To analyse an unknown Json API I setup a small project with Smallrye Rest Client to access the Json structure. I added JUnit for a test driven approach and Hamcrest for Matchers (like assertThat or is).
I need an easy way to show some database data of an existing application. The architecture and technic of the application is quite old and unconfortable, so I decided to setup a new project with a modern framework.
I need overview of data in a table, maybe with CSV or PDF file export. A chart to show the number of incoming data per time etc. I want to use a framwork that provides components for this requirements, so I do not have to code much for things like paging, file export etc. I one of my prior projects we used Java Server Faces, and so I came up to give PrimeFaces a try. They have a good ShowCase to show their components.
Unfortunatly it was a little bit more complex to setup the project than I thought at the beginning. No rocket science, but I took me some time for the initial setup, therefore I decided to extract this to a PrimeFaces Template Application to easily reuse it next time and uploaded it to GitHub.
Setup project
Created a new Maven project in Eclipse. Added Eclipse Gitignore defaults from GitHub and target folder (created by Maven) to .gitignore file. Added beans.xml, web.xml and index.xhtml files to project:
CDI
For CDI we need the beans.xml file. Nothing special, it just has to be there:
I want to use Tomcat and not a EE application server like Payara. Therefore I have to add JSF. And I want to use the current version, which is 2.3, so I have to add CDI (JBoss Weld) also.
Since this JSF version, the JSF managed bean facility @ManagedBean is DEPRECATED in in favour of CDI and CDI has become a REQUIRED dependency for JSF 2.3.
Of course PrimeFaces has to be added as dependency, currently in version 8.0 and PrimeFaces Themes.
Flex Grid CSS is a lightweight flex based responsive layout utility optimized for mobile phones, tablets and desktops. Flex Grid CSS is not included in PrimeFaces as it is provided by PrimeFlex, a shared grid library between PrimeFaces, PrimeNG and PrimeReact projects.
Add dependency for Webjar, so we do not need to download and copy the files in our project:
Everyone is talking about and on Twitter. Mostly every Tweet is public and pullable, this makes Twitter a gold mine of data (or a pile of mud, reading some of the Tweets).
I heard, with a Twitter Developer Account you can do a thing or two, so let's try this.
After confirming the email you can create your first Twitter App.
It starts to give it a name
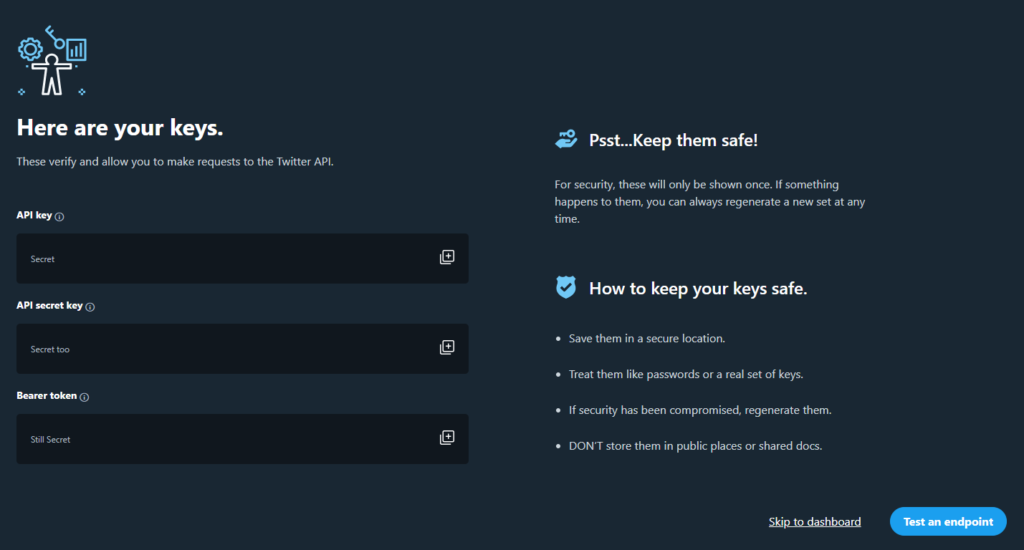
You will be honoured with three secret keys: API key, API secret key and the Bearer token
