When using LM Studio on Windows 11, accessing the server from WSL (Windows Subsystem for Linux) is not straightforward, even though the server is accessible locally. This issue occurs because LM Studio defaults to starting the server on 127.0.0.1 (localhost), which makes it accessible only to applications running directly on the Windows host. Requests from WSL or other hosts (e.g., using the Windows IP address) are blocked.
While LM Studio's interface allows configuring the port, it does not provide an option to modify the network interface (networkInterface) the server listens on.
Solution
To make the server accessible from WSL, the network interface must be changed from 127.0.0.1 to 0.0.0.0, allowing the server to listen on all network interfaces.
Steps to Resolve:
Start LM Studio: Open LM Studio and ensure the server is running as usual.
Edit the Configuration File:
Navigate to the directory containing the internal configuration file:
%userprofile%\.cache\lm-studio\.internal
Open the file http-server-config.json in a text editor.
Modify the Entry:
Locate the "networkInterface" entry and change its value from "127.0.0.1" to "0.0.0.0".
Example:
{
"networkInterface": "0.0.0.0",
"port": 1234
}
Restart LM Studio Server: Stop and restart LM Studio Server in Developer Tab for the changes to take effect.
Test the Access:
Determine the local IP address of the Windows host (e.g., using ipconfig).
Test the server access from WSL with the following command:
curl http://<windows-ip>:1234/v1/models
The server should now be accessible.
Note
Changing the network interface to 0.0.0.0 theoretically makes the server accessible to other devices on the network. If this is not desirable, ensure that the Windows Firewall restricts access to localhost or specific IP ranges.
Conclusion
By modifying the http-server-config.json file, the LM Studio server can be accessed from WSL Linux. This solution is simple and effective for integrating local development environments into hybrid workflows.
Ich möchte einen virtuellen Assistenten erstellen, der auf Informationen von mehreren Webseiten basiert. Ziel ist es, aus den Daten relevante Informationen bereitzustellen und auf Fragen der Benutzer zu antworten.
Da ich keine klaren Informationen über die Struktur der Webseiteninhalte hatte, wollte ich zunächst alle Seiten vollständig speichern und später bereinigen. Die Lösung soll dynamisch erweiterbar sein und folgende Schwerpunkte abdecken:
Web Scraping: Automatisches Sammeln von Rohdaten von verschiedenen Webseiten.
Speicherung: Daten in MongoDB speichern, sowohl Rohdaten als auch bereinigte Daten.
Durchsuchbarkeit: Daten mit einem Full-Text-Index durchsuchbar machen.
KI-Integration: Eine lokale KI-Instanz (Teuken-7B von OpenGPT-X) verwenden, die mit allen 24 europäischen Amtssprachen trainiert wurde, um Benutzerfragen in natürlicher Sprache zu beantworten.
Benutzeroberfläche: Ein Web-Interface für eine einfache und intuitive Nutzung der Lösung.
Lösungsansatz
Web Scraping mit Scrapy:
Automatisches Sammeln von HTML-Rohdaten von mehreren Webseiten.
Dynamisches Einlesen von Start-URLs.
Bereinigung der Daten während des Scrapings (HTML-Tags entfernen, Boilerplate entfernen, Texte kürzen).
Datenhaltung mit MongoDB:
Rohdaten und bereinigte Texte wurden parallel gespeichert, um flexibel zu bleiben.
Full-Text-Index mit deutscher Spracheinstellung eingerichtet, um die bereinigten Texte effizient zu durchsuchen.
KI-Integration mit Teuken-7B:
Übergabe der MongoDB-Ergebnisse als Kontext an das Sprachmodell Teuken-7B.
Das Modell generiert eine präzise Antwort auf die Benutzerfrage, basierend auf den bereitgestellten Daten.
Web-App mit Flask:
Einfache Benutzeroberfläche, um Fragen zu stellen und KI-Antworten anzuzeigen.
Verbindung von Flask mit MongoDB und der KI für dynamische Abfragen.
Architektur
1. Datensammlung
Tool: Scrapy.
Datenquellen: Liste von Start-URLs (mehrere Domains).
Prozess:
Besuch der Startseiten.
Rekursive Erfassung aller Links innerhalb der erlaubten Domains.
Speicherung der Rohdaten (HTML) und bereinigten Daten (Text).
