Ich musste grade von meiner Postgres-DB einen Dump ziehen und auf eine zweite DB wieder einspielen.
Problem dabei: ich habe Postgres (pg_dump, psql) nicht auf meinem Host System installiert und möchte daher Docker verwenden.
Zuerst habe ich alle relevanten Parameter in eine Datei (.env) gespeichert:
Anschließend habe ich die Parameter (zB Hostname) für das Zielsystem angepasst und wieder source .env ausgeführt um dann das Backup auf der Ziel-DB einspielen zu können:
MongoDB ist eine dokumentenbasierte NoSQL-Datenbank, die JSON-ähnliche Datenstrukturen (BSON) verwendet. Sie wurde entwickelt, um eine hohe Flexibilität und Skalierbarkeit zu bieten, und ist besonders geeignet für Anwendungen mit dynamischen oder unstrukturierten Daten.
Vorteile von MongoDB
Schemaflexibilität: Dokumente in einer Collection können unterschiedliche Felder und Strukturen aufweisen.
Hohe Skalierbarkeit: Unterstützt horizontales Sharding zur Verteilung von Daten über mehrere Server.
JSON-ähnliches Format: BSON erleichtert die Integration mit modernen Programmiersprachen.
Eingebaute Replikation: Daten werden automatisch über Replikatsets gesichert.
Leistungsfähige Abfragen: Unterstützung für Indexe, Aggregationen und komplexe Suchanfragen.
Open Source: Große Community und kostenlose Nutzung (mit kostenpflichtigen Enterprise-Optionen).
Typische Einsatzgebiete
Web- und Mobilanwendungen: Speicherung von Benutzerdaten, Sitzungsinformationen oder dynamischen Inhalten.
IoT: Speicherung und Verarbeitung von Sensordaten.
Content-Management-Systeme (CMS): Flexible Datenmodelle für Inhalte und Metadaten.
Echtzeit-Analysen: Verarbeitung von Ereignisdaten für Dashboards oder Monitoring.
Geodaten-Anwendungen: Speicherung und Abfragen von Standortdaten.
Mit MongoDB lassen sich schnell und effizient Anwendungen entwickeln, die mit dynamischen Datenstrukturen und wachsendem Datenvolumen umgehen können.
Installation von MongoDB mit Docker
Schritte zur Installation von MongoDB mit Docker
MongoDB-Image herunterladen:
docker pull mongo:latest
Dies lädt das neueste MongoDB-Docker-Image aus dem offiziellen Docker Hub.
--name mongodb: Gibt dem Container den Namen mongodb.
-p 27017:27017: Bindet den MongoDB-Port (Standard: 27017) an den Host.
-v mongodb_data:/data/db: Erstellt ein Docker-Volume für die persistente Speicherung der Daten unter /data/db.
Überprüfung des Containers:
docker ps
Dies zeigt eine Liste der laufenden Container. Der mongodb-Container sollte in der Liste erscheinen.
Logs überprüfen (optional):
Um sicherzustellen, dass der Container ordnungsgemäß läuft, kannst du die Logs abrufen:
docker logs mongodb
Container stoppen und entfernen (bei Bedarf):
Stoppen:
docker stop mongodb
Entfernen:
docker rm mongodb
Hinweis
Die Konfiguration verwendet keine Authentifizierung. Für produktive Umgebungen sollte ein Benutzer mit Passwort eingerichtet werden, und der Zugriff auf die Datenbank sollte über eine Firewall geschützt sein.
Clients
1. MongoDB Compass
Beschreibung: Das offizielle GUI-Tool von MongoDB.
Vorteile:
Einfache Installation und Nutzung.
Intuitive Benutzeroberfläche für Abfragen und Datenvisualisierung.
Unterstützt erweiterte Funktionen wie Aggregations-Pipelines.
Ersetze <username> und <password> mit den von dir erstellten Anmeldedaten.
Testen der Verbindung (Beispiel mit Python):
Installiere die offizielle Python-Bibliothek pymongo:
pip install pymongo
Beispielcode:
from pymongo import MongoClient
# Verbindung zu Atlas-Cluster herstellen
uri = "mongodb+srv://<username>:<password>@<cluster-name>.mongodb.net/?retryWrites=true&w=majority"
client = MongoClient(uri)
# Test der Verbindung
try:
print("MongoDB-Version:", client.server_info()["version"])
except Exception as e:
print("Verbindung fehlgeschlagen:", e)
Cluster-Verwaltung:
Über das Atlas-Dashboard kannst du:
Datenbanken erstellen und Collections verwalten.
Aggregationen und Abfragen durchführen.
Performance überwachen (beschränkt in der Free-Tier-Version).
Vorteile von Atlas-Free-Tier:
Kostenlos: Bis zu 512 MB Speicherplatz.
Hohe Verfügbarkeit: Automatische Replikation auf mehrere Nodes.
Einfache Verwaltung: Intuitive Oberfläche zur Verwaltung von Clustern und Benutzern.
Schnelle Skalierbarkeit: Möglichkeit, bei Bedarf auf kostenpflichtige Pläne zu upgraden.
use <database>
db.fullsite.createIndex(
{ cleaned_text: "text" }, // Das Feld, das durchsucht werden soll
{ default_language: "german" } // Sprache für den Textindex
);
Beispiel
Ich möchte die Datenbank aus dem letzten Artikel Webseitendaten Assistent KI in die Cloud bringen.
Die Datenmenge ist allerdings zu groß, so dass ich zuerste die Rohdaten löschen muss. Anschließend kann ich den Dump erstellen, in die Cloud hoch laden und abschließend den Index erstellen.
Datenmenge verkleinern
docker exec -it CompanyDataAI-mongo mongosh
use firmendaten
show dbs
db.stats()
db.fullsite.updateMany(
{},
{ $unset: { fieldName: "raw_html" } }
)
show dbs
db.stats()
Laut show dbs ist die Datenbank 335 MB groß, der Dump ist allerdings 1,3 GB groß.
Die Erklärung ist vermutlich, dass die Daten in der Datenbank komprimiert sind, im Dump hingegen nicht.
Die freie Cloud Datenbank hat aber nur einen Speicher von 512 MB.
Als Lösungsansatz versuchen wir einen komprimierten Dump (190 MB):
Leider wird auch dadurch das Problem nicht gelöst:
Failed: firmendaten.fullsite: error restoring from /dump/firmendaten/fullsite.bson.gz: (AtlasError) you are over your space quota, using 526 MB of 512 MB
Daher habe ich den nicht komplett importierten Dump gelöscht und dann das Scraping-Tool mit der Cloud-DB verbunden und neu durchlaufen lassen. Das hat dann auch funktioniert, allerdings war das setzen des Index dann zu groß. Vielleicht hätte der Dump/Restore funktioniert, wenn ich vorher den Index in der lokalen DB gelöscht hätte?
use firmendaten
db.fullsite.createIndex(
{ cleaned_text: "text" }, // Das Feld, das durchsucht werden soll
{ default_language: "german" } // Sprache für den Textindex
);
Leider bricht der Vorgang ab: you are over your space quota.
Fazit
Die Datenbankgröße von 512MB im Free Tier ist nicht ausreichend.
Denn leider ist damit nicht der Speicher auf dem Filesystem gemeint (storageSize), den man mit show dbs sehen kann, sondern die Größe der Daten (dataSize) die man mit db.stats() sehen kann.
Damit ist die Datenbank leider nicht für mein Projekt zu gebrauchen.
Workaround
Um mit meinem PoC weiter zu kommen, lösche ich irgendwelche Daten und überlege mir später eine andere Lösung:
Ich möchte einen virtuellen Assistenten erstellen, der auf Informationen von mehreren Webseiten basiert. Ziel ist es, aus den Daten relevante Informationen bereitzustellen und auf Fragen der Benutzer zu antworten.
