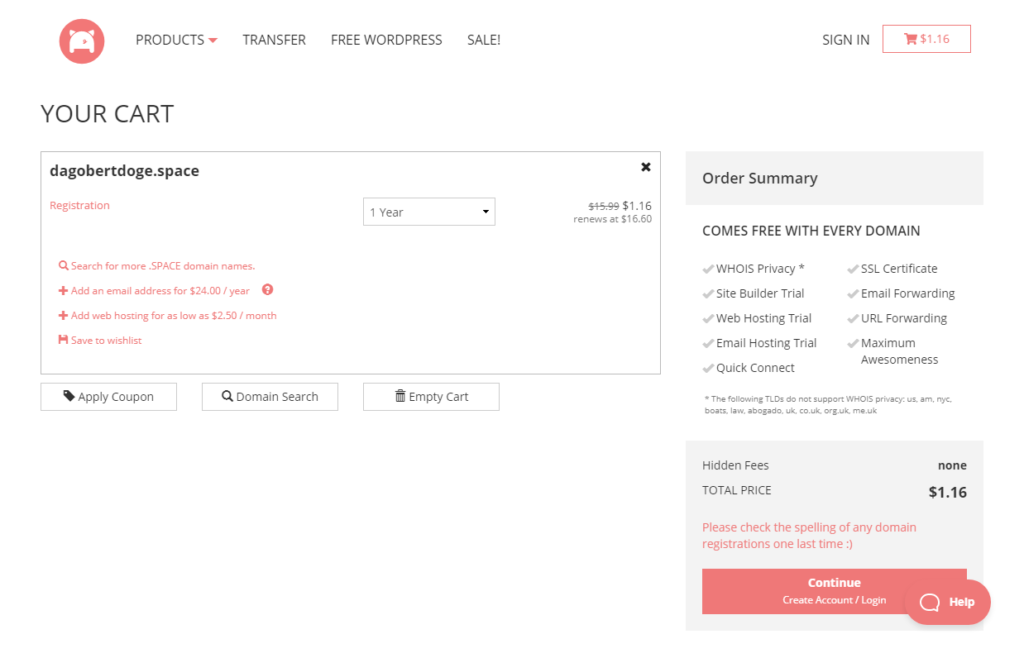
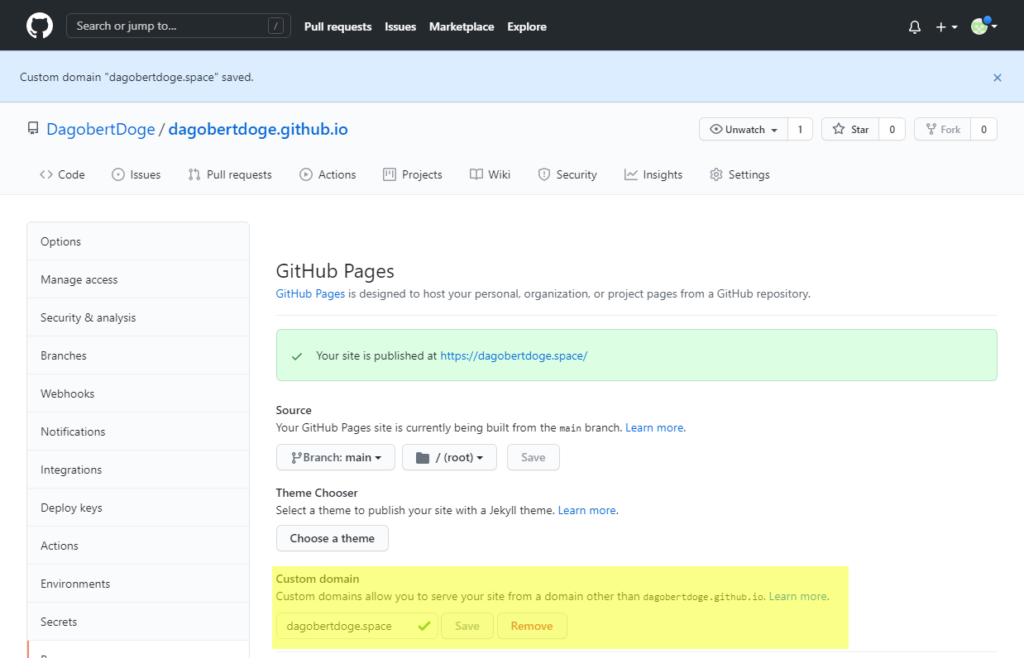
Ich entscheide mich für DagobertDoge.space. Klingt cool und kostet nur 1,16 $ im ersten Jahr:
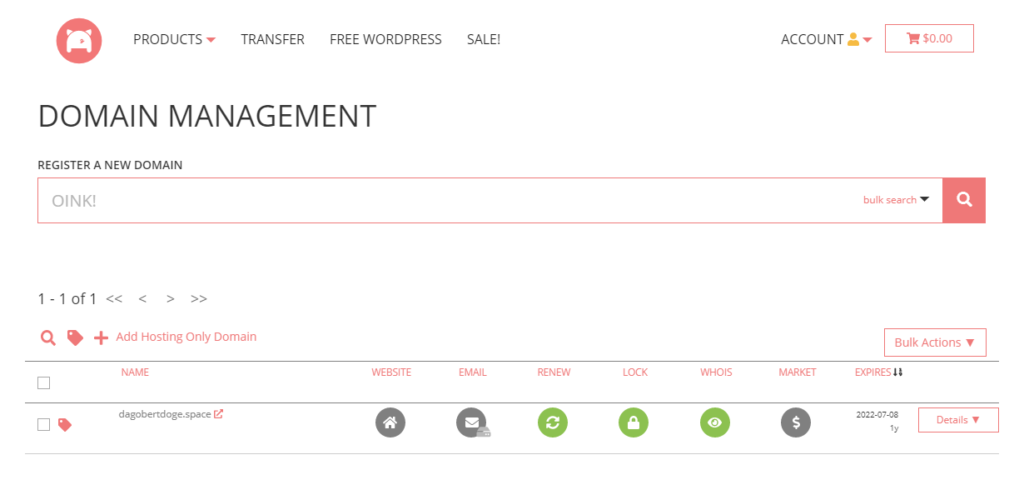
Registrieren, bezahlen und schon erscheint die Domain im Domain Management:
EMail
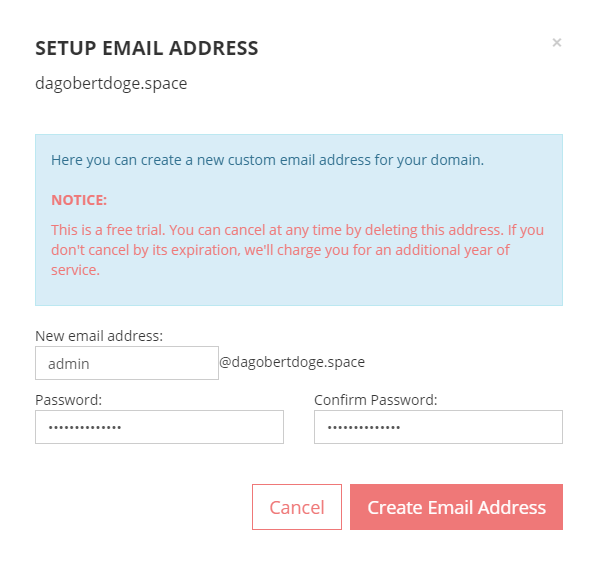
Die Einrichtung eines gehosteten Email Accounts wird in der Knowledge Base von Porkbun beschrieben. Der erste Monat ist kostenfrei.
Nach dem einmonatigem Testzeitraum wird die Gebühr für ein ganzes Jahr eingezogen, also noch flugs einen Reminder zum rechtzeitigen Löschen angelegt.
Anschließend werden die Email Configuration Settings angezeigt, sehr hilfeich. Außerdem eine DMARC Notice. Wenn man auf den Configure Button klickt, werden die Einstellungen automatisch vorgenommen. Was es mit DMARC genau auf sich hat muss ich bei Gelegenheit evaluieren.
