Ich habe Speech to Text getestet und mir dazu auf YouTube ein Video einer Haushaltsrede gesucht und mittels Onlinedienst als MP3 heruntergeladen.
Anschließend mit OpenAI Whisper in Text umgewandelt. Die Umwandlung hat ungefähr so lange gedauert wie die Audiodatei. Das Ergebnis ist recht gut geworden, muss aber auf jeden Fall kontrolliert und korrigiert werden.
Ich arbeite mich grade durch einen Kurs "ChatGPT, Machine learning, DeepLearning, Neuronale Netze, OpenAI API, GPTs, Assistant API, Gemini, LLMs u. deine Modelle" auf Udemy Business durch und einen Abschnitt wollte ich mir nicht nur anhören, sondern auch nach arbeiten.
Es geht um den Abschnitt "67. Der einfachste & schnellste Weg zu deinem Lora & Bilder mit deinem Gesicht" und das Video ist nur 10 Minuten lang.
Es hörte sich so einfach an: Ein paar Selfies aufnehmen, zurechtschneiden und ein Jupyter Notebook auf Google Colab ausführen. Fertig ist das LoRA des eigenen Gesichts.
Was ist ein LoRA?
LoRAs (Low-Rank Adaptations) sind kleinere Modelle, die man mit bestehenden Stable Diffusion Modellen kombinieren kannst. Sie erlauben es ein Bestehendes Modell «fine zu tunen». So kann man neue "Konzepte", wie mein Gesicht, den generierten Bildern hinzufügen.
Selfies machen
Zuerst also ein paar Selfies aufnehmen, dabei darauf achten, dass im Hintergrund nicht zu viele Gegenstände ablenken, ich wählte eine weiße Wand und ein paar nahm ich noch vor einem schwarzen Hintergrund auf.
Zum Trainieren an den Daten müssen die Bilder auf das Format 512x512 Pixel zurechtgeschnitten werden.
Da war auch schon das erste Problem: Die Bilder meines iPhones legen im HEIC-Format vor:
Was eine HEIC-Datei ist
Die Abkürzung ist auch als HEIF bekannt und steht für High Efficiency Image Format.
Es handelt sich dabei um ein Bild-Format zum platzsparenden Speichern von Bildern auf Mobil-Geräten.
iOS-Geräte speichern Bilder in HEIC-Dateien, auf Android-Geräten finden Sie in der Regel HEIF-Bilder.
Der Vorteil dieses Bild-Formats ist eine kleine Dateigröße bei JPEG-Qualität oder sogar noch besserer Qualität.
Das Problem mit HEIC-Dateien
Es ist ein propritäres Format und kann nicht ohne weiteres verwendet werden.
Ich verwende Windows 11 und konnte die Bilder betrachten, allerdings nicht bearbeiten. Vermutlich hätte ich eine Erweiterung im MS Store kaufen müssen, dann hätte ich es mit Programmen wie IrfanView bearbeiten können.
Gelöst habe ich es statt dessen mit einem Python-Programm, dass die Bilder von HEIC nach JPEG umwandelt und auf 512x512 zurecht schneidet.
LoRA trainieren
Das Training des LoRAs soll in einem Jupyther Notebook auf Google Colab erfolgen. Link
Leider konnte ich es nicht ausführen, der Python Code funktioniert nicht. Kleinere Anpassungen halfen nicht weiter, daher kopierte ich das Jupyther Notebook und die erforderlichen Scripte in ein eigenes GitHub Repository und passte so lange Notebook und Scripte an, bis sie liefen.
Das Stable Diffusion DreamBooth Notebook kann unter diesem Link in Google Colab geöffnet werden.
Ich möchte einen virtuellen Assistenten erstellen, der auf Informationen von mehreren Webseiten basiert. Ziel ist es, aus den Daten relevante Informationen bereitzustellen und auf Fragen der Benutzer zu antworten.
Da ich keine klaren Informationen über die Struktur der Webseiteninhalte hatte, wollte ich zunächst alle Seiten vollständig speichern und später bereinigen. Die Lösung soll dynamisch erweiterbar sein und folgende Schwerpunkte abdecken:
Web Scraping: Automatisches Sammeln von Rohdaten von verschiedenen Webseiten.
Speicherung: Daten in MongoDB speichern, sowohl Rohdaten als auch bereinigte Daten.
Durchsuchbarkeit: Daten mit einem Full-Text-Index durchsuchbar machen.
KI-Integration: Eine lokale KI-Instanz (Teuken-7B von OpenGPT-X) verwenden, die mit allen 24 europäischen Amtssprachen trainiert wurde, um Benutzerfragen in natürlicher Sprache zu beantworten.
Benutzeroberfläche: Ein Web-Interface für eine einfache und intuitive Nutzung der Lösung.
Lösungsansatz
Web Scraping mit Scrapy:
Automatisches Sammeln von HTML-Rohdaten von mehreren Webseiten.