Da ich keine klaren Informationen über die Struktur der Webseiteninhalte hatte, wollte ich zunächst alle Seiten vollständig speichern und später bereinigen. Die Lösung soll dynamisch erweiterbar sein und folgende Schwerpunkte abdecken:
Web Scraping: Automatisches Sammeln von Rohdaten von verschiedenen Webseiten.
Speicherung: Daten in MongoDB speichern, sowohl Rohdaten als auch bereinigte Daten.
Durchsuchbarkeit: Daten mit einem Full-Text-Index durchsuchbar machen.
KI-Integration: Eine lokale KI-Instanz (Teuken-7B von OpenGPT-X) verwenden, die mit allen 24 europäischen Amtssprachen trainiert wurde, um Benutzerfragen in natürlicher Sprache zu beantworten.
Benutzeroberfläche: Ein Web-Interface für eine einfache und intuitive Nutzung der Lösung.
Lösungsansatz
Web Scraping mit Scrapy:
Automatisches Sammeln von HTML-Rohdaten von mehreren Webseiten.
Dynamisches Einlesen von Start-URLs.
Bereinigung der Daten während des Scrapings (HTML-Tags entfernen, Boilerplate entfernen, Texte kürzen).
Datenhaltung mit MongoDB:
Rohdaten und bereinigte Texte wurden parallel gespeichert, um flexibel zu bleiben.
Full-Text-Index mit deutscher Spracheinstellung eingerichtet, um die bereinigten Texte effizient zu durchsuchen.
KI-Integration mit Teuken-7B:
Übergabe der MongoDB-Ergebnisse als Kontext an das Sprachmodell Teuken-7B.
Das Modell generiert eine präzise Antwort auf die Benutzerfrage, basierend auf den bereitgestellten Daten.
Web-App mit Flask:
Einfache Benutzeroberfläche, um Fragen zu stellen und KI-Antworten anzuzeigen.
Verbindung von Flask mit MongoDB und der KI für dynamische Abfragen.
Architektur
1. Datensammlung
Tool: Scrapy.
Datenquellen: Liste von Start-URLs (mehrere Domains).
Prozess:
Besuch der Startseiten.
Rekursive Erfassung aller Links innerhalb der erlaubten Domains.
Speicherung der Rohdaten (HTML) und bereinigten Daten (Text).
2. Datenhaltung
Datenbank: MongoDB.
Struktur:
{
"url": "https://www.example.com/about",
"raw_html": "<html>...</html>",
"cleaned_text": "This is an example text.",
"timestamp": "2024-11-26T12:00:00Z"
}
Full-Text-Index:
Feld: cleaned_text.
Sprache: Deutsch.
3. Datenanalyse
Abfragen:
MongoDB-Textsuche mit Unterstützung für Wortstämme (z. B. „Dienstleistung“ und „Dienstleistungen“).
Priorisierung der Ergebnisse nach Relevanz (score).
4. KI-Integration
KI-Tool: Teuken-7B (OpenGPT-X).
Prozess:
Übergabe der MongoDB-Ergebnisse als Kontext an die KI.
Generierung einer präzisen Antwort basierend auf der Benutzerfrage.
5. Benutzeroberfläche
Framework: Flask.
Funktionen:
Eingabeformular für Benutzerfragen.
Anzeige der KI-Antwort und der relevanten Daten.
Einfache und intuitive Navigation.
Implementierung
1. Überblick über die Implementierungsschritte
Wir setzen die zuvor beschriebenen Schritte um:
Web Scraping mit Scrapy: Erfassen von Daten von mehreren Webseiten.
Datenhaltung mit MongoDB: Speicherung der Roh- und bereinigten Daten.
Full-Text-Index: Einrichten eines deutschen Index in MongoDB.
KI-Integration mit Teuken-7B: Verarbeitung von Benutzerfragen mit einer lokalen Instanz.
Benutzeroberfläche mit Flask: Web-Interface zur Interaktion mit dem virtuellen Assistenten.
2. Web Scraping: FullSiteSpider
Erstelle einen Scrapy-Spider (spiders/fullsite_spider.py), der mehrere Domains und Seiten crawlt.
import scrapy
from bs4 import BeautifulSoup
class FullSiteSpider(scrapy.Spider):
name = "fullsite"
# Liste der erlaubten Domains und Start-URLs
allowed_domains = ["example.com", "example2.com", "example3.org"]
start_urls = [
"https://www.example.com",
"https://www.example2.com",
"https://www.example3.org/start"
]
def parse(self, response):
# Rohdaten speichern
raw_html = response.body.decode('utf-8')
# Bereinigung der HTML-Daten
cleaned_text = self.clean_html(raw_html)
# Speichern der Daten
yield {
'url': response.url,
'raw_html': raw_html,
'cleaned_text': cleaned_text,
'timestamp': response.headers.get('Date', '').decode('utf-8'),
}
# Folge allen Links auf der Seite
for link in response.css('a::attr(href)').getall():
if link.startswith('http') or link.startswith('/'):
yield response.follow(link, self.parse)
def clean_html(self, html_content):
"""Bereinigt HTML und extrahiert lesbaren Text."""
soup = BeautifulSoup(html_content, 'html.parser')
text = soup.get_text(separator=" ").strip()
return " ".join(text.split())
3. Datenhaltung: MongoDB Pipeline
Speichere die gescrapten Daten direkt in MongoDB.
import pymongo
import json
class MongoPipeline:
def __init__(self):
# Konfiguration aus Datei laden
with open('config.json') as config_file:
config = json.load(config_file)
self.mongo_uri = config['MONGO_URI']
self.mongo_db = config['MONGO_DATABASE']
def open_spider(self, spider):
# Verbindung zur MongoDB herstellen
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
# Verbindung schließen
self.client.close()
def process_item(self, item, spider):
# Daten in MongoDB speichern
collection = self.db[spider.name]
collection.insert_one({
'url': item['url'],
'raw_html': item['raw_html'],
'cleaned_text': item['cleaned_text'],
'timestamp': item['timestamp'],
})
return item
from openai import OpenAI
# Verbindung zur lokalen KI
local_ai = OpenAI(base_url="http://127.0.0.1:1234/v1", api_key="lm-studio")
def generate_response(question, results):
"""
Generiert eine Antwort mit der lokalen KI basierend auf den MongoDB-Ergebnissen.
"""
# Kontext aus den MongoDB-Ergebnissen erstellen
context = "\n".join(
[f"URL: {doc['url']}\nText: {doc['cleaned_text']}" for doc in results]
)
# Nachrichtenformat für die KI
messages = [
{"role": "system", "content": "Du bist ein virtueller Assistent für Firmendaten."},
{"role": "user", "content": f"Hier sind die Daten:\n{context}\n\nFrage: {question}"}
]
# Anfrage an die lokale KI
response = local_ai.chat.completions.create(
model="teuken-7b",
messages=messages,
temperature=0.7
)
return response.choices[0].message.content.strip()
6. Benutzeroberfläche mit Flask
Erstelle die Flask-App (app.py):
from flask import Flask, render_template, request
from pymongo import MongoClient
from ki_helper import generate_response
# Flask-App initialisieren
app = Flask(__name__)
# Verbindung zur MongoDB
client = MongoClient("mongodb://localhost:27017/")
db = client["firmendaten"]
collection = db["fullsite"]
def search_mongodb(question):
"""
Führt eine Volltextsuche in MongoDB aus und gibt relevante Ergebnisse zurück.