2. Datenhaltung
Datenbank: MongoDB.
Struktur:
{
"url": "https://www.example.com/about",
"raw_html": "...",
"cleaned_text": "This is an example text.",
"timestamp": "2024-11-26T12:00:00Z"
}
Full-Text-Index:
Feld: cleaned_text.
Sprache: Deutsch.
3. Datenanalyse
Abfragen:
MongoDB-Textsuche mit Unterstützung für Wortstämme (z. B. „Dienstleistung“ und „Dienstleistungen“).
Priorisierung der Ergebnisse nach Relevanz (score).
4. KI-Integration
KI-Tool: Teuken-7B (OpenGPT-X).
Prozess:
Übergabe der MongoDB-Ergebnisse als Kontext an die KI.
Generierung einer präzisen Antwort basierend auf der Benutzerfrage.
5. Benutzeroberfläche
Framework: Flask.
Funktionen:
Eingabeformular für Benutzerfragen.
Anzeige der KI-Antwort und der relevanten Daten.
Einfache und intuitive Navigation.
Implementierung
1. Überblick über die Implementierungsschritte
Wir setzen die zuvor beschriebenen Schritte um:
Web Scraping mit Scrapy: Erfassen von Daten von mehreren Webseiten.
Datenhaltung mit MongoDB: Speicherung der Roh- und bereinigten Daten.
Full-Text-Index: Einrichten eines deutschen Index in MongoDB.
KI-Integration mit Teuken-7B: Verarbeitung von Benutzerfragen mit einer lokalen Instanz.
Benutzeroberfläche mit Flask: Web-Interface zur Interaktion mit dem virtuellen Assistenten.
2. Web Scraping: FullSiteSpider
Erstelle einen Scrapy-Spider (spiders/fullsite_spider.py), der mehrere Domains und Seiten crawlt.
import scrapy
from bs4 import BeautifulSoup
class FullSiteSpider(scrapy.Spider):
name = "fullsite"
# Liste der erlaubten Domains und Start-URLs
allowed_domains = ["example.com", "example2.com", "example3.org"]
start_urls = [
"https://www.example.com",
"https://www.example2.com",
"https://www.example3.org/start"
]
def parse(self, response):
# Rohdaten speichern
raw_html = response.body.decode('utf-8')
# Bereinigung der HTML-Daten
cleaned_text = self.clean_html(raw_html)
# Speichern der Daten
yield {
'url': response.url,
'raw_html': raw_html,
'cleaned_text': cleaned_text,
'timestamp': response.headers.get('Date', '').decode('utf-8'),
}
# Folge allen Links auf der Seite
for link in response.css('a::attr(href)').getall():
if link.startswith('http') or link.startswith('/'):
yield response.follow(link, self.parse)
def clean_html(self, html_content):
"""Bereinigt HTML und extrahiert lesbaren Text."""
soup = BeautifulSoup(html_content, 'html.parser')
text = soup.get_text(separator=" ").strip()
return " ".join(text.split())
3. Datenhaltung: MongoDB Pipeline
Speichere die gescrapten Daten direkt in MongoDB.
import pymongo
import json
class MongoPipeline:
def __init__(self):
# Konfiguration aus Datei laden
with open('config.json') as config_file:
config = json.load(config_file)
self.mongo_uri = config['MONGO_URI']
self.mongo_db = config['MONGO_DATABASE']
def open_spider(self, spider):
# Verbindung zur MongoDB herstellen
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
# Verbindung schließen
self.client.close()
def process_item(self, item, spider):
# Daten in MongoDB speichern
collection = self.db[spider.name]
collection.insert_one({
'url': item['url'],
'raw_html': item['raw_html'],
'cleaned_text': item['cleaned_text'],
'timestamp': item['timestamp'],
})
return item
from openai import OpenAI
# Verbindung zur lokalen KI
local_ai = OpenAI(base_url="http://127.0.0.1:1234/v1", api_key="lm-studio")
def generate_response(question, results):
"""
Generiert eine Antwort mit der lokalen KI basierend auf den MongoDB-Ergebnissen.