Der Webmail Client präsentiert sich sehr aufgeräumt, nice:
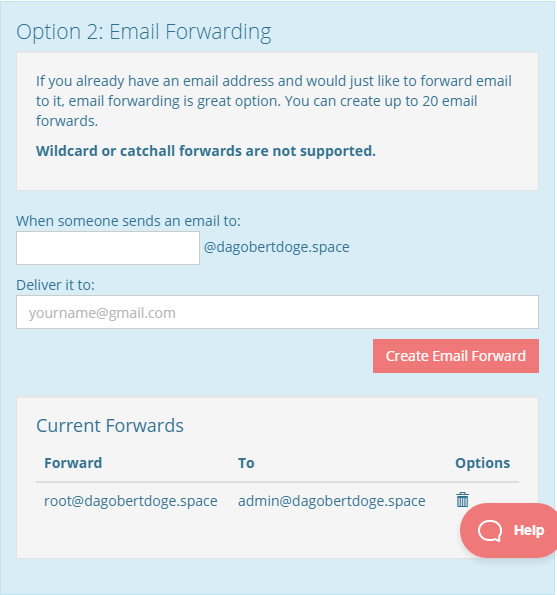
Alternativ wäre auch ein dauerhaft kostenfreies Email Forwarding möglich:
Website auf Github Pages
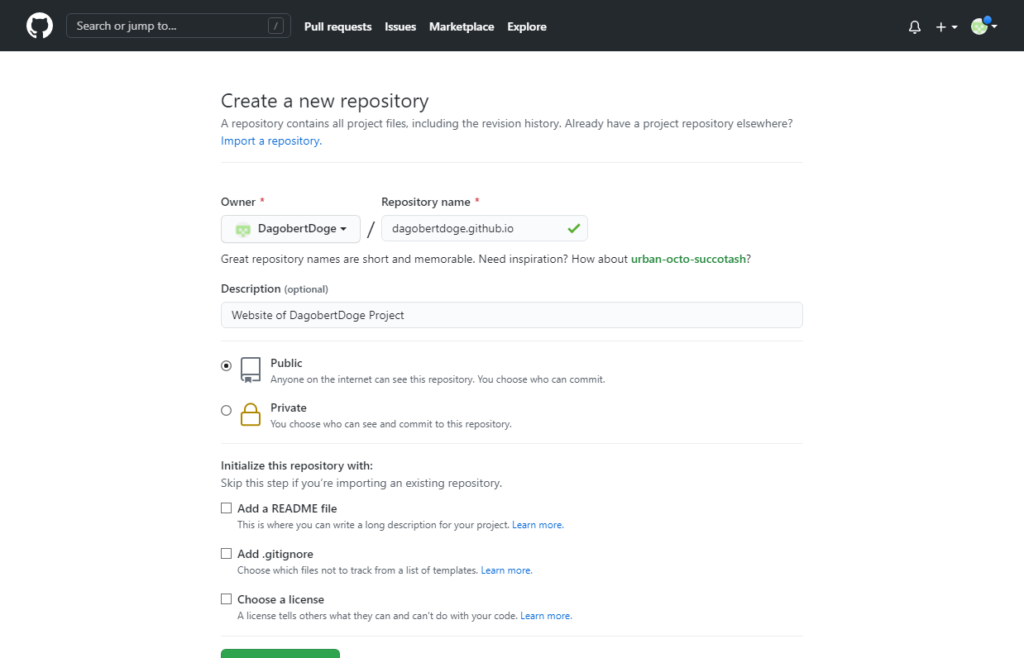
Die Website soll auf Github Pages gehostet werden. Das ist kostenfrei und über die üblichen Git Tools editierbar. Zumindest stelle ich mir das so vor, der Test kommt jetzt:
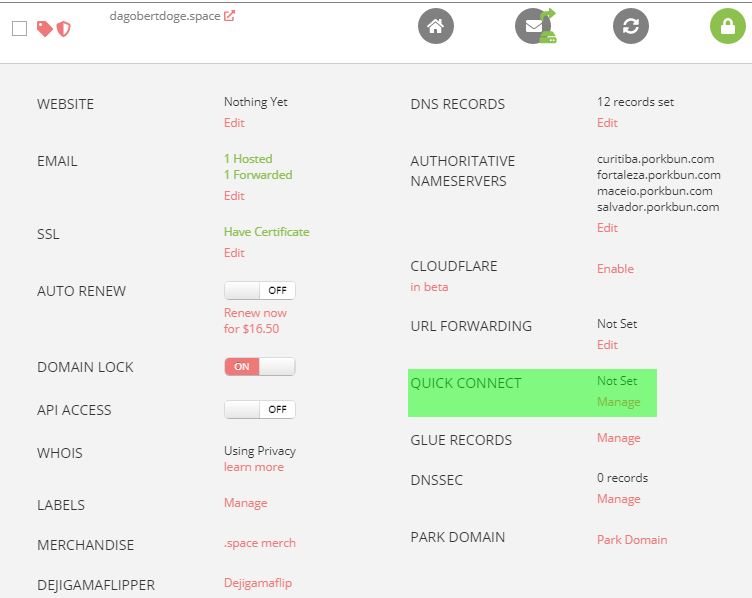
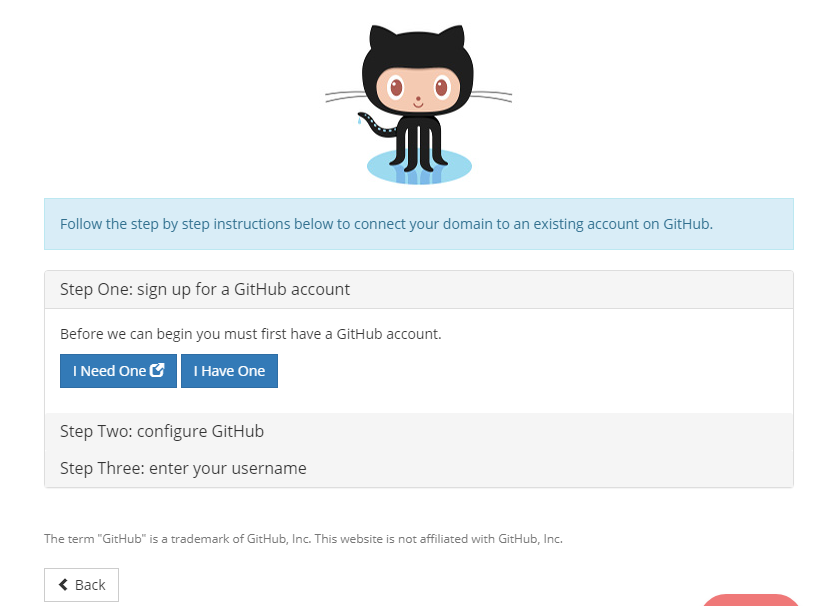
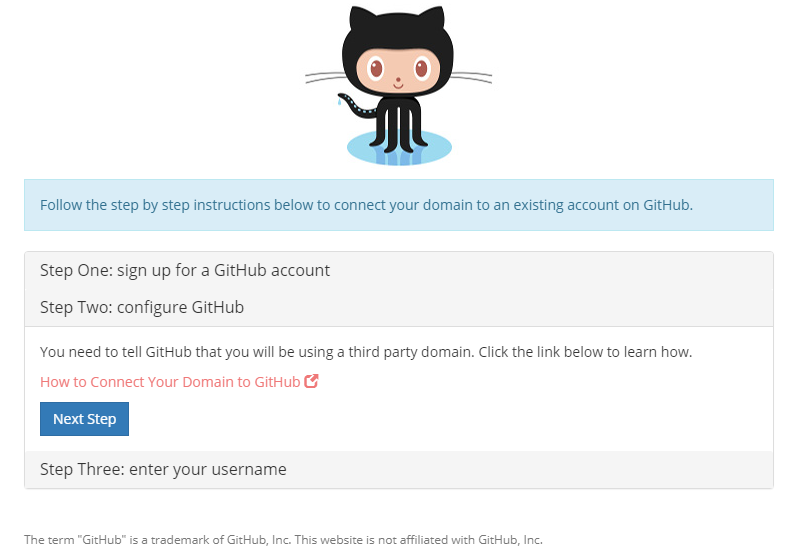
In den Details des Domain Managements -> Quick Connect -> Manage:
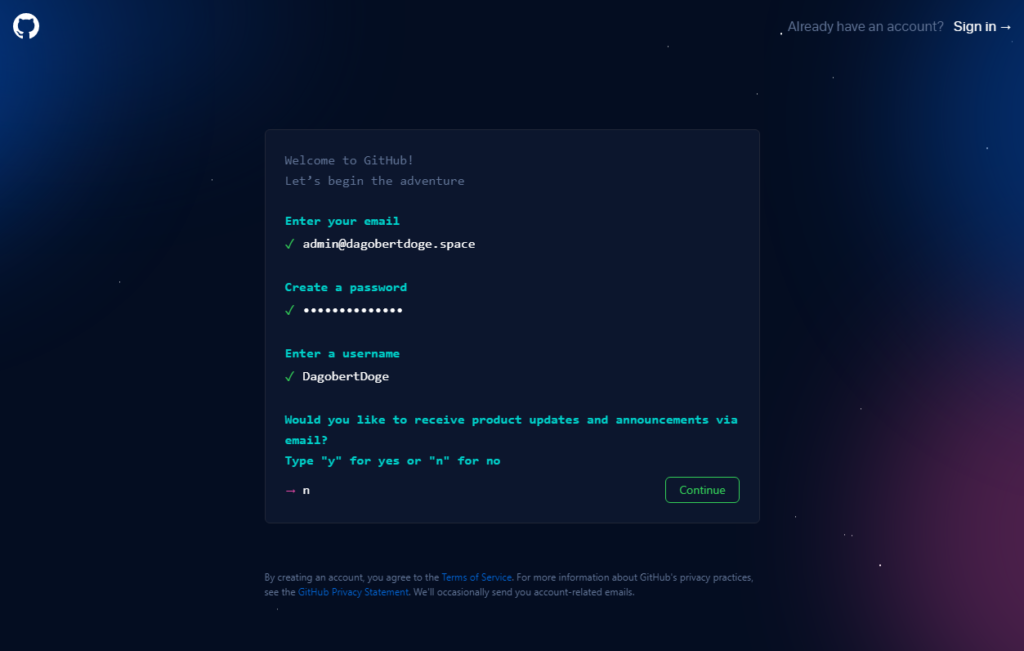
Github auswählen und einen neuen Account anlegen:
Auf I Need One klicken, schon öffnet sich GitHub in einem neuen Tab:
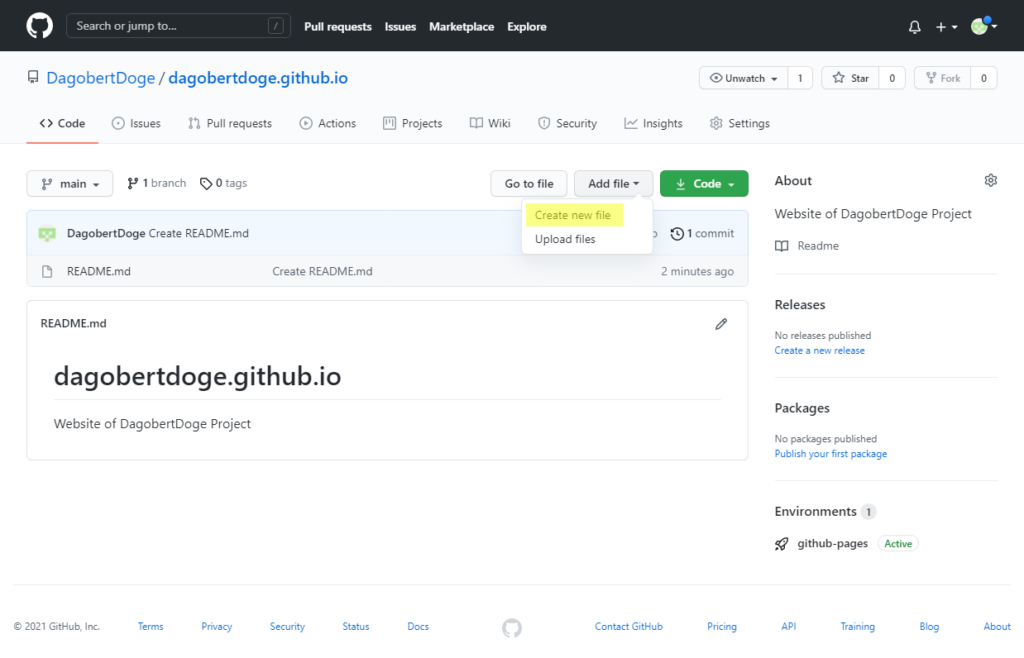
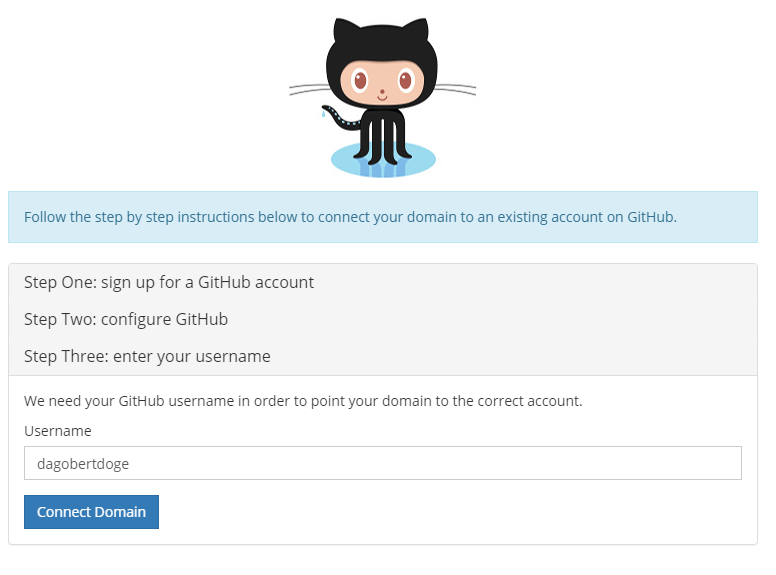
Und siehe da, wenn wir jetzt DagobertDoge öffnen, sehen wir:
Die Website - Ein Template
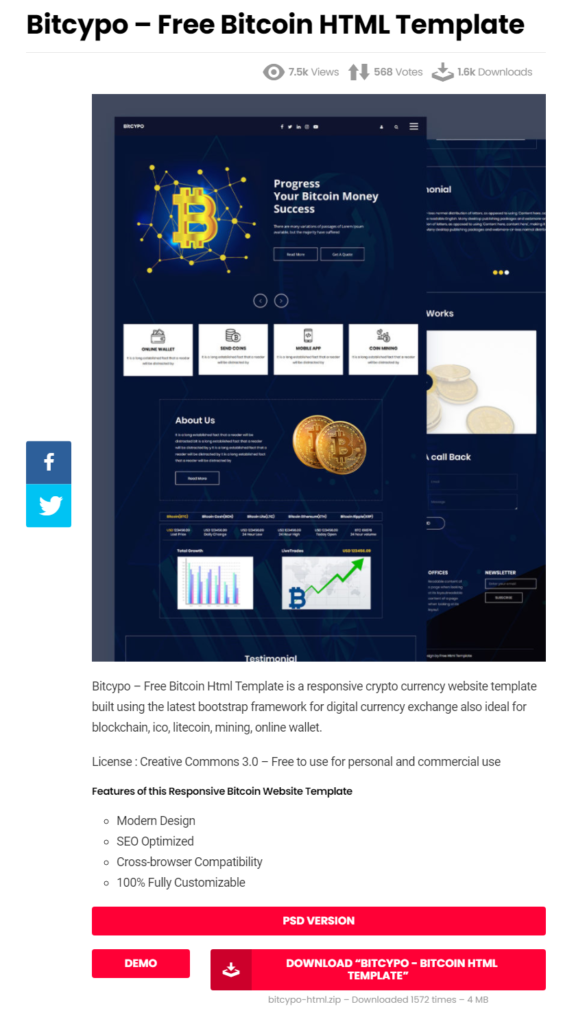
Die HelloWorld-Seite sieht maximal spartanisch aus, daher habe ich ein frei verfüg- und nutzbares Template für eine fancy Website gesucht und auf html DESIGN gefunden:
Die Website - Das Projekt
Das Git Projekt auf meinen Arbeitsrechner clonen:
cd [...]/workspace
git clone https://github.com/DagobertDoge/dagobertdoge.github.io.git
cd dagobertdoge.github.io
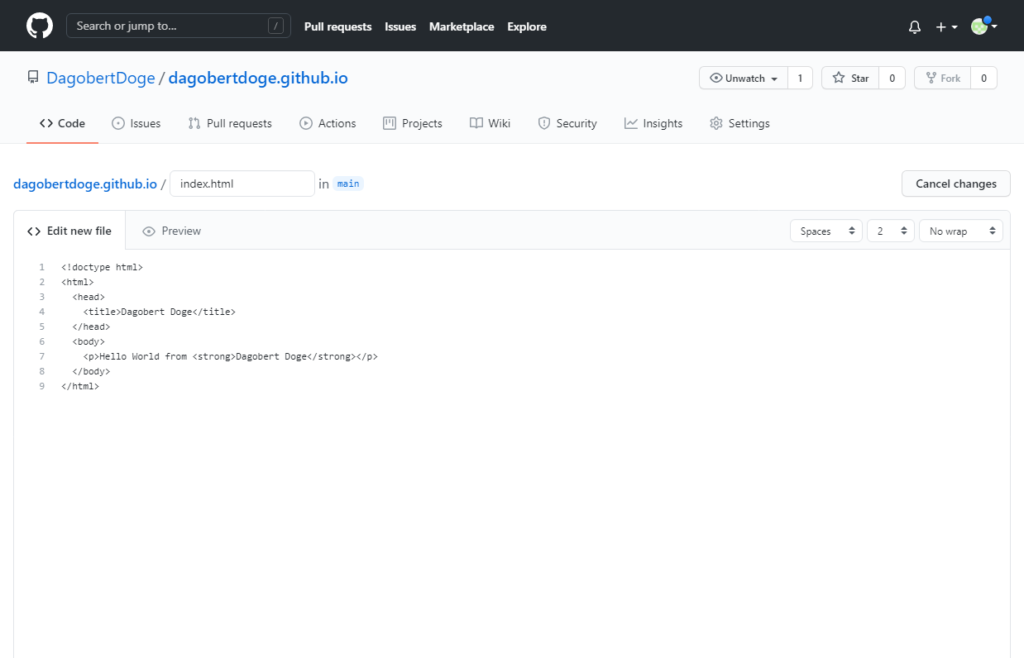
Die Dateien aus dem Bitcypo Template werden in das dagobertdoge.github.io Verzeichnis kopiert.