"""
results = collection.find(
{"$text": {"$search": question}},
{"score": {"$meta": "textScore"}}
).sort("score", {"$meta": "textScore"}).limit(3)
return list(results)
@app.route('/', methods=['GET', 'POST'])
def index():
if request.method == 'POST':
question = request.form['question']
results = search_mongodb(question)
if not results:
return render_template('result.html', question=question, response="Keine relevanten Daten gefunden.")
response = generate_response(question, results)
return render_template('result.html', question=question, response=response)
return render_template('index.html')
if __name__ == '__main__':
app.run(debug=True)
Performance-Analyse einer PostgreSQL-Datenbank mit pg_stat_statements
Bei einer Webanwendung mit einer PostgreSQL-Datenbank stießen wir auf Performance-Probleme. Hier beschreibe ich, wie man Performance-Probleme in PostgreSQL mittels der Erweiterung pg_stat_statements analysieren kann. Da die Erweiterung nicht auf der Produktivdatenbank installiert ist, zeige ich, wie man eine lokale Testumgebung aufsetzt.
Überblick der Vorgehensweise
Backup der Produktivdatenbank erstellen
Lokale Testdatenbank mit Docker aufsetzen
pg_stat_statements installieren und konfigurieren
Performance-Analyse durchführen
Vorbereitung
Zuerst prüfen wir die Version der Datenbank, um die passende Docker-Umgebung zu wählen:
SELECT version();
-- PostgreSQL 13.4
Backup erstellen
Das Backup erfolgt mittels Docker, um eine konsistente Umgebung zu gewährleisten. Hier das Script backup.sh:
Verwendet wird Port 6432, um Konflikte mit einer möglicherweise laufenden lokalen PostgreSQL-Instanz zu vermeiden.
Daten importieren
Das Backup wird dann in die lokale Datenbank importiert, über das Script import.sh:
#!/bin/bash
# Check if arguments were passed
if [ $# -eq 0 ]; then
echo "Error: No arguments provided"
echo "Usage: $0 "
exit 1
fi
# Check if file exists
if [ ! -f "$1" ]; then
echo "Error: $1 is not a valid file."
exit 1
fi
echo "File found: $1"
importfile=$(readlink -f "$1")
server=localhost
port=6432
username=myuser
password=PASSWORD
databasename=myuser
echo psql -h $server -U $username -d $databasename -f $importfile
docker run --rm \
--network=host \
-v $importfile:/script.sql \
-e PGPASSWORD=$password \
postgres:13.4-bullseye \
psql -h $server -p $port -U $username -d $databasename -f script.sql
pg_stat_statements installieren
Um pg_stat_statements zu aktivieren, müssen wir die PostgreSQL-Konfiguration anpassen. Dazu bearbeiten wir die postgresql.conf. Da in dem Postgres Container kein Editor enthalten ist, ex- und importieren wir die Datei, um sie bearbeiten zu können:
Die Sourcen des DBFSample finden sich wie immer im GitHub.
Das DBFSample ist ein PoC um eine DBF Datei mit Java verarbeiten zu können.
Im Projekt haben wir einige DBF Dateien erhalten, deren Daten wir importieren/verarbeiten müssen. Das soll nicht meine Aufgabe sein, aber ich möchte für den Fall vorbereitet sein, dass ich dabei unterstützen darf.
Ich brauche also erstmal nur verstehen, was eine DBF Datei ist und wie ich grundlegend damit arbeiten kann.
Was ist eine DBF Datei
Eine DBF-Datei ist eine Standarddatenbankdatei, die von dBASE, einer Datenbankverwaltungssystemanwendung, verwendet wird. Es organisiert Daten in mehreren Datensätzen mit Feldern, die in einem Array-Datentyp gespeichert sind.
Aufgrund der frühzeitigen Einführung in der Datenbank und einer relativ einfachen Dateistruktur wurden DBF-Dateien allgemein als Standardspeicherformat für strukturierte Daten in kommerziellen Anwendungen akzeptiert.
https://datei.wiki/extension/dbf
Wie kann ich eine DBF Datei öffnen?
DBeaver
Da es sich um ein Datenbankformat handelt und ich grade das Tool DBeaver in meinen Arbeitsalltag eingeführt habe, lag es für mich nahe, die Datei mit DBeaver zu öffnen.
Dazu musste ich einen Treiber zu DBeaver hinzufügen um anschließend die Datei öffnen zu können. Ich konnte dann die Tabellenstruktur sehen, aber nicht auf die Tabelle zugreifen. Es gab eine Fehlermeldung, dass eine weitere Datei fehlen würde.
java.sql.SQLException: nl.knaw.dans.common.dbflib.CorruptedTableException: Could not find file 'C:\dev\tmp\adress.dbt' (or multiple matches for the file)
DBeaver Stack-Trace
Diese andere Datei gibt es nicht und sie ist auch nicht für den Zugriff erforderlich, wie der erfolgreiche Zugriff über die anderen Wege beweist.
Etwas ausführlicher hatte ich es im Artikel zu DBeaver geschrieben.
Excel
Excel öffnen, DBF Datei reinziehen, Daten ansehen. Fertig, so einfach kann es gehen.
Ich hatte mich allerdings durch die Bezeichnung Standarddatenbankdatei ablenken lassen, so dass ich zuerst die Wege über DBeaver und Java versucht hatte.
Java
Für den Zugriff mit Java habe ich die Bibliothek JavaDBF verwendet.
Die beiden Testklassen JavaDBFReaderTest und JavaDBFReaderWithFieldNamesTest waren schnell angepasst und eine weiter Klasse zum Auslesen aller Daten ReadItAll war dann auch problemlos möglich. Dabei ignoriere ich die Datentypen und lese einfach alles als Strings ein. Für den PoC reicht das.
DBF in PostgresDB speichern
Als Beispiel, wie ich mit den Daten weiterarbeiten kann, importiere ich sie in eine Postgres Datenbank.
Dazu lese ich zuerst die sample.dbf ein und erzeuge dann eine Tabelle sample mit allen Columns, die in sample.dbf vorhanden sind. Anschließend wird die Tabelle zeilenweise gefüllt.
Das meiste ist hardcodiert und die Spalten sind alles Text-Spalten, da ich die Datentypen aus der DBF Datei nicht auslese, aber für den PoC reicht das.
Bisher hatte ich auf meine Postgres Datenbank per PG-Admin zugegriffen.
Ein Kollege hat mir heute DBeaver als Datenbanktool empfohlen.
Installation
Die Installation der DBeaver Community Version war in meinem Fall einfach das ZIP-File herunterladen, und nach C:\Program Files\dbeaver entpacken.
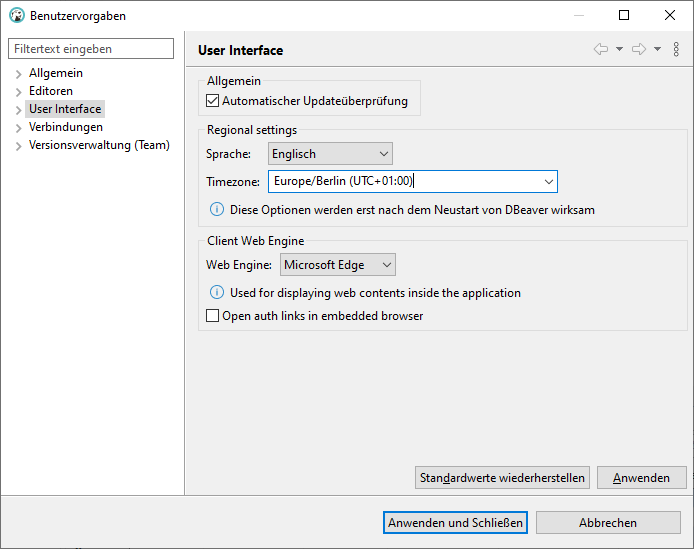
DBeaver erscheint in deutscher Lokalisation. Da aber die meisten Artikel über DBeaver auf Englisch sind, stelle ich auf Englisch um. Dazu auf Fenster -> Einstellungen gehen und im User Interface die Regional settings anpassen:
Im Unterpunkt User Interface -> Appearance stelle ich testweise das Theme auf Dark.