"""
# Kontext aus den MongoDB-Ergebnissen erstellen
context = "\n".join(
[f"URL: {doc['url']}\nText: {doc['cleaned_text']}" for doc in results]
)
# Nachrichtenformat für die KI
messages = [
{"role": "system", "content": "Du bist ein virtueller Assistent für Firmendaten."},
{"role": "user", "content": f"Hier sind die Daten:\n{context}\n\nFrage: {question}"}
]
# Anfrage an die lokale KI
response = local_ai.chat.completions.create(
model="teuken-7b",
messages=messages,
temperature=0.7
)
return response.choices[0].message.content.strip()
6. Benutzeroberfläche mit Flask
Erstelle die Flask-App (app.py):
from flask import Flask, render_template, request
from pymongo import MongoClient
from ki_helper import generate_response
# Flask-App initialisieren
app = Flask(__name__)
# Verbindung zur MongoDB
client = MongoClient("mongodb://localhost:27017/")
db = client["firmendaten"]
collection = db["fullsite"]
def search_mongodb(question):
"""
Führt eine Volltextsuche in MongoDB aus und gibt relevante Ergebnisse zurück.
"""
results = collection.find(
{"$text": {"$search": question}},
{"score": {"$meta": "textScore"}}
).sort("score", {"$meta": "textScore"}).limit(3)
return list(results)
@app.route('/', methods=['GET', 'POST'])
def index():
if request.method == 'POST':
question = request.form['question']
results = search_mongodb(question)
if not results:
return render_template('result.html', question=question, response="Keine relevanten Daten gefunden.")
response = generate_response(question, results)
return render_template('result.html', question=question, response=response)
return render_template('index.html')
if __name__ == '__main__':
app.run(debug=True)
For my last post about PrivateGPT I need to install Ollama on my machine.
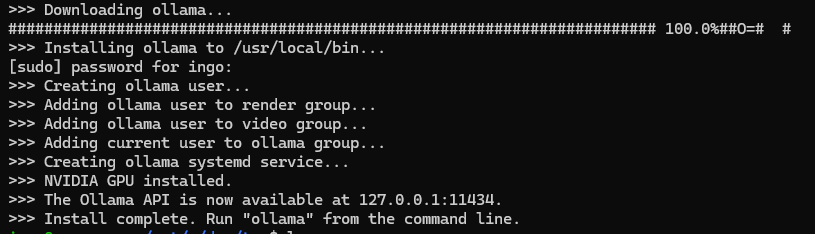
The Ollama page itself is very simple and so is the instruction to install in Linux (WSL):
curl -fsSL https://ollama.com/install.sh | sh
ollama serve
Couldn't find '/home/ingo/.ollama/id_ed25519'. Generating new private key.
Your new public key is:
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIGgHcpiQqs4qOUu1f2tyjs9hfiseDnPfujpFj9nV3RVt
Ollama is bound to localhost:11434. So Ollama is only available from localhost or 127.0.0.1, but not from other IPs, like from inside a docker container.
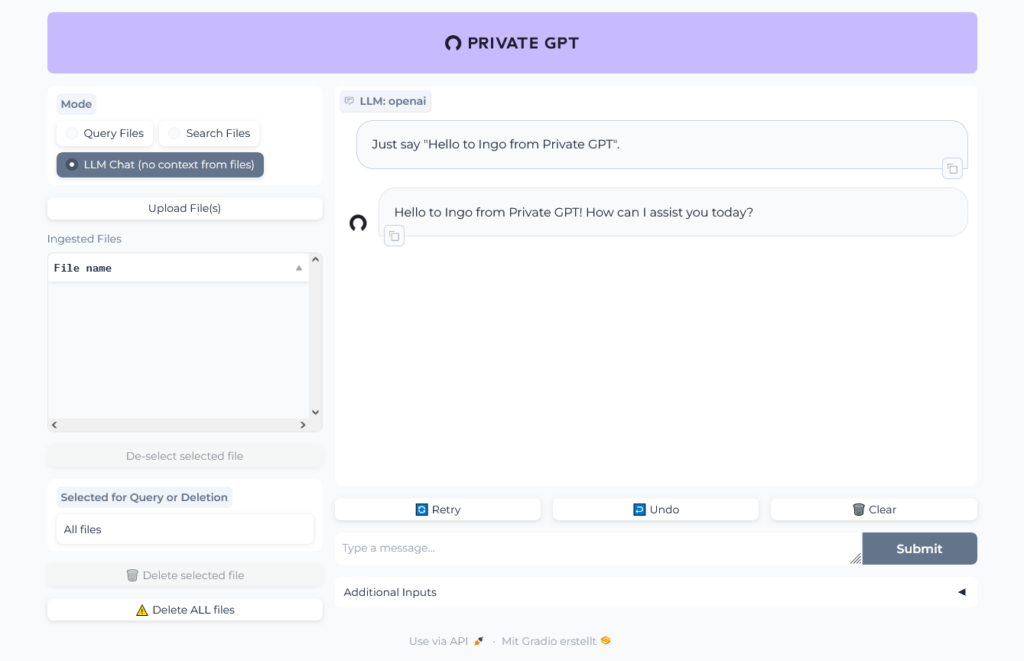
To start with an easier example, I will use PrivateGPT with OpenAI/ChatGPT as AI. Of course therefore the chat will not be private, what is the main reason to use PrivateGPT, but it is a good start to bring things up and running and in a next step add a local AI.