Git einrichten und Änderungen in das Repository übertragen:
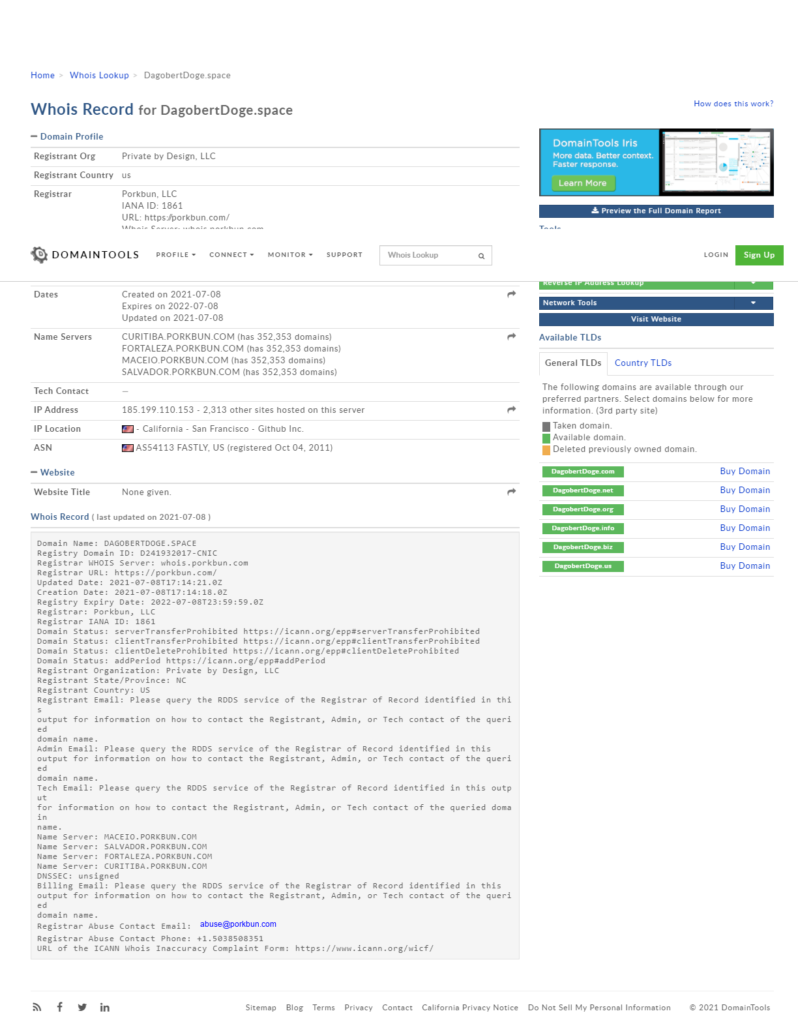
Eine Whois-Abfrage ergab, dass keinerlei persönlichen Informationen von mir im Whois Record eingetragen wurden. Ich brauche also keine Angst vor zB Spam haben.
Abschluss
Die Etappenziele sind erreicht: Eine eigene Domain für schmales Geld, Webmail für zumindest einen Monat, danach wenigstens noch die Mailweiterleitung. Bei Gelegenheit sollte ich mal schauen, ob es nicht einen Dienst gibt, der einem gratis das Mailhosting übernimmt. Das müsste ja technisch möglich sein über einen entsprechenden Eintrag im MX Record.
Das Repository für den Code der Website und sogar das Hosting der (statischen) Seite gibt es for free.
Ein Template für die erste Version der Website gibt es auch for free.
Nachtrag: Basic authentication deprecation
Nach dem Checkin in GitHub erreichte mich diese EMail:
Hi @DagobertDoge,
You recently used a password to access the repository at DagobertDoge/dagobertdoge.github.io with git using git/2.20.1.
Basic authentication using a password to Git is deprecated and will soon no longer work. Visit https://github.blog/2020-12-15-token-authentication-requirements-for-git-operations/ for more information around suggested workarounds and removal dates.
Thanks,
The GitHub Team
Für die Verwendung über die Konsole benötige ich also einen personal access token, sonst ist bald Schluß mit Lustig.
Der Anleitung folgend auf das Profil Photo klicken -> Settings -> Developer Settings -> Personal access tokens -> Generate a personal access token:
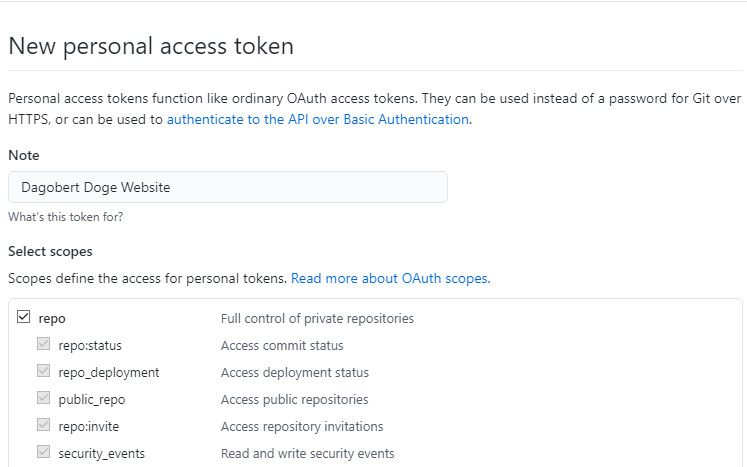
Generate new token with descriptive name and permissions. To use your token to access repositories from the command line, select repo.
Es wird ein Personal access token generiert und angezeigt. Dieser ist unbedingt zu notieren, denn er kann nicht noch einmal angezeigt werden.
"Once you have a token, you can enter it instead of your password when performing Git operations over HTTPS."
Damit ich nicht bei jedem Commit etc. den Username & Token eingeben muss, aktiviere ich das Caching der Credentials:
# Set git to use the credential memory cache
$ git config --global credential.helper cache
# Set the cache to timeout after 1 hour (setting is in seconds)
$ git config --global credential.helper 'cache --timeout=3600'
Git kann jetzt wie zuvor verwendet werden. Beim ersten Befehl muss einmalig Username & Token eingegeben werden, diese werden für die darauffolgende Stunde gecached.
Um die Daten einer MS-SQL Datenbank zu exportieren und anschließend in die geDockerte Version zu kopieren (MS-SQL DB in Docker Container) habe ich die Chains verwendet, eine propritäre Software.
Vorbereitung
Die Entwicklung und Ausführung der Scripte erfolgt auf dem Entwickler Laptop. Später werden die Scripte voraussichtlich auf den Servern ausgeführt, da grade für die produktive Umgebung eine längere Laufzeit erwartet wird.