Meine Postgres Datenbank konnte ich mit den Verbindungsparametern anbinden, benötigte Treiber konnte DBeaver selbst nachladen.
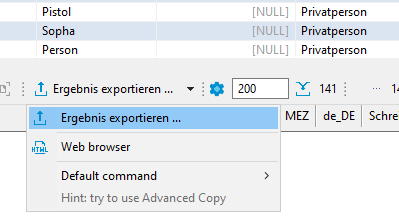
CSV Export
Für den CSV Export im Result-Tab auf "Ergebnis exportieren" klicken:
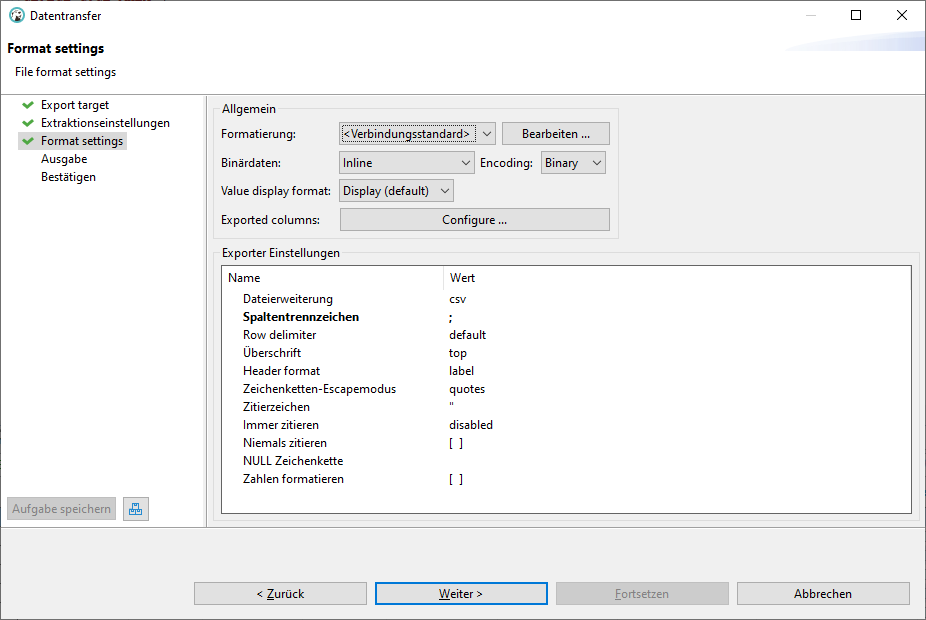
In den Format settings noch das Spaltentrennzeichen auf ";" für mein deutsches Excel ändern:
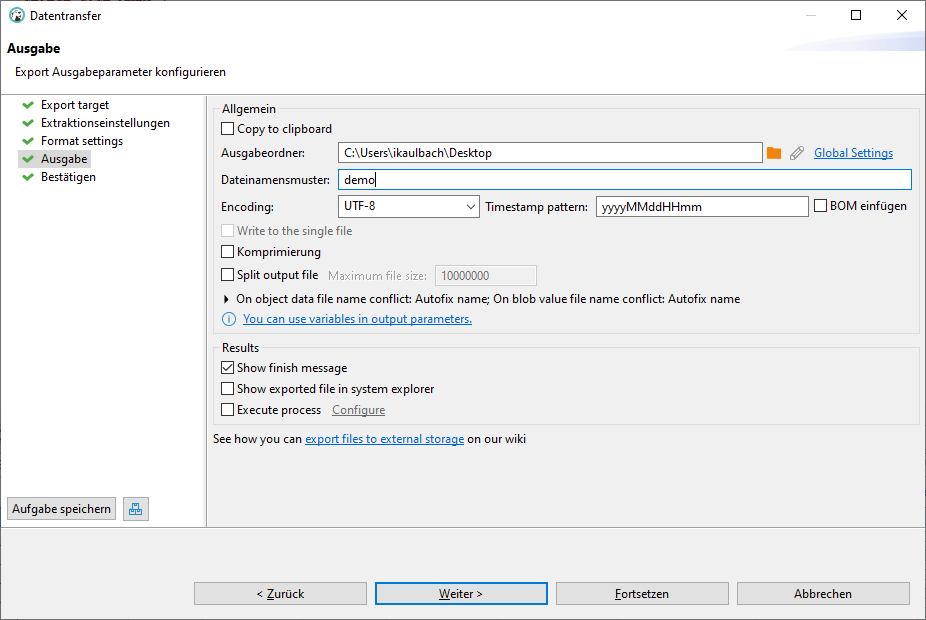
Im Ausgabetab den Ausgabeordner und Dateinamen, ohne Endung .csv, eingeben, Encoding auf UTF-8 belassen:
Trotz UTF-8 zeigt Excel die Umlaute nicht richtig an:
Die Ursache / Lösung konnte ich auf die Schnelle nicht finden. Zum Glück ist das grade nicht so wichtig, daher kann ich die Recherche vertragen.
dBase
Ich habe eine .dbf-Datei erhalten. Dabei handelt es sich anscheinend um einen dBase-Datenbank-Export. Diese Datei/Datenbank möchte ich mir mit DBeaver ansehen.
Dazu muss ich zuerst einen JDBC-Driver herunterladen. Nach kurzer Suche habe ich dieses Maven-Dependency gefunden, die ich in mein Maven Repository herunterlade:
com.wisecodersdbf-jdbc-driver1.1.2
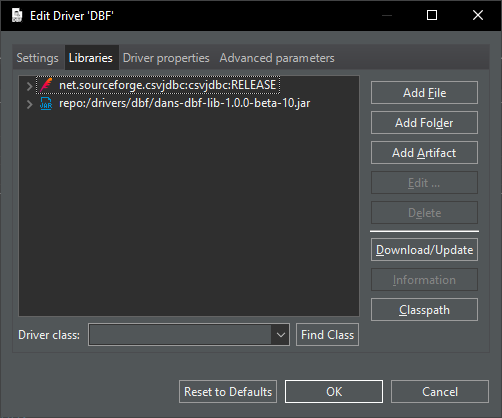
Um den Treiber zu DBeaver hinzuzufügen auf Database -> Driver Manager gehen:
und da mir das im Driver Manager zu viele Einstellungen waren, habe ich das erstmal gelassen und erstmal einen anderen Ansatz probiert:
download dans-dbf-lib-1.0.0-beta-10.jar (e.g. from sourceforge)
in Drivers location, Local folder (in Windows: C:\Users\user\AppData\Roaming\DBeaverData\drivers) create the \drivers\dbf directory. NB 'drivers' must be created under drivers, so ...\DBeaverData\drivers\drivers\...