Dynamisches Einlesen von Start-URLs.
Bereinigung der Daten während des Scrapings (HTML-Tags entfernen, Boilerplate entfernen, Texte kürzen).
Datenhaltung mit MongoDB:
Rohdaten und bereinigte Texte wurden parallel gespeichert, um flexibel zu bleiben.
Full-Text-Index mit deutscher Spracheinstellung eingerichtet, um die bereinigten Texte effizient zu durchsuchen.
KI-Integration mit Teuken-7B:
Übergabe der MongoDB-Ergebnisse als Kontext an das Sprachmodell Teuken-7B.
Das Modell generiert eine präzise Antwort auf die Benutzerfrage, basierend auf den bereitgestellten Daten.
Web-App mit Flask:
Einfache Benutzeroberfläche, um Fragen zu stellen und KI-Antworten anzuzeigen.
Verbindung von Flask mit MongoDB und der KI für dynamische Abfragen.
Architektur
1. Datensammlung
Tool: Scrapy.
Datenquellen: Liste von Start-URLs (mehrere Domains).
Prozess:
Besuch der Startseiten.
Rekursive Erfassung aller Links innerhalb der erlaubten Domains.
Speicherung der Rohdaten (HTML) und bereinigten Daten (Text).
2. Datenhaltung
Datenbank: MongoDB.
Struktur:
{
"url": "https://www.example.com/about",
"raw_html": "<html>...</html>",
"cleaned_text": "This is an example text.",
"timestamp": "2024-11-26T12:00:00Z"
}
Full-Text-Index:
Feld: cleaned_text.
Sprache: Deutsch.
3. Datenanalyse
Abfragen:
MongoDB-Textsuche mit Unterstützung für Wortstämme (z. B. „Dienstleistung“ und „Dienstleistungen“).
Priorisierung der Ergebnisse nach Relevanz (score).
4. KI-Integration
KI-Tool: Teuken-7B (OpenGPT-X).
Prozess:
Übergabe der MongoDB-Ergebnisse als Kontext an die KI.
Generierung einer präzisen Antwort basierend auf der Benutzerfrage.
5. Benutzeroberfläche
Framework: Flask.
Funktionen:
Eingabeformular für Benutzerfragen.
Anzeige der KI-Antwort und der relevanten Daten.
Einfache und intuitive Navigation.
Implementierung
1. Überblick über die Implementierungsschritte
Wir setzen die zuvor beschriebenen Schritte um:
Web Scraping mit Scrapy: Erfassen von Daten von mehreren Webseiten.
Datenhaltung mit MongoDB: Speicherung der Roh- und bereinigten Daten.
Full-Text-Index: Einrichten eines deutschen Index in MongoDB.
KI-Integration mit Teuken-7B: Verarbeitung von Benutzerfragen mit einer lokalen Instanz.
Benutzeroberfläche mit Flask: Web-Interface zur Interaktion mit dem virtuellen Assistenten.
2. Web Scraping: FullSiteSpider
Erstelle einen Scrapy-Spider (spiders/fullsite_spider.py), der mehrere Domains und Seiten crawlt.
import scrapy
from bs4 import BeautifulSoup
class FullSiteSpider(scrapy.Spider):
name = "fullsite"
# Liste der erlaubten Domains und Start-URLs
allowed_domains = ["example.com", "example2.com", "example3.org"]
start_urls = [
"https://www.example.com",
"https://www.example2.com",
"https://www.example3.org/start"
]
def parse(self, response):
# Rohdaten speichern
raw_html = response.body.decode('utf-8')
# Bereinigung der HTML-Daten
cleaned_text = self.clean_html(raw_html)
# Speichern der Daten
yield {
'url': response.url,
'raw_html': raw_html,
'cleaned_text': cleaned_text,
'timestamp': response.headers.get('Date', '').decode('utf-8'),
}
# Folge allen Links auf der Seite
for link in response.css('a::attr(href)').getall():
if link.startswith('http') or link.startswith('/'):
yield response.follow(link, self.parse)
def clean_html(self, html_content):
"""Bereinigt HTML und extrahiert lesbaren Text."""
soup = BeautifulSoup(html_content, 'html.parser')
text = soup.get_text(separator=" ").strip()
return " ".join(text.split())
3. Datenhaltung: MongoDB Pipeline
Speichere die gescrapten Daten direkt in MongoDB.
import pymongo
import json
class MongoPipeline:
def __init__(self):
# Konfiguration aus Datei laden
with open('config.json') as config_file:
config = json.load(config_file)
self.mongo_uri = config['MONGO_URI']
self.mongo_db = config['MONGO_DATABASE']
def open_spider(self, spider):
# Verbindung zur MongoDB herstellen
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
# Verbindung schließen
self.client.close()
def process_item(self, item, spider):
# Daten in MongoDB speichern
collection = self.db[spider.name]
collection.insert_one({
'url': item['url'],
'raw_html': item['raw_html'],
'cleaned_text': item['cleaned_text'],
'timestamp': item['timestamp'],
})
return item
from openai import OpenAI
# Verbindung zur lokalen KI
local_ai = OpenAI(base_url="http://127.0.0.1:1234/v1", api_key="lm-studio")
def generate_response(question, results):
"""
Generiert eine Antwort mit der lokalen KI basierend auf den MongoDB-Ergebnissen.