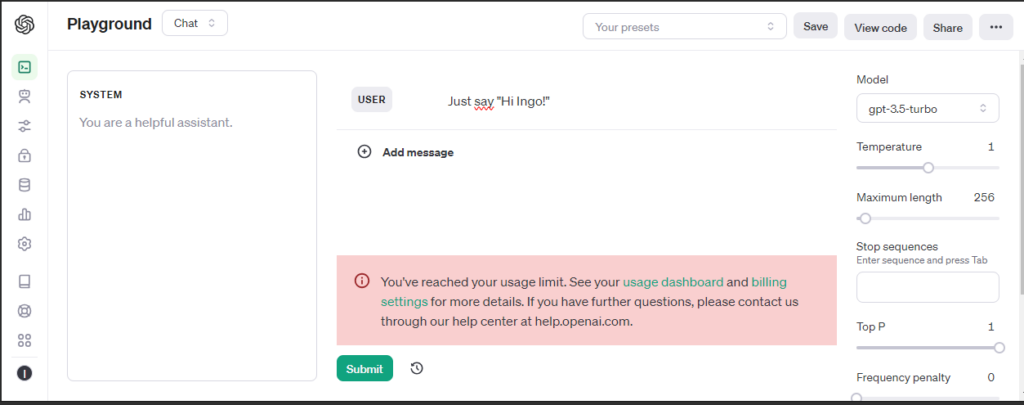
OpenAI API key
To use ChatGPT we need an OpenAI API key. The key itself is free, but I needed to charge my account with 5$ to get it working.
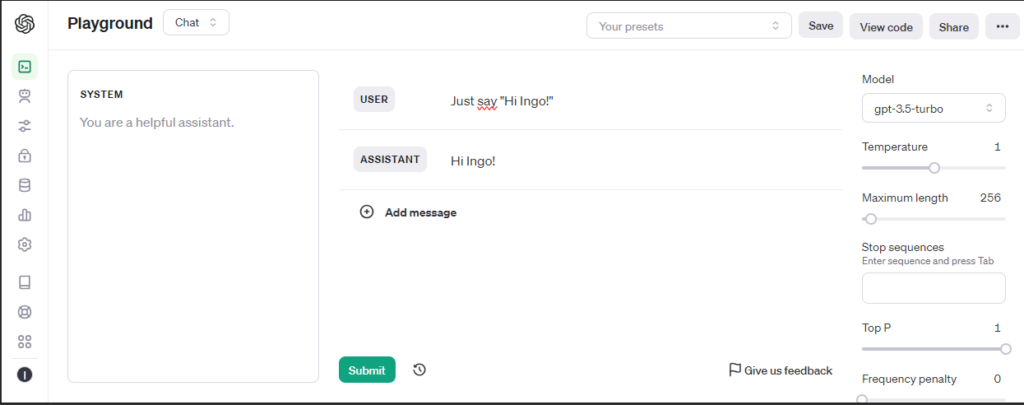
For testing a Playground is available.
Before funding my account:
After funding my account with the minimum of 5$:
Docker
The OpenAI API key is stored in a file .env, that provides its content to docker compose as environment variables.