put dans-dbf-lib-1.0.0-beta-10.jar in this folder
now you can create a new connection using the Embedded/DBF driver
Connection anlegen:
Im Database Navigator:
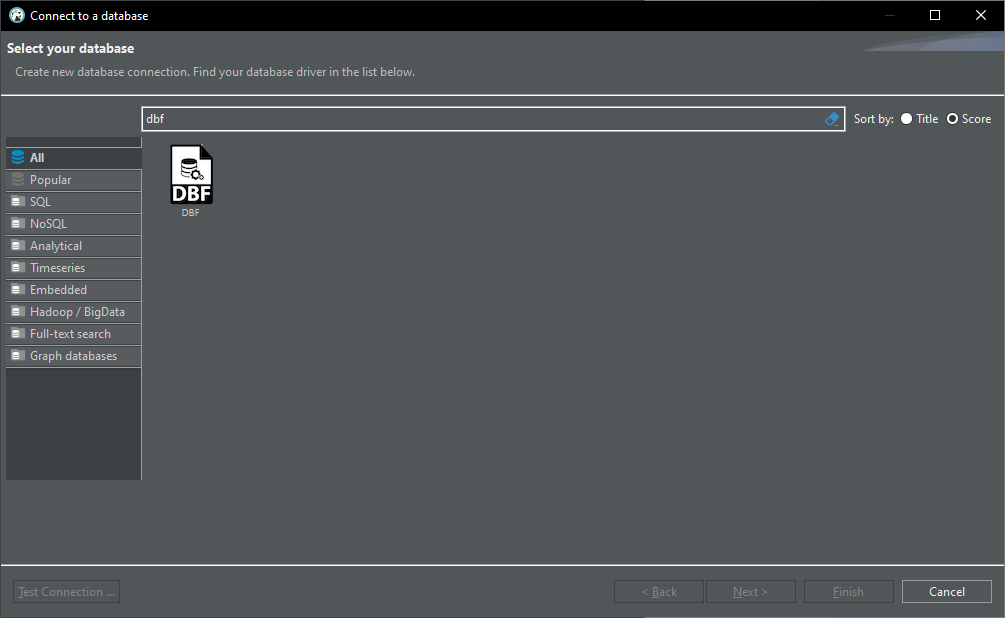
DBF Database auswählen:
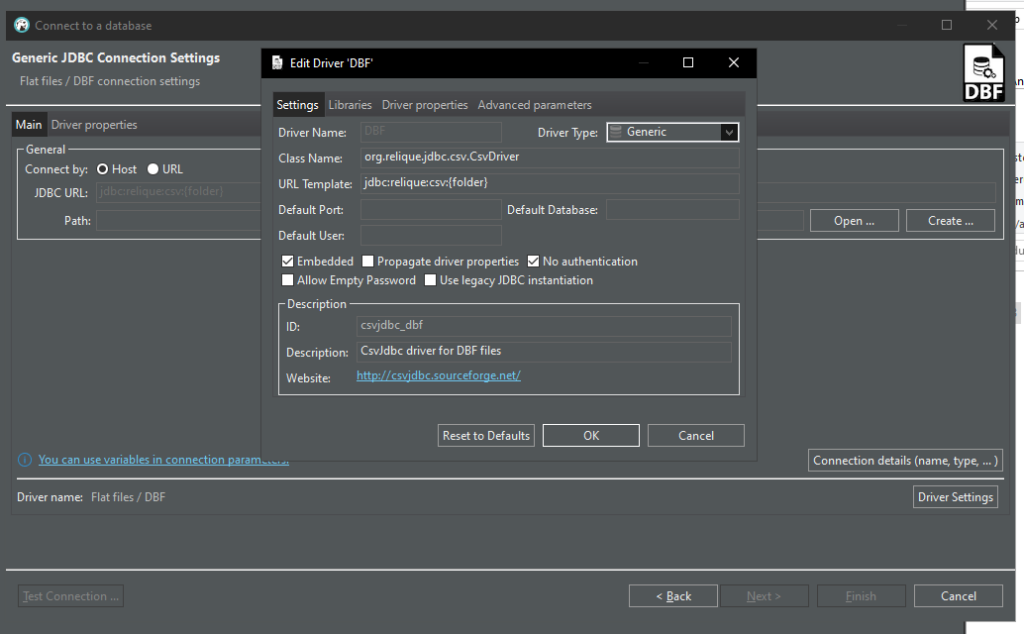
Wenn ich dann aber in die Treiber Details schaue, sieht es nicht so aus, als ob das DANS DBF Driver ist:
Andererseits erscheint das jar dann doch bei den Libraries, also sollte das doch richtig sein?
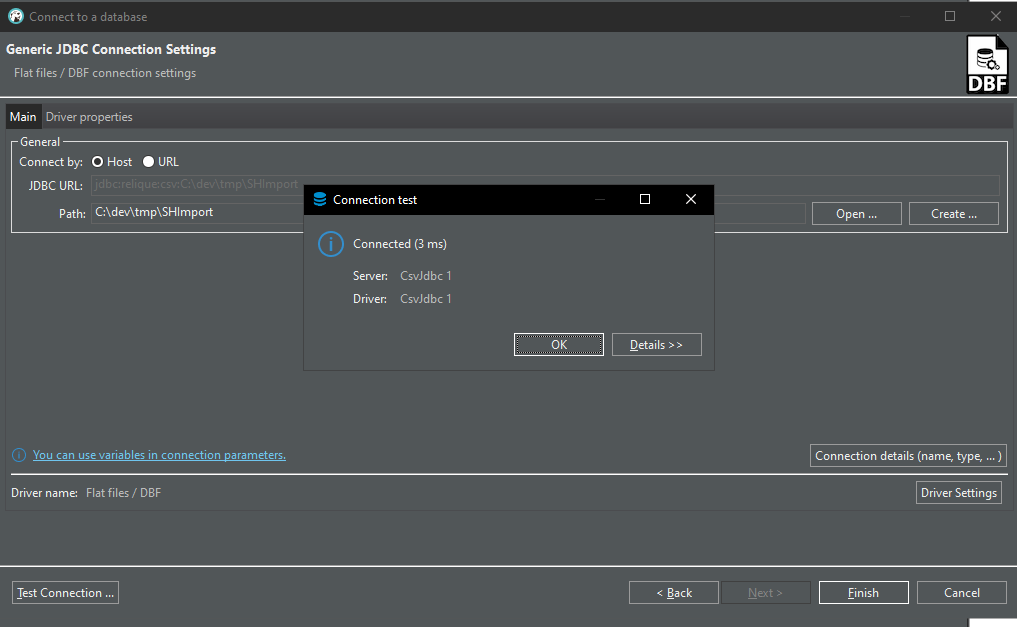
Ich gebe den Pfad zum Ordner mit der .dbf Datei an und rufe Test Connection auf, was sogar funktioniert:
Mit Finish beenden.
Im Database Navigator erscheint die ".dbf Datenbank" und ich kann die enthaltene Tabelle mit ihren Spalten erkennen. Wenn ich dann allerdings View Data auf der Tabelle aufrufe gibt es eine Fehlermeldung:
SQL Error: nl.knaw.dans.common.dbflib.CorruptedTableException: Could not find file 'C:\dev\tmp\SHImport\adress.dbt' (or multiple matches for the file)
Möglicherweise habe ich keinen ordentlichen Export bekommen?
Ich werde dem nachgehen und wenn es noch relevante Informationen zum DBeaver Import geben sollte werde ich diese hier anfügen.
Vor ca. zwei Jahren durfte ich einen Impusvortrag zum Thema Redis halten. Den Inhalt der Folien kopiere ich hierher.
Durch welches Problem bin ich auf Redis gestoßen?
• Migration einer Anwendung von SAP Application Server mit drei Application Server Instanzen auf zwei Apache Tomcat Server • Session Data ging durch Wechsel der Tomcat Server verloren • Lösung: Sticky Session [im LoadBalancer] • Alternative Lösung: Persistieren den Session in der Application Datenbank • • zB in PROJECT_XYZ umgesetzt • • Problem bei der aktuellen Application: DB hat bereits Performanceprobleme • Erweiterte alternative Lösung: • • Speichern der Session Daten in einer eigenen Datenbank • • -> Fragestellung: Gibt es für so ein Scenario spezialisierte Datenbanken?
[Anmerkung aus 2023: Es gibt beim Tomcat ein Clustering/Session Replication Feature, das hatten wir aber aus Gründen nicht in Erwägung gezogen]
Was ist Redis
Der Name Redis steht für Remote Dictionary Server.