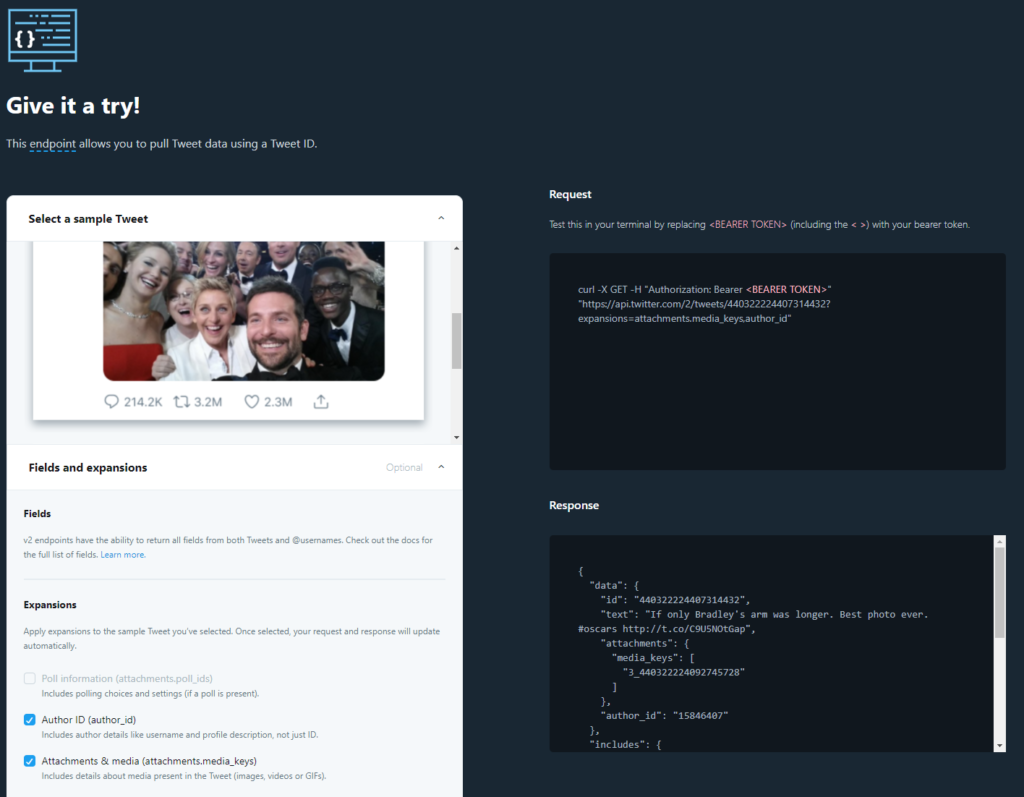
Give it a try! (really, do it)
Next try: type in the curl command in your command line:
curl -X GET -H "Authorization: Bearer <SECRET_BEARER_TOKEN>" "https://api.twitter.com/2/tweets/440322224407314432?expansions=attachments.media_keys,author_id"
{"data":{"text":"If only Bradley's arm was longer. Best photo ever. #oscars http://t.co/C9U5NOtGap","id":"440322224407314432","attachments":{"media_keys":["3_440322224092745728"]},"author_id":"15846407"},"includes":{"media":[{"media_key":"3_440322224092745728","type":"photo"}],"users":[{"id":"15846407","name":"Ellen DeGeneres","username":"TheEllenShow"}]}}
curl -X GET -H "Authorization: Bearer <SECRET_BEARER_TOKEN>" "https://api.twitter.com/2/users/by?usernames=twitterdev,twitterapi,adsapi&user.fields=created_at&expansions=pinned_tweet_id&tweet.fields=author_id,created_at"
{"data":[{"name":"Twitter Dev","pinned_tweet_id":"1293593516040269825","created_at":"2013-12-14T04:35:55.000Z","username":"TwitterDev","id":"2244994945"},{"name":"Twitter API","pinned_tweet_id":"1293595870563381249","created_at":"2007-05-23T06:01:13.000Z","username":"TwitterAPI","id":"6253282"},{"name":"Twitter Ads API","created_at":"2013-02-27T20:01:12.000Z","username":"AdsAPI","id":"1225933934"}],"includes":{"tweets":[{"author_id":"2244994945","id":"1293593516040269825","created_at":"2020-08-12T17:01:42.000Z","text":"It's finally here! \uD83E\uDD41 Say hello to the new #TwitterAPI.\n\nWe're rebuilding the Twitter API v2 from the ground up to better serve our developer community. And today's launch is only the beginning.\n\nhttps://t.co/32VrwpGaJw https://t.co/KaFSbjWUA8"},{"author_id":"6253282","id":"1293595870563381249","created_at":"2020-08-12T17:11:04.000Z","text":"Twitter API v2: Early Access released\n\nToday we announced Early Access to the first endpoints of the new Twitter API!\n\n#TwitterAPI #EarlyAccess #VersionBump https://t.co/g7v3aeIbtQ"}]}}
curl -X GET -H "Authorization: Bearer <SECRET_BEARER_TOKEN>" "https://api.twitter.com/2/tweets?ids=1228393702244134912,1227640996038684673,1199786642791452673&tweet.fields=created_at&expansions=author_id&user.fields=created_at"
{"data":[{"created_at":"2020-02-14T19:00:55.000Z","text":"What did the developer write in their Valentine's card?\n \nwhile(true) {\n I = Love(You); \n}","id":"1228393702244134912","author_id":"2244994945"},{"created_at":"2020-02-12T17:09:56.000Z","text":"Doctors: Googling stuff online does not make you a doctor\n\nDevelopers: https://t.co/mrju5ypPkb","id":"1227640996038684673","author_id":"2244994945"},{"created_at":"2019-11-27T20:26:41.000Z","text":"C#","id":"1199786642791452673","author_id":"2244994945"}],"includes":{"users":[{"id":"2244994945","username":"TwitterDev","name":"Twitter Dev","created_at":"2013-12-14T04:35:55.000Z"}]}}