In docker-compose we set the API key and profile: openai as environment for our Docker container:
In Docker image we configure installation for openai:
RUN poetry install --extras "ui llms-openai vector-stores-qdrant embeddings-openai"
PrivateGPT will download Language Model files during its setup, so we provide a mounted volume for this model files and execute the setup at the start of the container and not at image build:
volumes:
- ../models/cache:/app/privateGPT/models/cache
command: /bin/bash -c "poetry run python scripts/setup && make run"
Here are the complete files, you can also find them on my GitHub:
# Use the specified Python base image
FROM python:3.11-slim
# Set the working directory in the container
WORKDIR /app
# Install necessary packages
RUN apt-get update && apt-get install -y \
git \
build-essential
# Clone the private repository
RUN git clone https://github.com/imartinez/privateGPT
WORKDIR /app/privateGPT
# Install poetry
RUN pip install poetry
# Lock and install dependencies using poetry
RUN poetry lock
RUN poetry install --extras "ui llms-openai vector-stores-qdrant embeddings-openai"
Open http://localhost:8001 in your browser to open Private GPT and run a simple test:
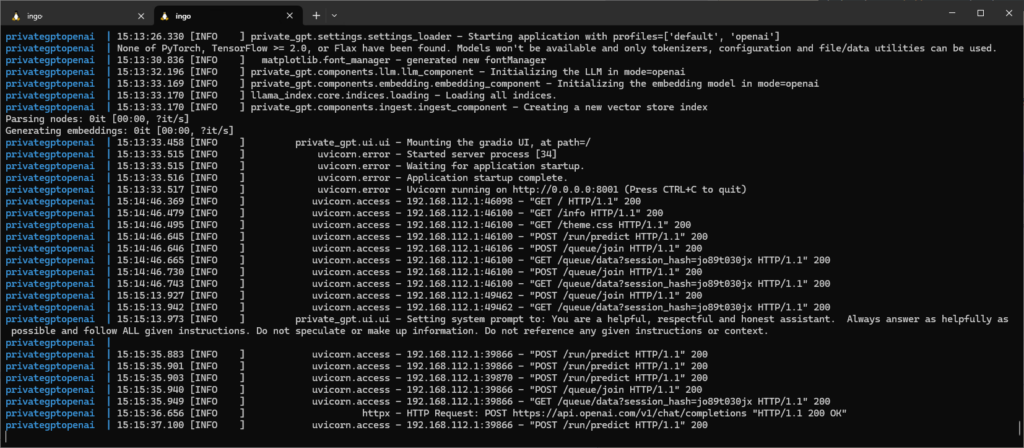
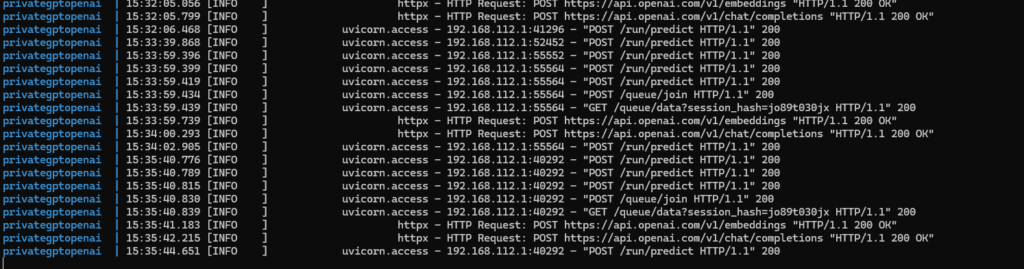
Have a look at the logs to see that there is communication with OpenAI servers:
Chat with document
To "chat" with a document we first need a public available one, because right now we are using ChatGPT where we must not upload internal project documents.