In-Memory-Datenbank • Alle Daten werden direkt im Arbeitsspeicher gespeichert • Dadurch sehr kurze Zugriffszeiten • Auch bei großen, unstrukturierten Datenmengen
Key-Value-Store • Hohe Performanz • Dank einfacher Struktur leicht skalierbar • Zu jedem Eintrag wird ein Schlüssel erstellt, über den die Informationen dann wieder aufgerufen werden können.
Redis ist über Module erweiterbar. Mitbewerber der Key-Value-Datenbanken: Amazon DynamoDB
Weitere Optionen • Inkrementelle Vergrößerung oder Verkleinerung • Lebenszeit von Werten setzen • Mit append dem hinterlegten Wert einen weiteren hinzufügen • Einträge mit rename umbenennen
Ich möchte eine lokale Oracle Datenbank mit Docker laufen lassen um so einige Sachen schnell lokal testen zu können. Hintergrund ist eine anstehende Cloud zu Cloud Migration einer bestehenden Anwendung, bei der zugleich die Oracle DB und Java aktualisiert werden wird.
Docker Image
Bei PostgreSQL war das mit der gedockerten Datenbank relativ einfach. Oracle macht es etwas schwieriger. Einfache Images, die man auf dem Docker Hub finden kann, existieren nicht. Statt dessen muss man ein GitHub Repository clonen und ein Shell Script ausführen, um ein Image zu erzeugen und in die lokale Registry zu schieben.
Frei verfügbar sind nur die Versionen Oracle Database 18c XE, 21c XE and 23c FREE. Ich entscheide mich, für die beiden Versionen 21c XE und 23c FREE das Image zu erzeugen und dann zuerst mit Version 23c FREE zu testen und ggf. später weitere Tests mit Version 21c XE machen zu können.
cd
mkdir oracle
cd oracle
git clone https://github.com/oracle/docker-images.git
cd docker-images/OracleDatabase/SingleInstance/dockerfiles/
./buildContainerImage.sh -h
./buildContainerImage.sh -f 23.2.0
# Oracle Database container image for 'free' version 23.2.0 is ready to be extended:
#
# --> oracle/database:23.2.0-free
#
# Build completed in 608 seconds.
./buildContainerImage.sh -x 21.3.0
# Version 23.2.0 does not have Express Edition available.
Die Erzeugung des zweiten Images hat leider nicht funktioniert. Da das erste Image schon so lange gebraucht hat und ich das zweite Image nur proaktiv anlegen wollte, bin ich auch momentan nicht großartig motiviert, dem jetzt weiter nachzugehen. Version 23c FREE reicht erst einmal.
Image direkt von Oracle
Nach dieser Doku kann man das Image auch direkt aus der Oracle Registry ziehen. Zumindest für Oracle Database 23c Free – Developer Release.
Docker Container
Die Dokumentation hat einen speziellen Abschnitt für 23c FREE
Den Abschnitt auf jeden Fall gut ansehen, ich habe den Container mit folgendem Befehl erzeugt:
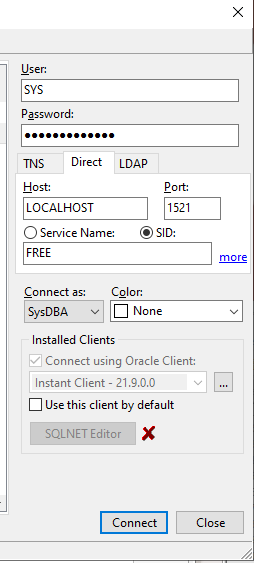
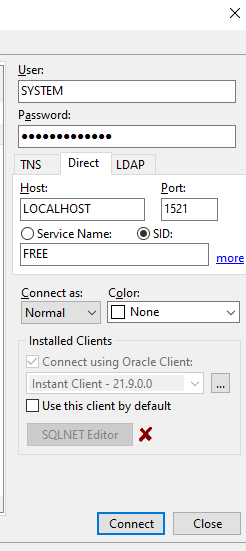
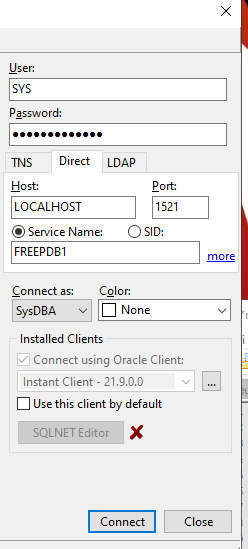
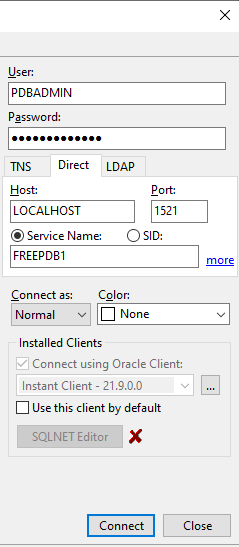
Mit nachfolgenden Einstellungen konnte ich jeweils eine Verbindung aufbauen:
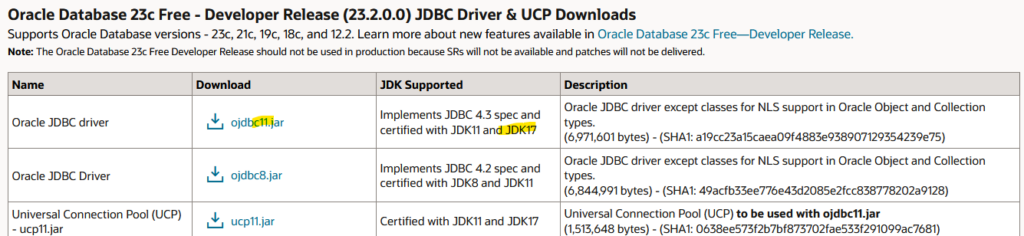
Java
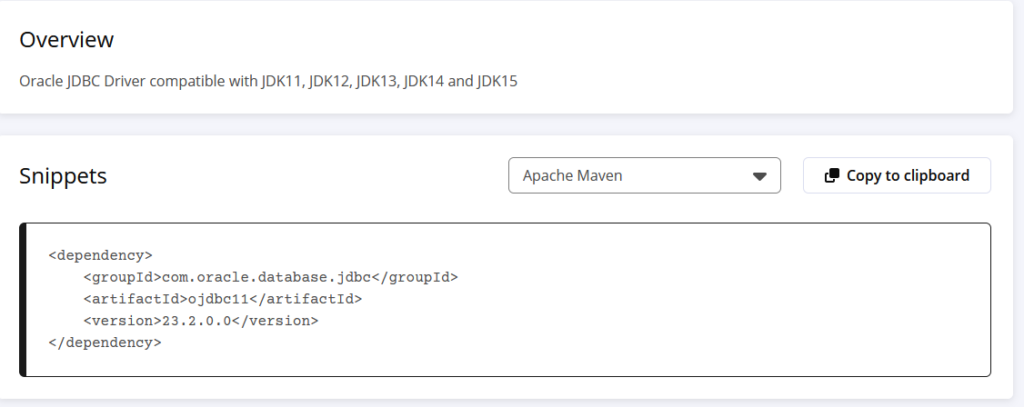
Auf der Seite für JDBC Download von Oracle können wir sehen, das der OJDBC11-Treiber für JDK17 zertifiziert ist:
Anstelle des direkten Downloads kann man auch Maven verwenden, dort wird allerdings Kompatibilität nur bis JDK15 angegeben:
Ich vertraue da mehr der Oracle Seite und werde den Treiber verwenden und das Java Projekt mit JDK17 konfigurieren.