"""
# Kontext aus den MongoDB-Ergebnissen erstellen
context = "\n".join(
[f"URL: {doc['url']}\nText: {doc['cleaned_text']}" for doc in results]
)
# Nachrichtenformat für die KI
messages = [
{"role": "system", "content": "Du bist ein virtueller Assistent für Firmendaten."},
{"role": "user", "content": f"Hier sind die Daten:\n{context}\n\nFrage: {question}"}
]
# Anfrage an die lokale KI
response = local_ai.chat.completions.create(
model="teuken-7b",
messages=messages,
temperature=0.7
)
return response.choices[0].message.content.strip()
6. Benutzeroberfläche mit Flask
Erstelle die Flask-App (app.py):
from flask import Flask, render_template, request
from pymongo import MongoClient
from ki_helper import generate_response
# Flask-App initialisieren
app = Flask(__name__)
# Verbindung zur MongoDB
client = MongoClient("mongodb://localhost:27017/")
db = client["firmendaten"]
collection = db["fullsite"]
def search_mongodb(question):
"""
Führt eine Volltextsuche in MongoDB aus und gibt relevante Ergebnisse zurück.
"""
results = collection.find(
{"$text": {"$search": question}},
{"score": {"$meta": "textScore"}}
).sort("score", {"$meta": "textScore"}).limit(3)
return list(results)
@app.route('/', methods=['GET', 'POST'])
def index():
if request.method == 'POST':
question = request.form['question']
results = search_mongodb(question)
if not results:
return render_template('result.html', question=question, response="Keine relevanten Daten gefunden.")
response = generate_response(question, results)
return render_template('result.html', question=question, response=response)
return render_template('index.html')
if __name__ == '__main__':
app.run(debug=True)
# Your X API credentials
consumer_key = "SECRET_CREDENTIAL"
consumer_secret = "SECRET_CREDENTIAL"
access_token = "SECRET_CREDENTIAL"
access_token_secret = "SECRET_CREDENTIAL"
bearer_token = "SECRET_CREDENTIAL"
import os
from dotenv import load_dotenv
import tweepy
# load .env-Cile
load_dotenv()
# Create a client instance for Twitter API v2
client = tweepy.Client(bearer_token=os.getenv("bearer_token"))
# Fetch a user by username
username = "IngoKaulbachQS"
user = client.get_user(username=username)
# Access the user information
print(f"User ID: {user.data.id}")
print(f"Username: {user.data.username}")
print(f"Name: {user.data.name}")
print(f"User ID: {user}")
UPDATE
Updated requirement from "dotenv" to "python-dotenv".
Error messages were not helpfull, neither AI-Systems. Classic googeling and try-and-error did the job. This is no fun. Python could have done better.
According to OpenAPI documentation this is a sample code to generate Speech from Text:
from pathlib import Path
from openai import OpenAI
client = OpenAI()
speech_file_path = Path(__file__).parent / "speech.mp3"
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input="Today is a wonderful day to build something people love!"
)
response.stream_to_file(speech_file_path)
To execute this sample I have to install openai first:
pip install openai
To play the mp3-file I have to install ffmpeg first:
sudo apt install ffmpeg
Create mp3 and play it:
# run sample code
python sample.py
# play soundfile
ffplay speech.mp3
Play MP3 with Python
Install pygame:
pip install pygame
from pathlib import Path
import pygame
def play_mp3(file_path):
pygame.mixer.init()
pygame.mixer.music.load(file_path)
pygame.mixer.music.play()
# Keep the program running while the music plays
while pygame.mixer.music.get_busy():
pygame.time.Clock().tick(10)
# Usage
speech_file_path = Path(__file__).parent / "speech.mp3"
play_mp3(speech_file_path)
python playmp3.py
Read Heise Article
from dotenv import load_dotenv
from pathlib import Path
from openai import OpenAI
import selenium.webdriver as webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import pygame
def scrape_website(website):
print("Launching chrome browser...")
service = Service()
options = Options()
options.headless = True # Headless-Modus aktivieren, um den Browser unsichtbar zu machen
driver = webdriver.Chrome(service=service, options=options)
try:
driver.get(website)
print("Page loaded...")