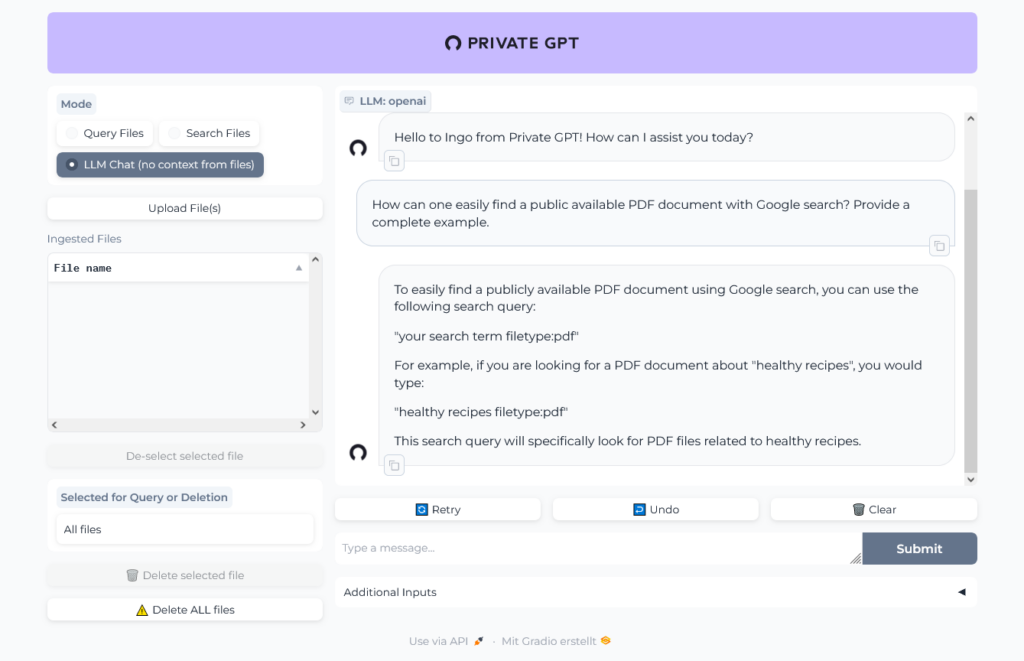
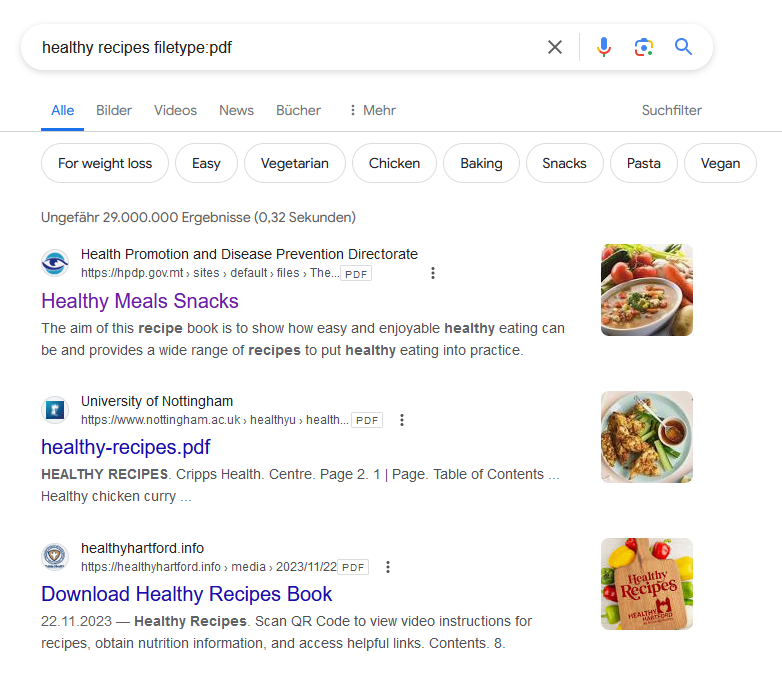
So first ask PrivateGPT/ChatGPT to help us to find a document:
Working fine, we could easily find and download a PDF:
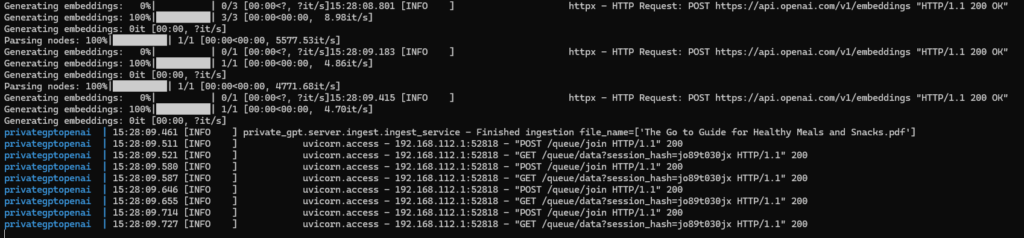
The upload of the PDF (The Go to Guide for Healthy Meals and Snacks.pdf) with 160 pages in 24 MB into PrivateGPT took nearly two minutes. In the logs we can see, that the file was uploaded to ChatGPT:
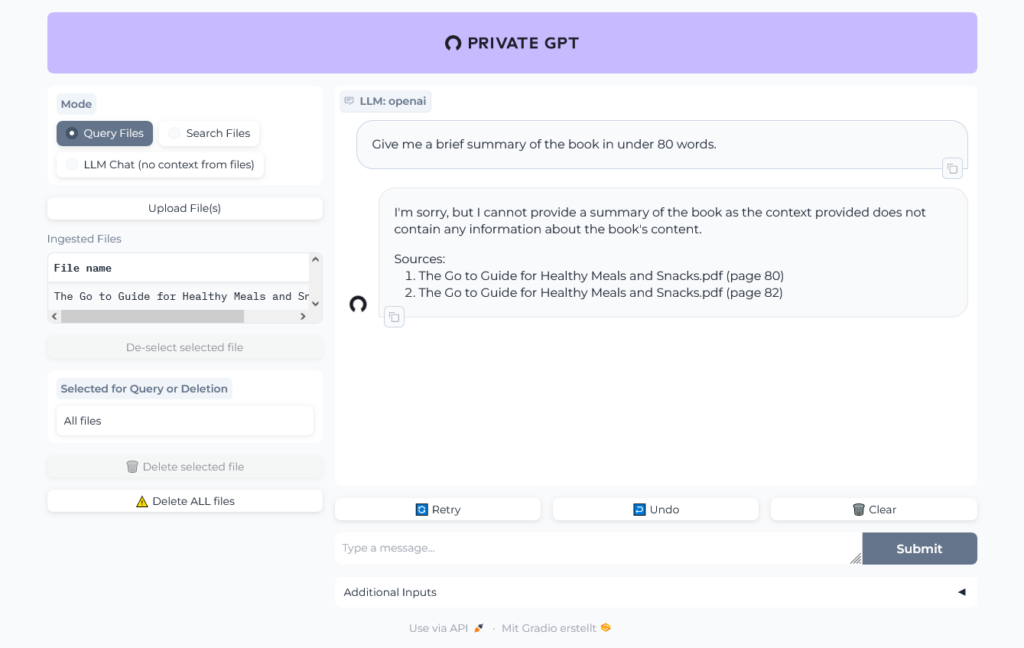