Auf den Entwickler Laptops läuft Windows, so dass zum Ausführen der Chains das Windows Executable Chain.cmd verwendet wird. In dieser Datei sind Anpassungen vorzunehmen, so ist der JAVA_HOME Pfad inzwischen ein anderer und mMn sollte das File Encoding auf UTF-8 gesetzt werden:
#SET JAVA_HOME=%%~d0/jre13
SET JAVA_HOME=%%~c0/eclipse/java/java1.8
SET FIXED_PROPS=%%STDPROPS%% [...] -Dfile.encoding=UTF-8
Die Ausführung der einzelnen Chain muss aus dem Verzeichnis der Chain.cmd erfolgen. Ausnahme: Auf meinem Laptop muss ich es genau anders herum machen und in das Verzeichnis der Chain gehen und Chain.cmd mit absolutem Pfad aufrufen.
cd D:\Development\workspace\chainproject\bin\
Chain.cmd ../../ChainsProject/ImportChain.chn
Datenbank Verbindungsdaten
Die Verbindungsdaten der Datenbank werden in einer eigenen Konfigurationsdatei hinterlegt:
Das Chain Command Script ist relativ übersichtlich, da lediglich ein Schritt ausgeführt werden muss. Für diesen Schritt ist das Prefix und die zu verwendende Java Klasse zu definieren. Außerdem sind noch die Verbindungsdaten der Datenbank zu includieren:
Das Chain "SQL" Script ermittelt erst alle Tabellen der angegebenen Schema und speichert diese in der Datei TABLES.csv:
#DEFINE CSVFILE TABLES.csv
#QUERY_CSV (ECHO) [CSVFILE]
SELECT table_catalog, table_schema, table_name, table_type
FROM CCP.INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = 'BASE TABLE'
AND TABLE_SCHEMA IN ('DEMO_SCHEMA')
ORDER BY TABLE_SCHEMA, TABLE_NAME
#INFO [SELECTED] rows exported into File [CSVFILE]
Anschließend wird über alle Tabellen iteriert, deren Daten gelesen und in einer CSV-Datei gespeichert:
Als Vorbereitung muss im Verzeichnis DEMO_SCHEMA eine Datei csvlist angelegt werden, in dieser stehen die zu importierenden Tabellendaten-CSV-Dateinamen. Der reine Import ist ein Einzeiler, dem diese csvlist Datei übergeben wird und das Schema, in das diese Tabellendaten importiert werden sollen:
Ich möchte eine bestehende MS-SQL Datenbank in einen lokalen Docker Container kopieren. Dazu werde ich zuerst die Struktur der Datenbank exportieren und in einem Docker Container neu aufbauen. Anschließend werden die Daten in CSV Dateien exportiert und in die containerisierte Datenbank importiert.
Datenbank Script exportieren
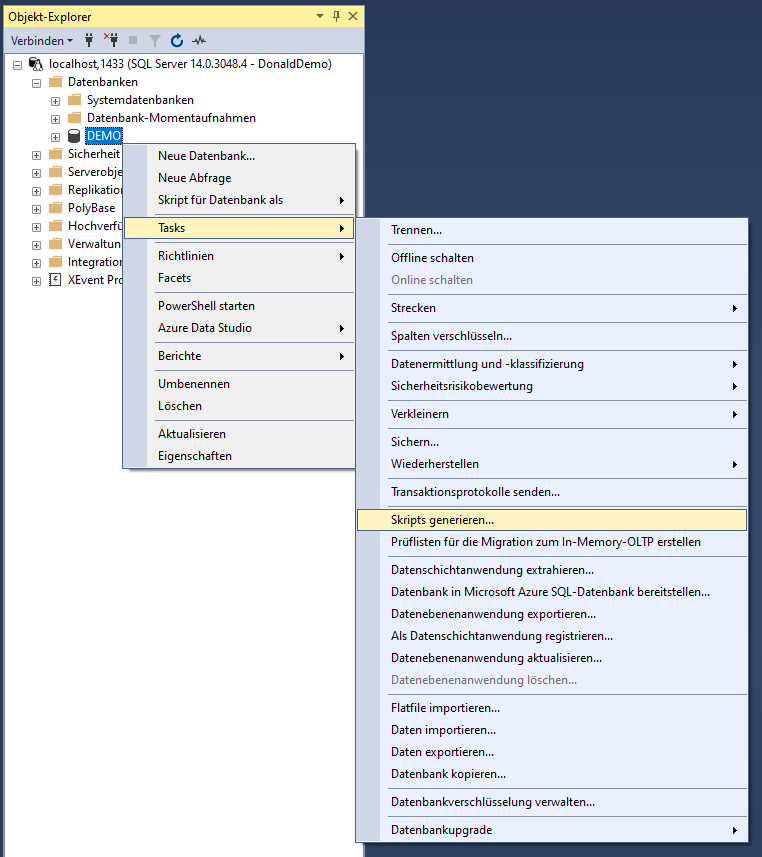
Den Export der Datenbankstruktur geschieht über das MS-SQL Management Studio. In der DB einloggen und dann im Objekt-Explorer über Tasks -> Skripts generieren aufrufen:
Datenbankscript generieren lassen(Symbolphoto)
Die Einstellungen wie vorgegeben belassen und die Datei script.sql speichern.
Das Script beginnt ungefähr so:
USE [master]
GO
CREATE DATABASE [DEMO]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'DEMO', FILENAME = N'C:/Pfad/DEMO.mdf' , SIZE = 102400KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB ),
FILEGROUP [DEMO_DAT]
( NAME = N'DEMO_DAT', FILENAME = N'C:/Pfad/DEMO.ndf' , SIZE = 5120KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB ),
FILEGROUP [DEMO_IDX]
( NAME = N'DEMO_IDX', FILENAME = N'C:/Pfad/DEMO_IDX.ndf' , SIZE = 3552960KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB )
LOG ON
( NAME = N'DEMO_log', FILENAME = N'C:/Pfad/DEMO_Log.ldf' , SIZE = 2234880KB , MAXSIZE = 2048GB , FILEGROWTH = 102400KB )
GO
ALTER DATABASE [DEMO] ADD FILEGROUP [DEMO_DAT]
GO
ALTER DATABASE [DEMO] ADD FILEGROUP [DEMO_IDX]
GO
USE [DEMO]
GO
CREATE USER [DONALDDEMO] FOR LOGIN [DonaldDemo] WITH DEFAULT_SCHEMA=[DEMO_SCHEMA]
GO
GO
ALTER ROLE [db_owner] ADD MEMBER [DONALDDEMO]
GO
CREATE SCHEMA [DEMO_SCHEMA]
GO
Datenbank Script anpassen
Damit das Script im Container ausgeführt werden kann, müssen ein paar Anpassungen erfolgen.
Der Speicherort auf dem Quell-Server lautet: "C:/Pfad/". Im Container lautet der Pfad: "/var/opt/mssql/data/". Dies ist bei den Filenamen anzupassen.
Das Script definiert einen Benutzer für die Datenbank an und weist diesem ein Login zu:
CREATE USER [DONALDDEMO] FOR LOGIN [DonaldDemo]
User und Login sind also zwei verschiedene Sachen. Der User gehört zur Datenbank, der Login zur übergeordneten Datenbankinstanz "master". Bevor über das Script die DB und der User angelegt werden, wird ein entsprechender Login angelegt:
USE [master]
GO
CREATE LOGIN [DonaldDemo] WITH PASSWORD = 'DonaldDemo12345678'
Eventuell vorhandenen AD-Accounts fliegen raus, die benötige ich nicht für die lokale Entwicklung.
Das angepasste Demo-Script:
USE [master]
GO
CREATE LOGIN [DonaldDemo] WITH PASSWORD = 'DonaldDemo12345678'
USE [master]
GO
CREATE DATABASE [DEMO]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'DEMO', FILENAME = N'/var/opt/mssql/data/DEMO.mdf' , SIZE = 102400KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB ),
FILEGROUP [DEMO_DAT]
( NAME = N'DEMO_DAT', FILENAME = N'/var/opt/mssql/data/DEMO.ndf' , SIZE = 5120KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB ),
FILEGROUP [DEMO_IDX]
( NAME = N'DEMO_IDX', FILENAME = N'/var/opt/mssql/data/DEMO_IDX.ndf' , SIZE = 3552960KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB )
LOG ON
( NAME = N'DEMO_log', FILENAME = N'/var/opt/mssql/data/DEMO_Log.ldf' , SIZE = 2234880KB , MAXSIZE = 2048GB , FILEGROWTH = 102400KB )
GO
ALTER DATABASE [DEMO] ADD FILEGROUP [DEMO_DAT]
GO
ALTER DATABASE [DEMO] ADD FILEGROUP [DEMO_IDX]
GO
USE [DEMO]
GO
CREATE USER [DONALDDEMO] FOR LOGIN [DonaldDemo] WITH DEFAULT_SCHEMA=[DEMO_SCHEMA]
GO
GO
ALTER ROLE [db_owner] ADD MEMBER [DONALDDEMO]
GO
CREATE SCHEMA [DEMO_SCHEMA]
GO
Der Docker Container
Die Quell DB ist ein Microsoft SQL Server Version 11, was dem dem Release Namen "SQL Server 2012" entspricht. Das älteste Docker Image ist ein SQL Server 2017, was der Version 14 entspricht. Bei meinen Tests war es aber kein Problem, dass die DB in eine höhere Version migriert wird. Um die Datenbank zu persistieren wird ein Docker Volume verwendet und das Image über Docker Compose gestartet.