html = driver.page_source
return html
finally:
driver.quit()
def split_dom_content(dom_content, max_length=6000):
return [
dom_content[i : i + max_length] for i in range(0, len(dom_content), max_length)
]
def scrape_heise_website(website):
html = scrape_website(website)
# BeautifulSoup zum Parsen des HTML-Codes verwenden
soup = BeautifulSoup(html, 'html.parser')
# Artikel-Header und -Inhalt extrahieren
# Der Header ist oft in einem
-Tag zu finden
header_title = soup.find('h1', {'class': 'a-article-header__title'}).get_text().strip()
header_lead = soup.find('p', {'class': 'a-article-header__lead'}).get_text().strip()
# Der eigentliche Artikelinhalt befindet sich oft in einem
-Tag mit der Klasse 'article-content'
article_div = soup.find('div', {'class': 'article-content'})
paragraphs = article_div.find_all('p') if article_div else []
# 'redakteurskuerzel' entfernen
for para in paragraphs:
spans_to_remove = para.find_all('span', {'class': 'redakteurskuerzel'})
for span in spans_to_remove:
span.decompose() # Entfernt den Tag vollständig aus dem Baum
article_content = "\n".join([para.get_text().strip() for para in paragraphs])
return article_content
# Header und Artikelinhalt ausgeben
#result = "Header Title:" + header_title + "\nHeader Lead:" + header_lead + "\nContent:" + article_content
#return result
def article_to_mp3(article_content):
client = OpenAI()
speech_file_path = Path(__file__).parent / "speech.mp3"
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input=article_content
)
response.stream_to_file(speech_file_path)
def play_mp3():
speech_file_path = Path(__file__).parent / "speech.mp3"
pygame.mixer.init()
pygame.mixer.music.load(speech_file_path)
pygame.mixer.music.play()
# Keep the program running while the music plays
while pygame.mixer.music.get_busy():
pygame.time.Clock().tick(10)
# .env-Datei laden#
load_dotenv()
article_content = scrape_heise_website("https://www.heise.de/news/Streit-ueber-Kosten-Meta-kappt-Leitungen-zur-Telekom-9953162.html")
article_to_mp3(article_content)
play_mp3()
Open WSL Terminal, switch into the folder for my Web Scraping project and create a virtual environment first.
# Python virtual Environment
## Install
### On Debian/Ubuntu systems, you need to install the python3-venv package
sudo apt install python3.10-venv -y
python3 -m venv ai
## Activate
source ai/bin/activate
Visual Code
Open Visual Code IDE with code .
Change Python Interpreter to the one of virtual Environment
When working in a Terminal window in VS then the virtual environment has also to be activated in this terminal window: source ai/bin/activate
Requirements
I put all required external libraries and their specific versions my project relies on in a seperate file: requirements.txt. In Python projects this is considered best practice.
selenium
Installation:
pip install -r requirements.txt
Selenium
Selenium is a powerful automation tool for web browsers. It allows you to control web browsers programmatically, simulating user interactions like clicking buttons, filling out forms, and navigating between pages. This makes it ideal for tasks such as web testing, web scraping, and browser automation.
As of Selenium 4.6, Selenium downloads the correct driver for you. You shouldn’t need to do anything. If you are using the latest version of Selenium and you are getting an error, please turn on logging and file a bug report with that information. Quelle
So installation of Google Chrome and Google Chrome Webdriver is not required anymore. But I had to install some additional libraries on WSL:
sudo apt install libnss3 libgbm1 libasound2
Exkurs: Google Chrome
To find missing libraries I downloaded Google Chrome and tried to start it until all missing libraries were installed.
## Google Chrome
wget https://storage.googleapis.com/chrome-for-testing-public/129.0.6668.70/linux64/chrome-linux64.zip
unzip chrome-linux64.zip
mv chrome-linux64 chrome
## Google Chrome Webdriver
wget https://storage.googleapis.com/chrome-for-testing-public/129.0.6668.70/linux64/chromedriver-linux64.zip
unzip chromedriver-linux64.zip
mv chromedriver-linux64 chromedriver
cp chromedriver/chromedriver chrome/chromedriver
cd chrome
./chromedriver
Scrape a single page
import selenium.webdriver as webdriver
from selenium.webdriver.chrome.service import Service
def scrape_website(website):
print("Launching chrome browser...")
driver= webdriver.Chrome()
try:
driver.get(website)
print("Page loaded...")
html = driver.page_source
return html
finally:
driver.quit()
print(scrape_website("https://www.selenium.dev/"))
python scrape.py
Scape a Heise News Article
Extract Article Header, Article Lead and Article itself:
import selenium.webdriver as webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
def scrape_website(website):
print("Launching chrome browser...")
service = Service()
options = Options()
options.headless = True # Headless-Modus aktivieren, um den Browser unsichtbar zu machen
driver = webdriver.Chrome(service=service, options=options)
try:
driver.get(website)
print("Page loaded...")