Testprojekt
Die pom.xml des Test Projektes:
4.0.0deringotestproject0.0.1-SNAPSHOTTest ProjectProjekt zum Testen von Sachen17UTF-8com.oracle.database.jdbcojdbc1123.2.0.0org.apache.maven.pluginsmaven-compiler-plugin3.11.0${java.version}${java.version}
Die Test Klasse, basierend auf dem Code-Snippet von Oracle:
package deringo.testproject;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import oracle.jdbc.datasource.impl.OracleDataSource;
public class TestMain {
public static void main(String[] args) throws Exception {
OracleDataSource ods = new OracleDataSource();
ods.setURL("jdbc:oracle:thin:@localhost:1521/FREEPDB1"); // jdbc:oracle:thin@[hostname]:[port]/[DB service name]
ods.setUser("PDBADMIN");
ods.setPassword("ingo5Password");
Connection conn = ods.getConnection();
PreparedStatement stmt = conn.prepareStatement("SELECT 'Hello World!' FROM dual");
ResultSet rslt = stmt.executeQuery();
while (rslt.next()) {
System.out.println(rslt.getString(1));
}
}
}
Nach dem Starten des Programmes lautet die Ausgabe auf der Console dann auch "Hello World!".
Neuer Rechner - neues Glück. Aber auch neu zu installierende Software. Und bei Toad hatte ich ein paar Probleme Herausforderungen, die ich mir bei der nächsten Installation ersparen möchte.
Download
Es fing schon damit an, überhaupt die Installationsdateien für Toad zu bekommen. Zuerst bin ich auf Toadworld gelandet und dort will man mir erstmal eine Subscripton verkaufen, und mir dazu erstmal eine Trial Version zur Verfügung stellen. Möglicherweise kann man die Version mit einer bestehenden Lizenz zur Vollversion aufwerten, vielleicht aber auch nicht. Will man mit diesem Risiko den Alt-Laptop mit funktionierender Datenbank Software abgeben? Nach Murphy's Law kommt dann garantiert ein schweres Datenbank Problem am Tag nach Ablauf des Testzeitraums. Klar, es gibt dann auch anderes Tools, wie zB den Oracle SQL Developer, mit denen man dann zur Not arbeiten könnte. Aber dafür zahlt man ja nicht viel Geld für Professional Edition von Toad.
Ich betreue eine Anwendung, die in eine Oracle DB nutzt, für einen Kunden, der auch die Lizenz für Toad bereit gestellt hat. Ich könnte mich also an den Kunden wenden, der das dann an die interne Stelle für Beschaffung weiter leitet, die dann die Firma für die Lizenzen kontaktiert, die dann Quest kontaktieren können. Ich habe das Thema dann erstmal liegen lassen.
Die Installation kann beginnen. Zum Glück wurde die Subscription immer verlängert, den die Permanent License wurde für Version 10 erworben, aktuell ist 16:
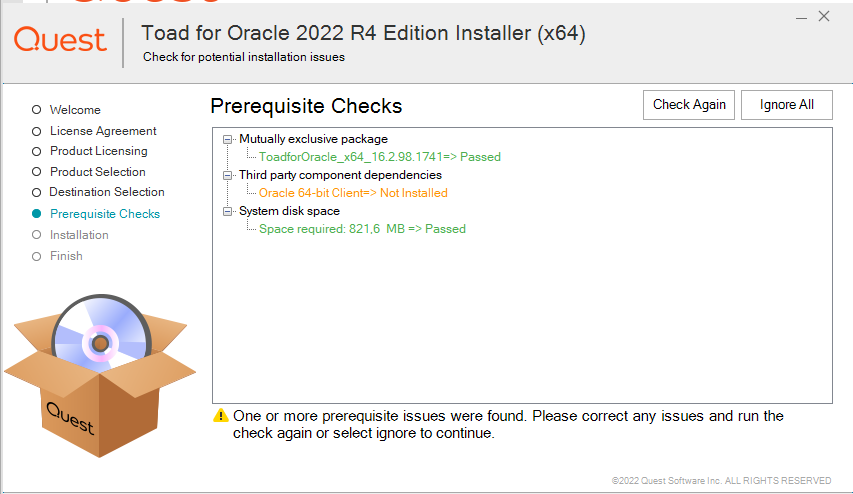
Leider bricht die Installation ab, es wird erst der Oracle Client verlangt:
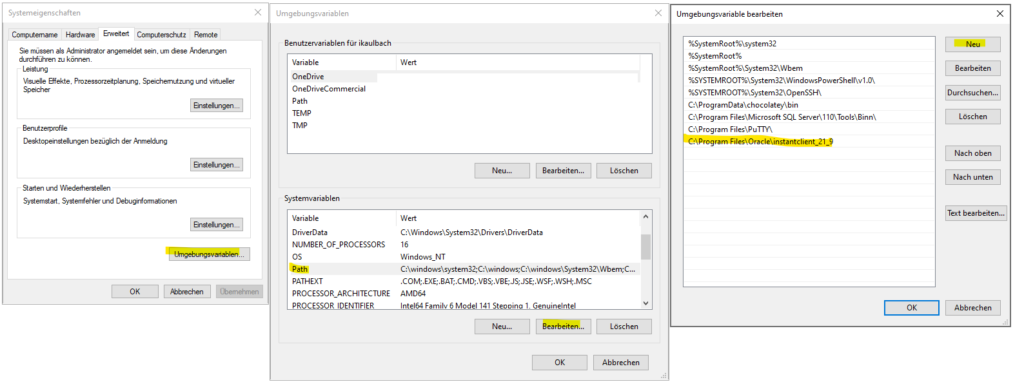
Oracle Instant Client
Zuerst den Oracle Instant Client herunterladen. Ich wähle das Basic Package und zusätzlich die beiden optionalen Packages für SQL*Plus und Tools.
Nach einem Neustart konnte dann Toad installiert werden.
Toad for Oracle Professional 16.2
Hinweis
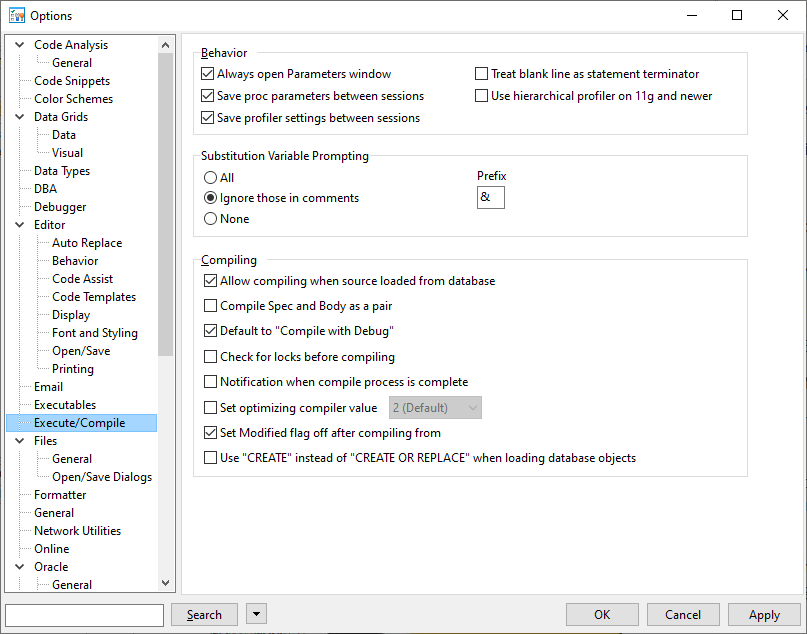
TOAD doesn't like blank lines in SQL statements
Seit der Version 12.9 ist im TOAD standardmäßig die Option aktiviert, dass im Editor neue Zeilen als Befehlsende gelten. Dies empfand ich als sehr störend, da einige Foundation-Templates Leerzeilen enthalten und habe daher die Option deaktiviert: View → Toad Options → Editor → Execute/Compile → Treat blank line as statement terminator
Bisher habe ich für den Datenbankzugriff mit einem proprietärem Framework gearbeitet, das ich jedoch für das aktuelle Projekt nicht verwenden kann. Bei der Wahl einer frei zugänglichen Alternative entschied ich mich für JPA, die Java/Jakarta Persistence API.