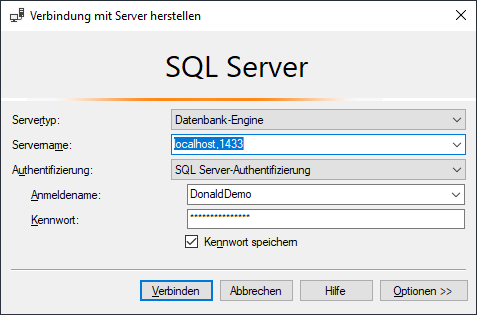
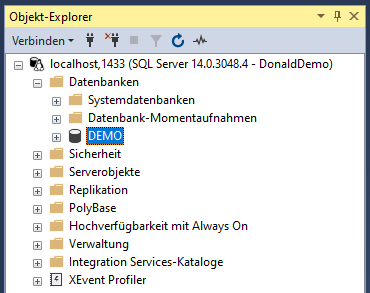
Mit dem Microsoft SQL Server Management Studio kann man sich nun gegen die Datenbank verbinden:
Servername: localhost
Port: 1433
Anmeldename: DonaldDemo
Kennwort: DonaldDemo12345678
Daten Export
Für den Daten ex- und anschließenden import verwende ich ein Tool auf das ich hier nicht weiter eingehen werde (vgl. DB Export & Import) und beschreibe lediglich die logischen Schritte und die benötigten SQLs.
In einem ersten Schritt werden die zu exportierenden Tabellen der benötigten Schemata der Datenbank ermittelt und gespeichert:
SELECT table_catalog, table_schema, table_name, table_type
FROM DEMO.INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = 'BASE TABLE'
AND TABLE_SCHEMA IN ('DEMO_SCHEMA')--, 'DEMO_SCHEMA_2')
ORDER BY TABLE_SCHEMA, TABLE_NAME
Als nächstes wird über die Tabellen iteriert (IDX), die Daten selektiert und gespeichert:
SELECT *
FROM [IDX:table_schema].[IDX:table_name]
Daten Import
Der Datenimport ist nicht ganz so einfach.
Eine Tabelle hat keinen Primärschlüssel und konnte nicht importiert werden. Da diese Tabelle auch keine Daten enthält, war das aber kein Problem und der Import dieser Tabelle konnte einfach ausgelassen werden. Später kann geprüft werden, ob diese Tabelle überhaupt noch verwendet wird oder final gelöscht werden kann.
Eine andere Tabelle hat eine Spalte mit der IDENTITY Eigenschaft und die Daten können nicht einfach so eingefügt werden, dazu muss zuerst das IDENTITY_INSERT für diese Tabelle eingeschaltet werden.
Allgemein besteht das Problem, dass die Tabellen über gewisse Constraints verfügen, die das naive importieren der Daten verhindern. Beispielsweise Foreign Keys, so dass die Daten in einer bestimmten Reihenfolge importiert werden müssten. Oder man deaktiviert für die Dauer des Imports alle Constraints und spart sich so die Sortiererei!
Das Import Script sieht ungefährt so aus:
-- disable all constraints
EXEC sp_MSforeachtable "ALTER TABLE ? NOCHECK CONSTRAINT all"
--
SET IDENTITY_INSERT demo_schema.mydemotable ON
#IMPORT_CSV_FILES
-- enable all constraints
exec sp_MSforeachtable @command1="print '?'", @command2="ALTER TABLE ? WITH CHECK CHECK CONSTRAINT all"
Ein Problem mit Case Sensitiven Daten
Eine Tabelle bereitet mir noch Probleme:
In dieser Tabelle befinden sich Datensätze, deren Primärschlüssel sich lediglich in der Groß/Kleinschreibung unterscheiden, zB: "EinTollerDatensatz" und "eintollerdatensatz". In der alten DB waren das zwei unterschiedliche Schlüssel, in der neuen DB leider nicht und so können einige Datensätze nicht importiert werden.
Das Problem könnte mit der Collation, bzw. im Deutschen: Serversortierung, zusammenhängen. In der Servereigenschaften ist diese immer standardmäßig "SQL_LATIN1_General_CP1_CI_AS", wobei das "CI" für Case Insensitive steht. In den einzelnen Datenbanken des Servers kann man diese anpassen und eine Überprüfung der alten Datenbank ergab, dass diese "Latin1_General_CS_AS" ist. Daher habe ich der neuen Datenbank im Script nach dem CREATE DATABASE Befehl auch diese Eigenschaft zugewiesen:
CREATE DATABASE [DEMO]
# [...]
ALTER DATABASE [DEMO] COLLATE Latin1_General_CS_AS
GO
Leider führte das zu weiteren, multiplen Fehlern. Daher habe ich mich an dieser Stelle erstmal dazu entschlossen, die Collation nicht zu ändern und mit fehlenden Datensätzen weiter zu arbeiten.
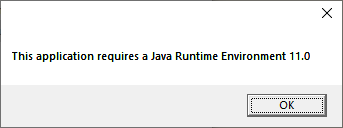
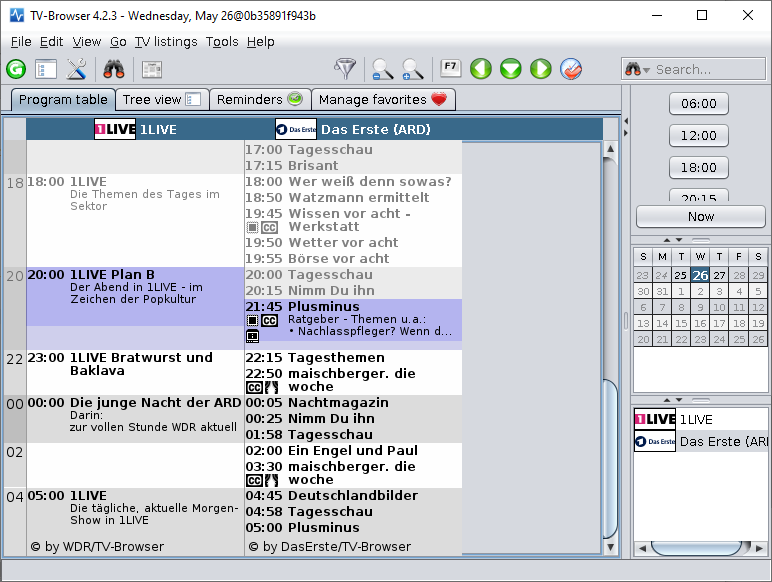
In der Vergangenheit habe ich gerne den TV-Browser als freie Programmzeitschrift verwendet. Leider funktioniert das Programm auf meinem neuen Laptop nicht mehr, irgendwie ist das Java bei mir nicht so installiert, wie der TV-Browser es gerne hätte und bei Versuch eines Programmstarts sehe ich lediglich dieses Fenster:
JAVA_HOME ist gesetzt, Java ist im PATH aber anscheinend fehlen dem TV-Browser die notwendigen Registry Einträge. Oder irgendwas anderes. Also habe ich mir überlegt, ich könnte doch mal testen, das Programm in einem Docker Container laufen zu lassen.
TV-Browser im Docker Container
Das Docker Image
TV-Browser gibt es für Mac, Windows und Linux. Die Mac Version scheidet völlig aus, denn ich habe keinen Mac. Windows im Container? Nee hab ich noch nicht gemacht, gibt bestimmt Probleme. Also eine Linux Version. Ich habe die meiste Erfahrung mit Debian und Ubuntu, der Münzwurf entscheidet zur GNU/Linux Variante. Daher wird der Container auf einem Debian Linux mit Java 11 Image aufgebaut und das Dockerfile startet mit:
FROM adoptopenjdk/openjdk11:debianslim-jre
Wie ich beim Testen feststellen musste, reicht das reine Image nicht aus, es muss noch das Package "default-jre" installiert werden. Was aber leider auch nicht auf Anhieb funktioniert, zuerst muss manuell ein Verzeichnis angelegt werden. Außerdem wird noch "wget" benötigt, um die Installationsdatei herunterzuziehen.