html = driver.page_source
return html
finally:
driver.quit()
def split_dom_content(dom_content, max_length=6000):
return [
dom_content[i : i + max_length] for i in range(0, len(dom_content), max_length)
]
def scrape_heise_website(website):
html = scrape_website(website)
# BeautifulSoup zum Parsen des HTML-Codes verwenden
soup = BeautifulSoup(html, 'html.parser')
# Artikel-Header und -Inhalt extrahieren
# Der Header ist oft in einem
-Tag zu finden
header_title = soup.find('h1', {'class': 'a-article-header__title'}).get_text().strip()
header_lead = soup.find('p', {'class': 'a-article-header__lead'}).get_text().strip()
# Der eigentliche Artikelinhalt befindet sich oft in einem
-Tag mit der Klasse 'article-content'
article_div = soup.find('div', {'class': 'article-content'})
paragraphs = article_div.find_all('p') if article_div else []
# 'redakteurskuerzel' entfernen
for para in paragraphs:
spans_to_remove = para.find_all('span', {'class': 'redakteurskuerzel'})
for span in spans_to_remove:
span.decompose() # Entfernt den Tag vollständig aus dem Baum
article_content = "\n".join([para.get_text().strip() for para in paragraphs])
# Header und Artikelinhalt ausgeben
result = "Header Title:" + header_title + "\nHeader Lead:" + header_lead + "\nContent:" + article_content
return result
result = scrape_heise_website("https://www.heise.de/news/Streit-ueber-Kosten-Meta-kappt-Leitungen-zur-Telekom-9953162.html")
print(result)