Making things a little bit more comfortable:
export BEARER_TOKEN=<SECRET_BEARER_TOKEN>
Search for the recently posted Tweets with Hashtag Corona in german language:
curl -X GET -H "Authorization: Bearer $BEARER_TOKEN" "https://api.twitter.com/1.1/search/tweets.json?q=%%23Corona&lang=de&result_type=recent"
A simplified description of a workflow in one of our supported application is:
AnotherServer is sending data through a middleware to MyAppServer. We store the received data in a MS-SQL database an process the data.
Now there is a problem in the AnotherServer system and they did not know, which data they have send to MyAppServer. So they send us a list of data IDs from that day and asked us to check in our application, which data was not received or received but not processed.
The list contains 600 IDs and it would take ~ 1 minute to check a single ID. So this would be work for ~10 hours. And not one single hour would be fun. After a short discussion we decided to do the data analytics directly in the MyApp database.
List of values
First problem is, that they send us an excel file containing the data IDs and we have to transform this in a way, so we can use this IDs in a SQL statement:
SELECT TempTable.Field1
FROM ( VALUES
(10),
(11),
(12)
) AS TempTable (Field1)
Connect list to table
LEFT OUTER JOIN [MyAppSchema].[ReceivedDataTable]
ON TempTable.Field1 = ReceivedDataTable.Data_ID
GROUP BY Field1, Data_ID, is_Processed
ORDER BY is_Processed DESC
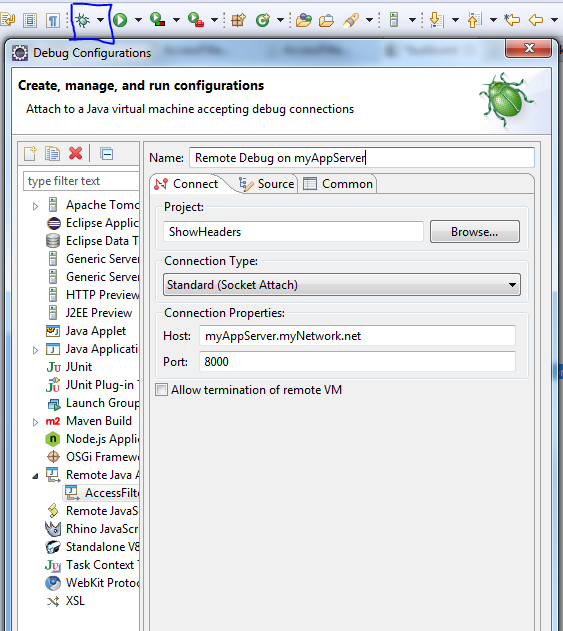
I need to directly debug on the application Tomcat server, not only on my local Tomcat instance.
Compile Java code
For debugging we need to keep the line numbers while compiling. To build the war file we use an ANT script and we have to add the debug and debuglevel attributes in the javac tag:
We have two Linux servers, each with one Tomcat application server. Both application servers must have access to one folder to up- and download files.
We will create a folder on the first server and enable access through the network on this server for the second server.
Operating System: RedHat Enterprise Linux 7
myAppServer1 - Server
vim /etc/exports
systemctl list-units *nfs-server*
# if 0 loaded units, you have to enable and start
systemctl enable nfs-server.service
systemctl start nfs-server.service
systemctl list-units *nfs-server*
exportfs -r
exportfs -s
vim /etc/fstab
vim /etc/auto.master
vim /etc/auto.misc
systemctl enable autofs.service
systemctl start autofs.service
su tomcat
ls -lisah /app/myApp/uploads