Außerdem muss noch die Timezone gesetzt werden. Diese wird mittels einer Environment Variablen gesetzt, so dass sie beim Starten des Containers ggf. auch überschrieben werden kann:
Leider werden so zwar einige, aber leider eben nicht alle Daten gespeichert. Damit der TV-Browser rund läuft muss hier noch nachgearbeitet werden.
Die GUI
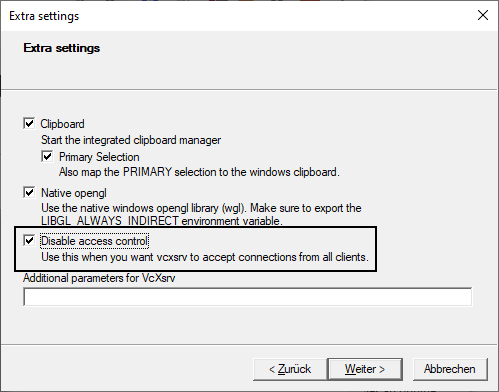
Der TV-Browser kann jetzt im Container laufen, aber sehen tun wir erstmal nix. Dafür brauchen wir einen X Server, beispielsweise den VcXsrv Windows X Server. Downloaden, installieren und starten.
Beim Start zuerst die "Display settings" und dann den "Client startup" unverändert weiter klicken. Bei den "Extra settings" muss der access control disabled werden, andernfalls wird der Request aus dem Docker Container abgewiesen:
Important: Disable access control in Extra settings
Es wird die IP Adresse des Windows Rechners benötig, kann man beispielsweise über den ipconfig Befehl herausfinden, bei mir war es zB 192.168.56.1, somit lautet das entsprechende Fragment für den docker Befehl:
Falls gewünscht kann auch eine andere Zeitzone gesetzt werden:
docker [...] -e TZ=America/Los_Angeles [...]
Man kann den Container auch im Hintergrund laufen lassen, verpasst so aber die schönen Logging Ausgaben:
docker [...] --detach [...]
Resultat
Der TV-Browser läuft prinzipiell:
Der gedockerte TV-Browser im X-Server
Allerdings kommt bei jedem Start der Konfigurations Assistent, der sich auch nicht komplett durcharbeiten lässt und abgebrochen werden muss. Die Ursache für den Fehler ist mir nicht klar, geloggt wird:
10:13:50 PM SEVERE: UNCAUGHT EXCEPTION IN THREAD 'Thread-9'
java.lang.IndexOutOfBoundsException: The row index 15 must be less than or equal to 11.
at jgoodies.forms/com.jgoodies.forms.layout.CellConstraints.ensureValidGridBounds(CellConstraints.java:949)
at jgoodies.forms/com.jgoodies.forms.layout.FormLayout.setConstraints(FormLayout.java:821)
at jgoodies.forms/com.jgoodies.forms.layout.FormLayout.addLayoutComponent(FormLayout.java:1106)
at java.desktop/java.awt.Container.addImpl(Unknown Source)
at java.desktop/java.awt.Container.add(Unknown Source)
at jgoodies.forms/com.jgoodies.forms.builder.AbstractFormBuilder.add(AbstractFormBuilder.java:491)
at jgoodies.forms/com.jgoodies.forms.builder.PanelBuilder.add(PanelBuilder.java:879)
at schedulesdirectdataservice.SchedulesDirectSettingsPanel.createGui(SchedulesDirectSettingsPanel.java:216)
at schedulesdirectdataservice.SchedulesDirectSettingsPanel.<init>(SchedulesDirectSettingsPanel.java:96)
at schedulesdirectdataservice.SchedulesDirectDataService.getAuthenticationPanel(SchedulesDirectDataService.java:1470)
at tvbrowser/tvbrowser.core.tvdataservice.DefaultTvDataServiceProxy.getAuthenticationPanel(DefaultTvDataServiceProxy.java:302)
at tvbrowser/tvbrowser.ui.configassistant.AuthenticationChannelCardPanel.createPanel(AuthenticationChannelCardPanel.java:74)
at tvbrowser/tvbrowser.ui.configassistant.NetworkSuccessPanel.onNext(NetworkSuccessPanel.java:85)
at tvbrowser/tvbrowser.ui.configassistant.ConfigAssistant.lambda$actionPerformed$0(ConfigAssistant.java:203)
at java.base/java.lang.Thread.run(Unknown Source)
Die Senderauswahl wird gespeichert, nicht aber das heruntergeladene Programm, dieses muss also auch nach jedem Start erneut heruntergeladen werden.
Ausblick
Vermutlich durch die Verwendung des X-Servers kommt es zu der IndexOutOfBounds-Exception. Ich könnte mir den Code aus dem SVN ziehen: https://svn.code.sf.net/p/tvbrowser/code/ und dann versuchen, den Fehler zu debuggen. Also wenn ich irgendwann mal zu viel Zeit habe... Oder ich schreibe einen Bugreport an die Entwickler, kostet aber auch Zeit, da das vermutlich ein sehr spezieller Spezialfall ist, den ich dann spezifisch beschreiben müsste, damit das überhaupt was bringt. Alternativ kann man vermutlich auch mit dem Abbruch des Konfigurations Assistenten leben. Allerdings muss man den dann aber bei jedem Neustart wieder wegklicken, was auch irgendwie lästig ist.
Das bereits heruntergeladenes Programm "vergessen" wird ist da schon ärgerlicher. Hier müsste man den Speicherort im Container orten und über ein weiteres Volume persistieren.
In den laufenden Container kann man folgendermaßen einsteigen:
docker exec -it tvbrowser bash
Der Start ließe sich über Docker-Compose etwas vereinfachen, in das Script (YML-File) kann man alle Environment Variablen, Volumes etc. eintragen.
Sobald die Probleme behoben sind, könnte ich den Dockerfile/Docker-Compose Code in ein GIT Repository, und das Image in die Docker Registry hochladen.
Die Lösung
Nachdem ich mit dem TV-Browser im Docker Container herumgespielt hatte, habe ich nochmal einen Versuch über den "herkömmlichen" Weg gewagt und das Sorglospaket (Java enthalten) heruntergezogen und installiert. Und siehe da: Der TV-Browser läuft auf meinem Windows Rechner ganz ohne Docker!
Conclusio
Interessant war das ganze natürlich trotzdem! Aber ob ich nochmal an dem Projekt weiter arbeiten werde glaube ich eher nicht. Dafür gibt es noch zu viele andere spannende Projekte 😉
Test Bot Chat starten: In Telegram URL des Bots öffnen und "START" klicken(, dadurch wird /start in den Chat geschrieben) Nix passiert im Telegram Im Browser ist die Message zu sehen. Aus message -> chat -> id die ID des Chats ziehen: <ChatID>
In einem Java Projekt wird ein auf Apache Axis 1.4 basierender Client für den Zugriff auf einen von einer SAP PI/PO bereitgestellten WebService verwendet. Es begab sich nun, dass an diesem WebService eine Änderung vorgenommen wurde und wir die neue Schnittstellendefinition per wsdl-Datei zugeschickt bekommen haben um daraus unseren Client Code ableiten zu können.
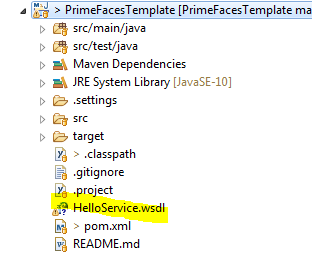
Um die einzelnen Schritte zu dokumentieren habe ich eine Beispiel WSDL Datei von Tutorialspoint kopiert und diese in meinem Beispielprojekt gespeichert.