I was on JCON 2024 and beside other interesting talks I heard one talk about cloud-based IDEs, and I wanted to try out, if GitHub Codespaces could work for me.
Explore the evolving landscape of cloud-based integrated development environments (IDEs), focusing on Gitpod, GitHub codespaces and Devpod. Compare and contrast these cloud IDEs with traditional counterparts, emphasizing the role of container technology, specifically the devcontainer specification. The discussion includes advances, existing limitations, and the potential for developing polyglot, container-based distributed applications. A live demo illustrates the rapid setup and coding process across various languages and frameworks, showcasing testing capabilities and seamless deployment to Kubernetes. Discover how custom additions enhance flexibility. Additionally, uncover the impact of cloud IDEs on teaching and team projects, ensuring consistent development setups for enhanced efficiency and streamlined processes.
[EN] Codespaces, Gitpod, Devpod ... what cloud and container-based IDEs can do for you by Matthias Haeussler (Novatec Consulting GmbH)
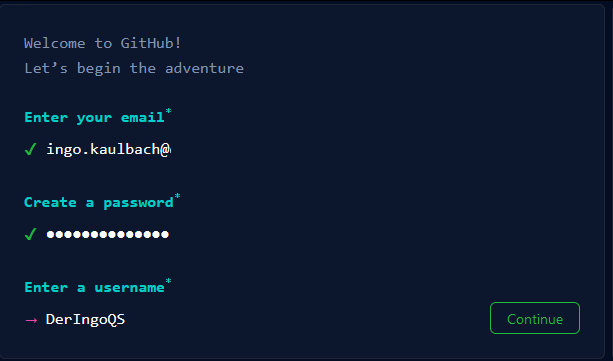
Create GitHub Account
Go to GitHub and create an account. Free plan is suitable.
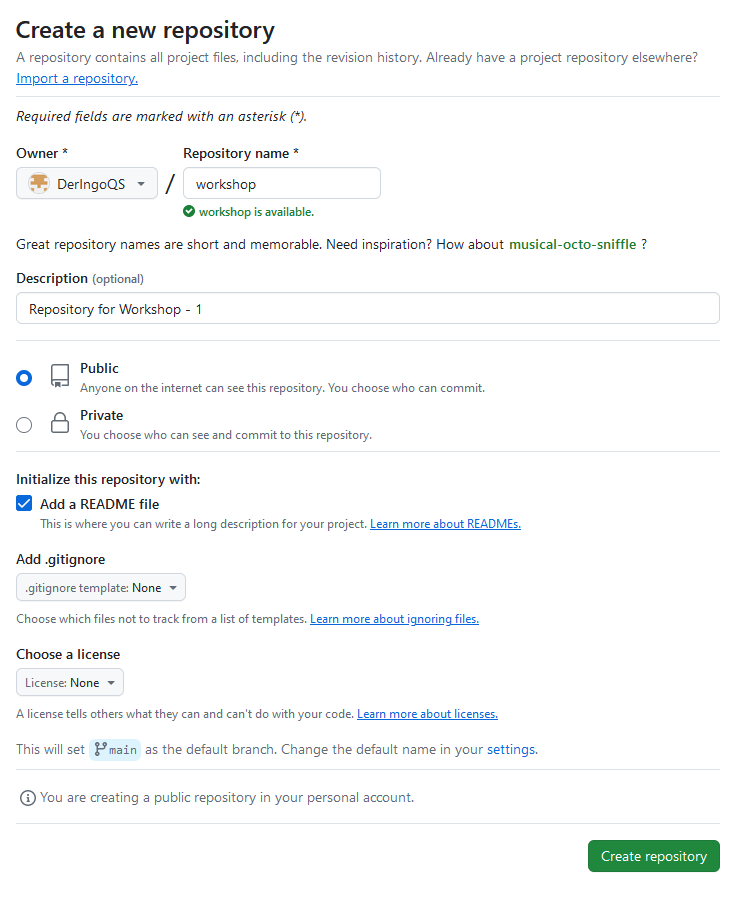
Create Repository
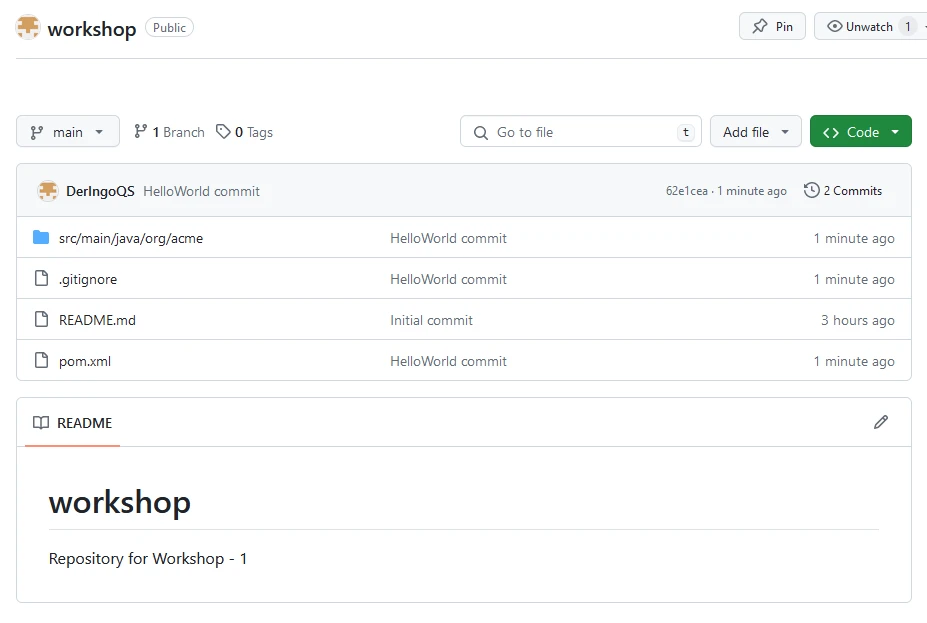
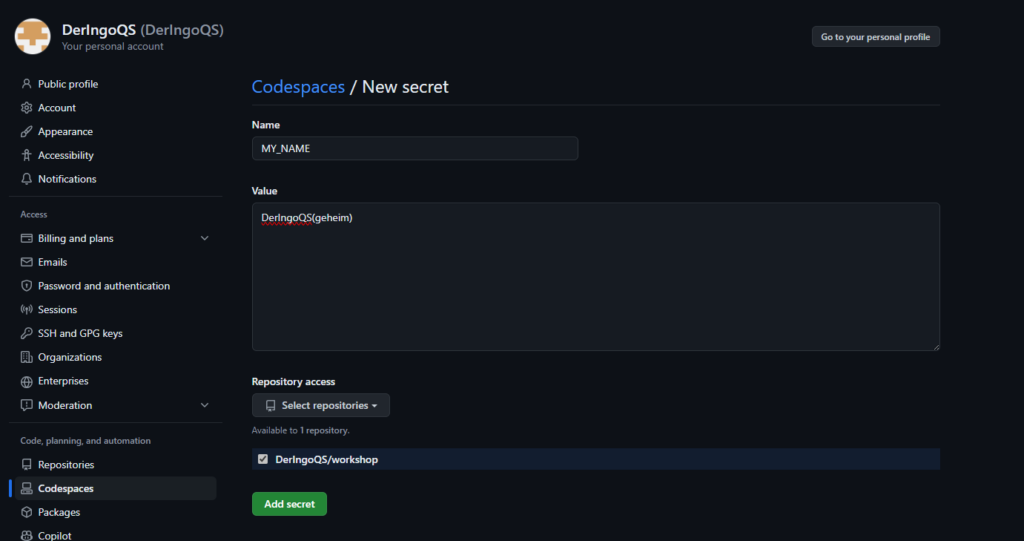
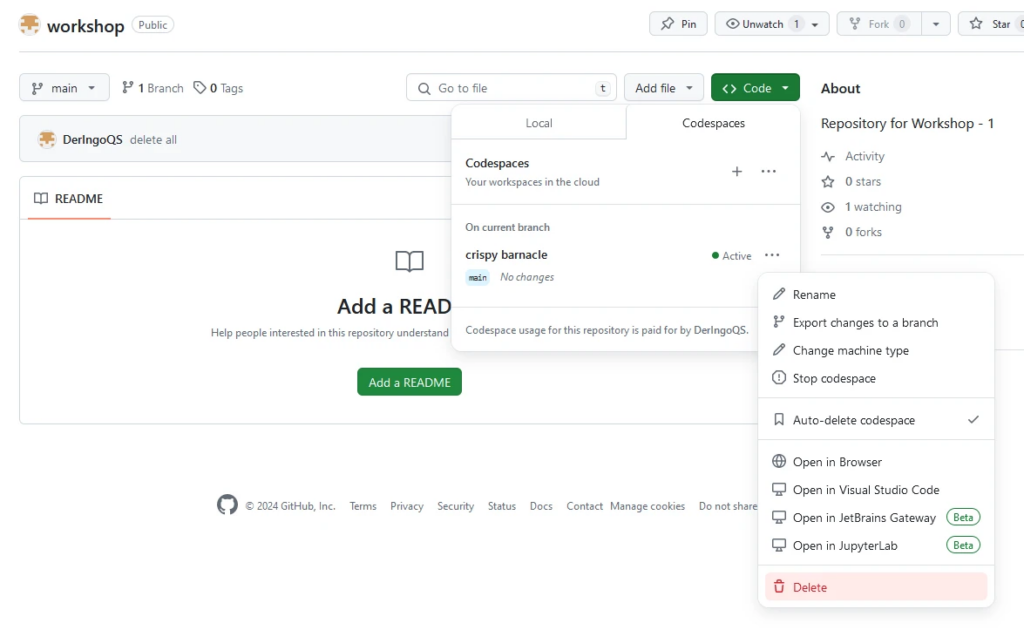
Create a new repository with name “workshop”. Add a README file.