Die Datenbank
Als Datenbank benutze ich einfach das Setup aus meinem letzten Post.
Projekt Setup
Es wird ein neues Maven Projekt angelegt. Java Version 1.8.
Es wird die Javax Persistence API benötigt und eine Implementierung, hier: Hibernate. Als DB wird PostgreSQL verwendet, dazu wird der entsprechende Treiber benötigt.
Die pom.xml des Projekts:
4.0.0deringojpa0.0.1-SNAPSHOTJPATestJPA Test Project1.81.8UTF-8UTF-8javax.persistencejavax.persistence-api2.2org.hibernatehibernate-core5.6.1.Finalorg.postgresqlpostgresql42.2.18
Verbindungsbeschreibung
Die benötigten Informationen für den Verbindungsaufbau mit der DB werden in der persistence.xml hinterlegt:
Java Klassen
Die beiden Tabellen Adresse und Person werden jeweils in eine Java Klasse überführt. Dabei handelt es sich um POJOs mit Default Constructor, (generierter) toString, hashCode und equals Methoden. Annotation als Entity und für die ID, die uA objectID heißen soll und nicht wie in der DB object_id.
package deringo.jpa.entity;
import java.io.Serializable;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Adresse implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "object_id")
private int objectID;
private String strasse;
private String ort;
public Adresse() {
// default constructor
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + objectID;
result = prime * result + ((ort == null) ? 0 : ort.hashCode());
result = prime * result + ((strasse == null) ? 0 : strasse.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Adresse other = (Adresse) obj;
if (objectID != other.objectID)
return false;
if (ort == null) {
if (other.ort != null)
return false;
} else if (!ort.equals(other.ort))
return false;
if (strasse == null) {
if (other.strasse != null)
return false;
} else if (!strasse.equals(other.strasse))
return false;
return true;
}
@Override
public String toString() {
return String.format("Adresse [objectID=%s, strasse=%s, ort=%s]", objectID, strasse, ort);
}
public int getObjectID() {
return objectID;
}
public void setObjectID(int objectID) {
this.objectID = objectID;
}
public String getStrasse() {
return strasse;
}
public void setStrasse(String strasse) {
this.strasse = strasse;
}
public String getOrt() {
return ort;
}
public void setOrt(String ort) {
this.ort = ort;
}
}
Für den Zugriff auf die Tabellen werden die jeweiligen Repository Klassen angelegt.
package deringo.jpa.repository;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
import deringo.jpa.entity.Adresse;
public class AdresseRepository {
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("myapp-persistence-unit");
public static Adresse getAdresseById(int id) {
EntityManager em = emf.createEntityManager();
return em.find(Adresse.class, id);
}
}
"Geschäftslogik" um zu testen, ob es funktioniert:
package deringo.jpa;
import deringo.jpa.entity.Adresse;
import deringo.jpa.repository.AdresseRepository;
public class TestMain {
public static void main(String[] args) {
int adresseID = 4;
Adresse adresse = AdresseRepository.getAdresseById(adresseID);
System.out.println(adresse);
}
}
Test Driven
Den Zugriff über die Repositories (und später auch Service Klassen) habe ich Test Driven entwickelt mit JUnit. Zur Entwicklung mit JUnit hatte ich schon mal einen Post verfasst.
Folgende Dependencies wurden der pom.xml hinzugefügt:
public static List getAdresseByOrt(String ort) {
EntityManager em = emf.createEntityManager();
TypedQuery query = em.createQuery("SELECT a FROM Adresse a WHERE a.ort = :ort", Adresse.class);
query.setParameter("ort", ort);
return query.getResultList();
}
Native Query
Um zB herauszufinden, wie die zuletzt vergebene ObjectID lautet, kann ein native Query verwendet werden:
public static int getLastObjectID() {
String sequenceName = "public.object_id_seq";
String sql = "SELECT s.last_value FROM " + sequenceName + " s";
EntityManager em = emf.createEntityManager();
BigInteger value = (BigInteger)em.createNativeQuery(sql).getSingleResult();
return value.intValue();
}
Kreuztabelle
Nehmen wir mal an, eine Person kann mehrere Adressen haben und an eine Adresse können mehrere Personen gemeldet sein.
Um das abzubilden benötigen wir zunächst eine Kreuztabelle, die wir in der DB anlegen:
DROP TABLE IF EXISTS public.adresse_person;
CREATE TABLE public.adresse_person (
adresse_object_id integer NOT NULL,
person_object_id integer NOT NULL
);
Solch eine Relation programmatisch anlegen:
public static void createAdressePersonRelation(int adresseId, int personId) {
String sql = "INSERT INTO adresse_person (adresse_object_id, person_object_id) VALUES (?, ?)";//, adresseId, personId);
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
em.createNativeQuery(sql)
.setParameter(1, adresseId)
.setParameter(2, personId)
.executeUpdate();
em.getTransaction().commit();
}
Die Adresse zu einer Person(enID) lässt sich ermitteln:
Das funktioniert nur, solange die Person nur eine Adresse hat.
Das kann man so machen, schöner ist es aber über entsprechend ausmodellierte ManyToMany Beziehungen in den Entities. Das Beispiel vervollständige ich hier erstmal nicht, da ich bisher es in meinem Projekt nur so wie oben beschrieben benötigte.
OneToMany
Wandeln wir obiges Beispiel mal ab: An einer Adresse können mehrere Personen gemeldet sein, aber eine Person immer nur an einer Adresse.
Wir fügen also der Person eine zusätzliche Spalte für die Adresse hinzu:
ALTER TABLE person ADD COLUMN adresse_object_id integer;
--
UPDATE person SET adresse_object_id = 4
public class Person implements Serializable {
[...]
@ManyToOne
@JoinColumn(name="adresse_object_id")
private Adresse adresse;
[...]
}
public class Adresse implements Serializable {
[..]
@OneToMany
@JoinColumn(name="adresse_object_id")
private List personen = new ArrayList<>();
[...]
}
Anschließend noch die Getter&Setter, toString, hashCode&equals neu generieren und einen Test ausführen:
Es soll das Objekt adresse ausgegeben werden, in welchem in der toString-Methode das Objekt person ausgegeben werden soll, in welchem das Objekt adresse ausgegeben werden, in welchem in der toString-Methode das Objekt person ausgegeben werden soll, in welchem das Objekt adresse ... usw.
Als Lösung muss die toString-Methode von Person händisch angepasst werden, so dass nicht mehr das Objekt adresse, sondern lediglich dessen ID ausgegeben wird:
Man möchte meinen, dass der Code zum löschen einer Adresse wie folgt lautet:
public static void deleteAdresse(Adresse adresse) {
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
em.remove(adresse);
em.getTransaction().commit();
}
Testen:
@Test
public void deleteAdresse() {
int adresseID = 8;
Adresse adresse = AdresseRepository.getAdresseById(adresseID);
assertNotNull(adresse);
AdresseRepository.deleteAdresse(adresse);
assertNull(adresse);
}
Der Test schlägt fehl mit der Nachricht: "Removing a detached instance".
Das Problem besteht darin, dass die Adresse zuerst über einen EntityManager gezogen wird, aber das Löschen in einem anderen EntityManager, bzw. dessen neuer Transaktion, erfolgen soll. Dadurch ist die Entität detached und muss erst wieder hinzugefügt werden, um sie schließlich löschen zu können:
public static void deleteAdresse(Adresse adresse) {
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
em.remove(em.contains(adresse) ? adresse : em.merge(adresse));
em.getTransaction().commit();
}