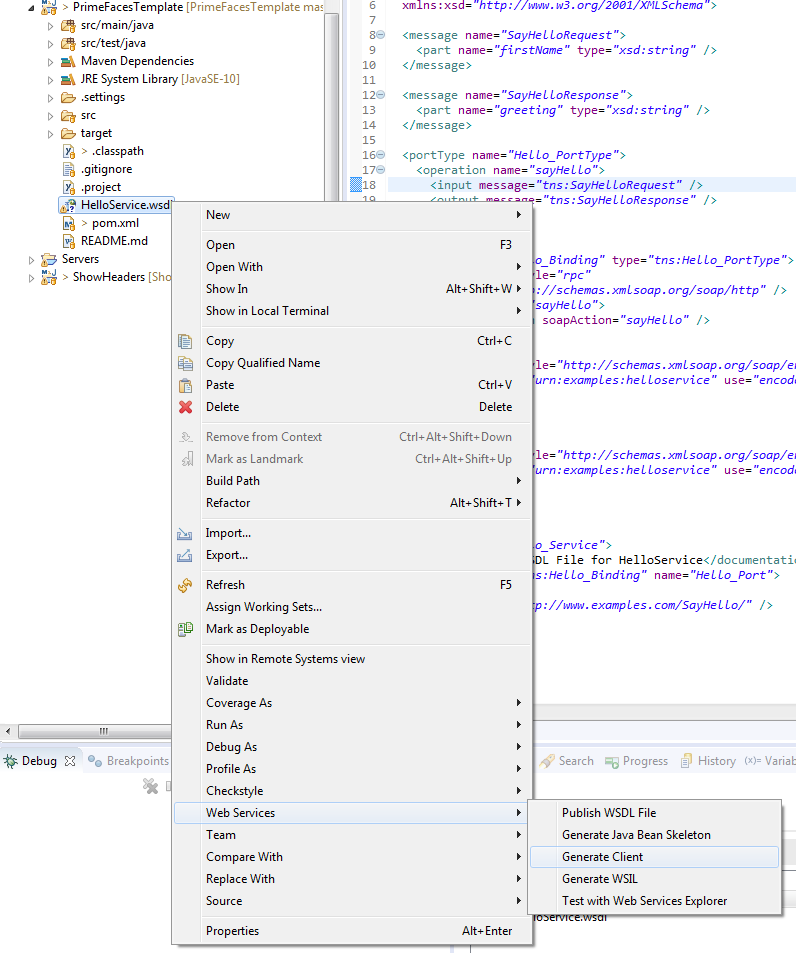
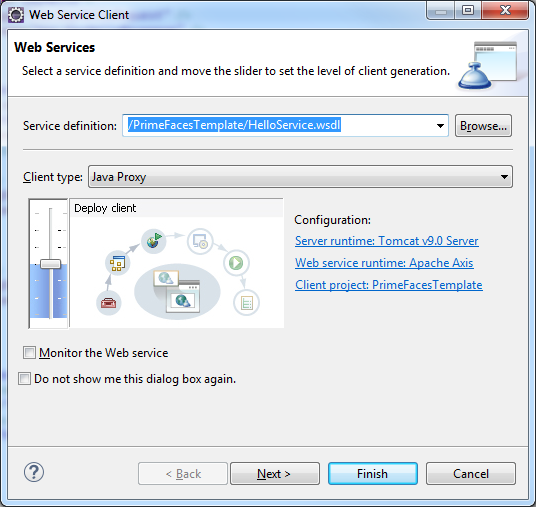
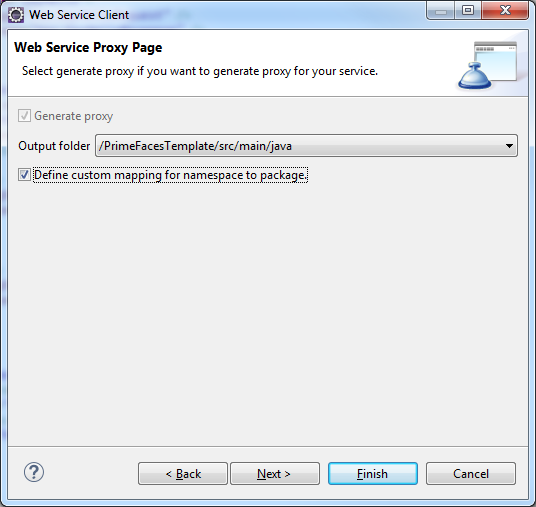
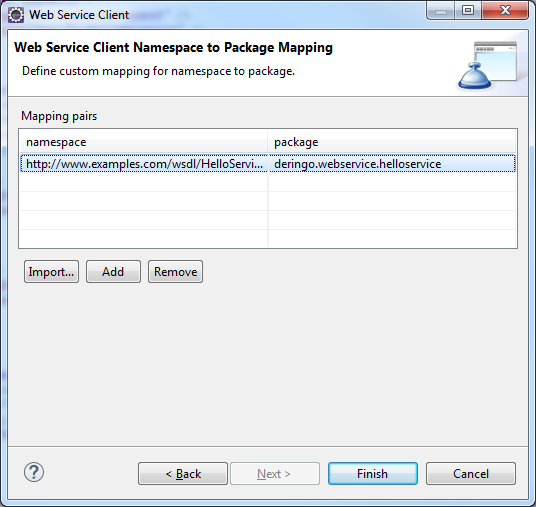
Die Client Klassen sollen in das Package deringo.webservice.helloservice generiert werden. Falls das Zielpackage bereits existieren sollte, ist es vorab zu löschen, um nicht alten und neuen Code zu vermischen. Um den Code in das gewünschte Package zu generieren ist ein Mapping Namespace auf Package vorzunehmen.
Da mein Beispielprojekt noch kein Axis integriert hat, muss die Bibliothek per Maven hinzugefügt werden.
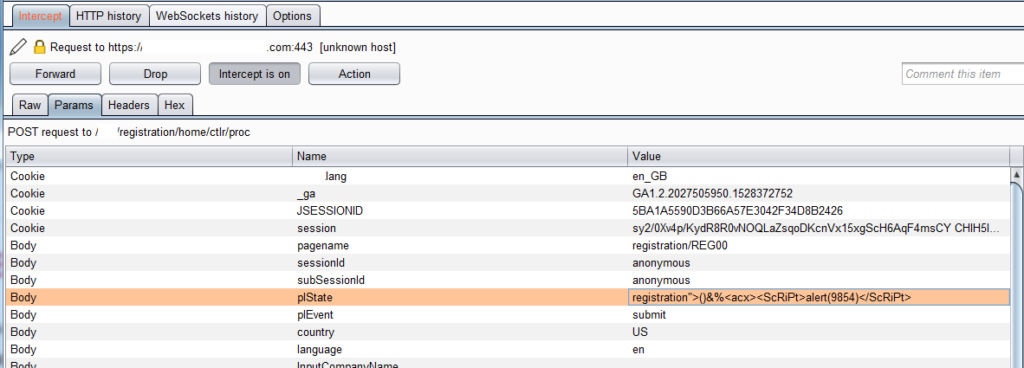
In der Burp Suite unter Proxy -> Intercept: Intercept auf on stellen.
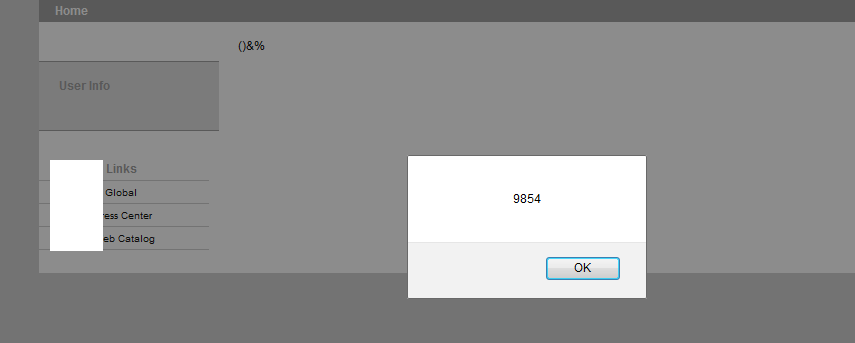
Die Registrierung unverändert abschicken. Der Aufruf durchläuft die Burp Suite und ist dort vor der Weiterleitung editierbar. Um das XSS nachzustellen diese Änderung vornehmen:
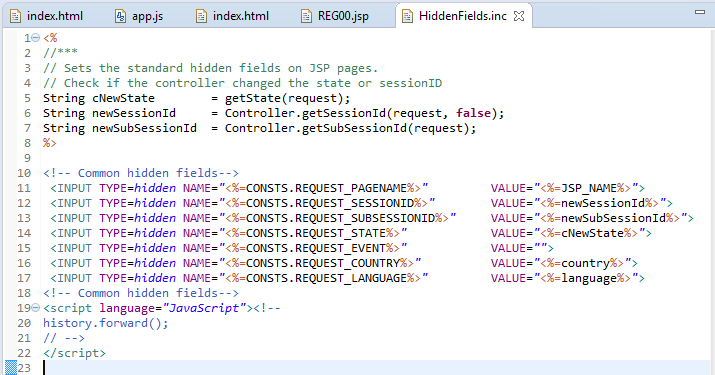
Ein erster Ansatz wäre, das Value der Input Felder in den JSPs zu escapen. Möglicherweise ist dies in den HiddenFields.inc als zentrale Stelle ausreichend. Zur Verwendung könnten eine Bibliothek der Apache Foundation kommen: org.apache.commons.lang.StringEscapeUtils