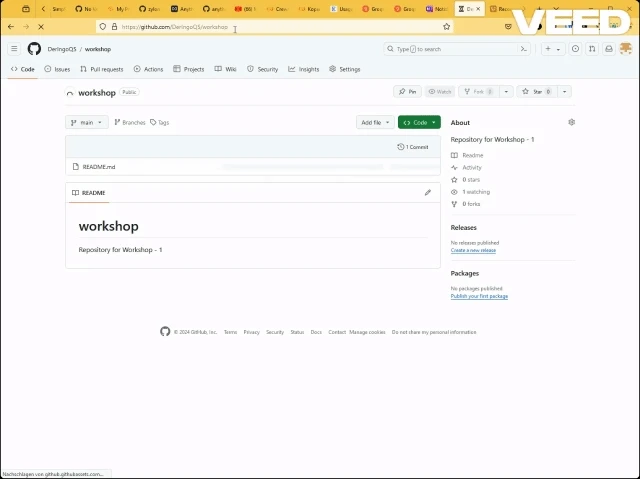
Create Codespace
TODO: funktioniert das GIF?
Change Keyboard Layout to German: In the lower right corner click on “Layout: US” and enter “German” in the upcoming window.
TODO: Ich hätte gerne die Sprache von Visual Code auf Englisch umgestellt. Wie?
Work in the Terminal
Copy & Paste
Type something into the terminal. Mark it with your mouse. One Right Click to copy into Clipboard. Another Right Click to paste from Clipboard.
Timezone
Set Timzone to Europe -> Berlin
sudo dpkg-reconfigure tzdata
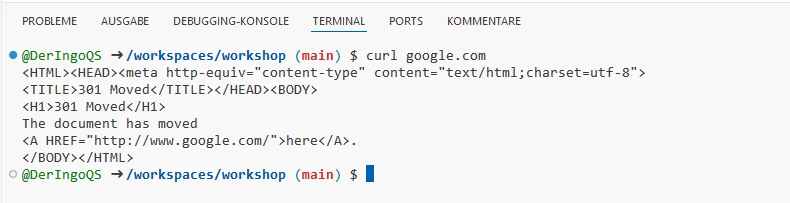
Internet
Do we have access to the Internet? Let’s try with curl:
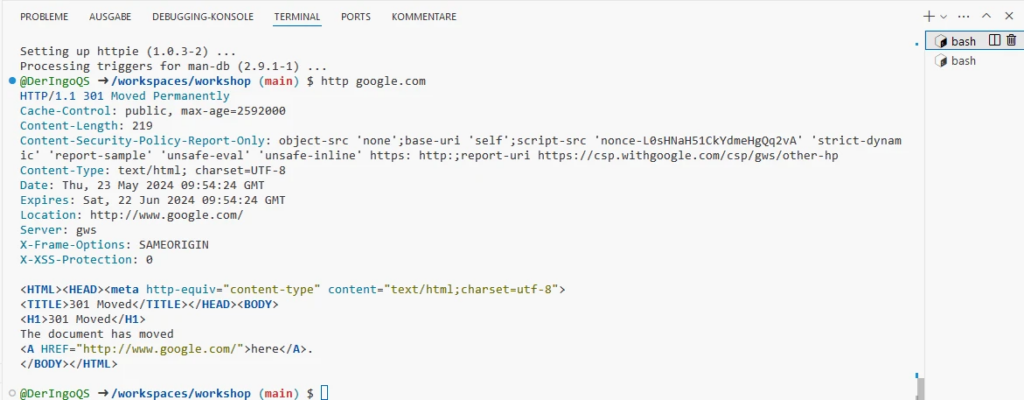
This will take a few minutes. Meanwhile we can work in another Terminal window. Later we come back and test HTTPie:
http google.com
Additional Terminal window
Open a second Terminal with bash:
VIM
ls -lisah
touch test.sh
ls -lisah
vim test.sh
chmod +x test.sh
./test.sh
name=Ingo
echo "My name is $name"
echo "But here I am: $(whoami)"
Python
Do we have Python in our Codespace? Which version(s)?