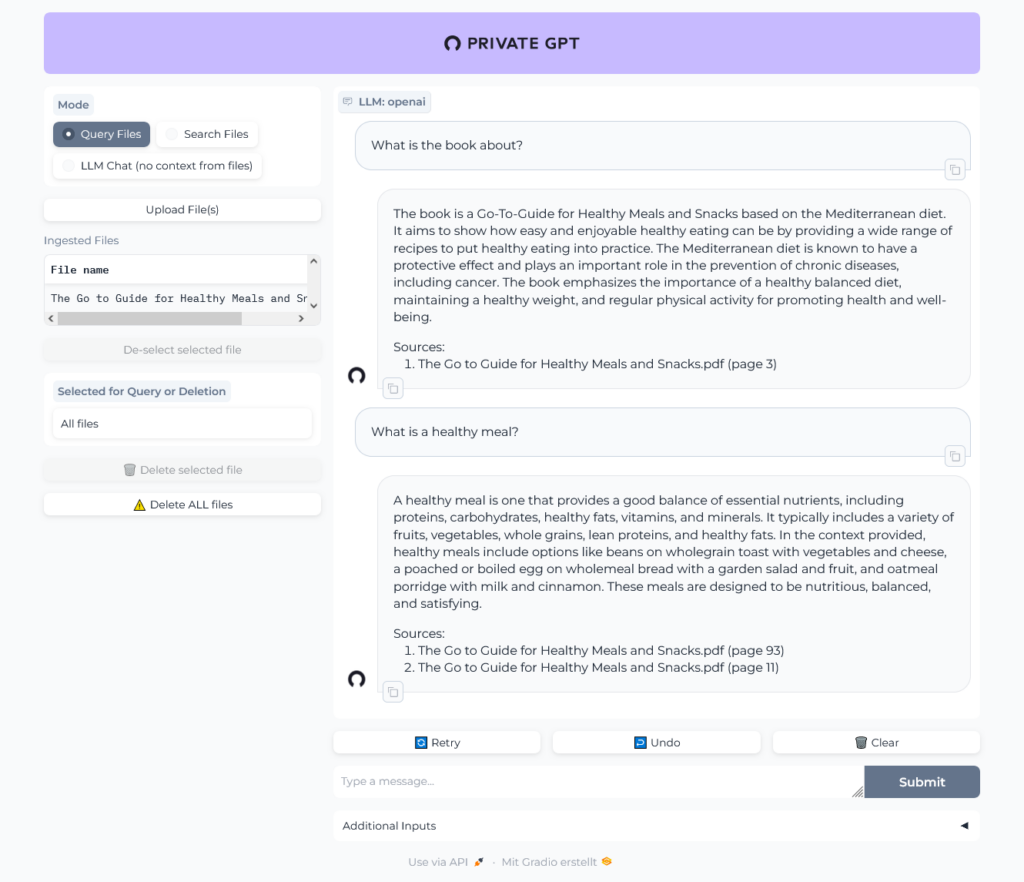
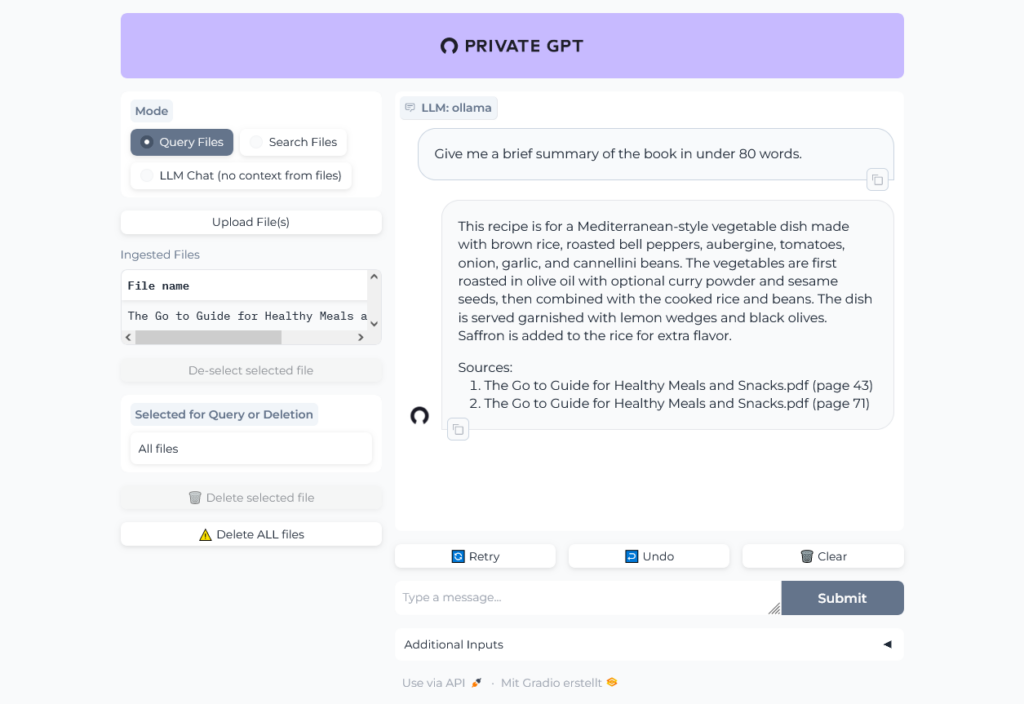
Let's chat with the book:
Uh, was that question too hard? Give it another try:
OK, sounds better. In the logs we can see the traffic to OpenAI:
Local, Ollama-powered setup
Now we want to go private, baby.
Copy configuration to a new folder, can be found in GitHub.
In docker-compose we change the profile to ollama:
environment:
- PGPT_PROFILES=ollama
In Docker image we configure installation for ollama:
RUN poetry install --extras "ui llms-ollama embeddings-ollama vector-stores-qdrant"
As before we can build the image, start the container and watch the logs:
I did not use the large ~24MB file I tried with ChatGPT, but a much smaller one ~297 KB I randomly found in the internet. It is written in german, but it seems, like Ollama understands german.
Well, then I tried the 24 MB file and ... it worked pretty well, the result of the first question was even better than the result from ChatGPT!