python3 --version
python --version
vim hello_world.py
python hello_world.py
# Print "Hello World" to the console
print("Hello World")
Docker
docker --version
docker-compose --version
docker run hello-world
Apache HTTPD
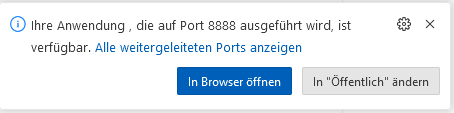
docker run -p 8888:80 httpd
Open in Browser:
Find all open Ports in the Ports-Tab:
Normally Port 8888 should be listed here. We need to add Port, just enter 8888:
Open Website just with a click on the Globus-Icon.
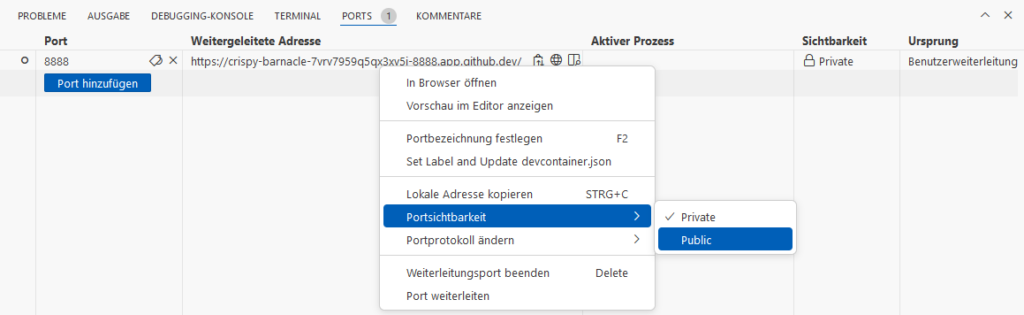
When we try to open the address in another browser, we will see a GitHub-Login. When we login with another GitHub-Account, we will get a 404-error. Because the page is Private. Switch to Public:
Now we can access the page in another brower.
At the end we can shutdown HTTPD with + in Terminal window. It should automatically disapear in the Ports-Tab. If not, you can remove it manually.
Microsoft Edge - Caching problem
Open the Public page in MS Edge. Make the page Private again. Try to open in a new browser, won’t work. Reload (the Public loaded) page in MS Edge: You can still see the site! This is a cached version and we need to force MS Edge to reload from server.
Open Developer Tools (F12 or ++), then you can Right Click on the reload button to have additional options:
Java
java --version
vim HelloWorld.java
javac HelloWorld.java
java HelloWorld
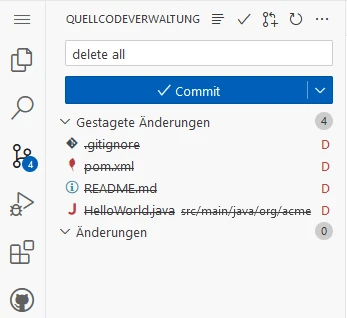
rm -f HelloWorld*
class HelloWorld {
public static void main(String args[]) {
System.out.println("Hello World");
}
}
Run Java Source as Shell Scripts
type -a java
# java is /home/codespace/java/current/bin/java
# java is /usr/local/sdkman/candidates/java/current/bin/java
vim HelloWorld.sh
chmod +x HelloWorld.sh
./HelloWorld.sh
rm HelloWorld.sh
#!/home/codespace/java/current/bin/java --source 21
class HelloWorld {
public static void main(String args[]) {
System.out.println("Hello World");
}
}
Maven
Start
We create a new pom.xml from scratch. We need a template. We will take “The Basics”-one from the Apache Maven POM Reference page.
4.0.0org.codehaus.mojomy-project1.0
mvn --version
vim pom.xml
mvn clean verify
Sample Project
Open pom.xml in Explorer (GUI) and change:
org.codehaus.mojo to org.acme
my-project to workshop
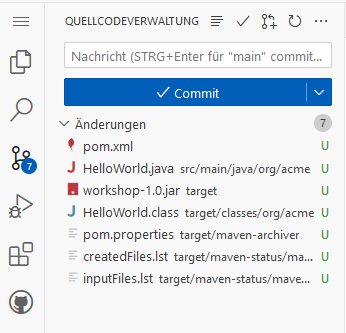
No need to save: Changes are automatically saved
To doublecheck that everything is still ok run mvn clean verify again.