Im vorletzten Post: PostgreSQL hatte ich beschrieben, wie ich zwei Bestandsdatenbanken analysiert und in eine PostgreSQL-DB in einem Docker Container gebracht habe, samt PGAdmin.
Jetzt möchte ich einen Schritt weiter gehen und das komplette Setup über ein Script starten können: DB, PGAdmin & SQL-Scripte. Dazu verwende ich Docker-Compose.
Ausgangslage
In PostgreSQL hatte ich bereits die zugrundeliegenden Docker-Images ermittelt: postgres:13.4-buster für die DB und dpage/pgadmin4 für PGAdmin. Inzwischen gibt es aber ein aktuelleres Image für die DB, das ich verwenden werde: postgres:13.5-bullseye
docker pull postgres:13.5-bullseye docker pull dpage/pgadmin4
Für die SQL-Daten werde ich auf den Artikel PostgreSQL IDs zurückgreifen und daraus zwei Scripte machen, eines für das Schema der DB und eines mit den "Masterdaten" mit denen das Schema initial befüllt werden soll.
CREATE SEQUENCE object_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
CREATE TABLE person (
object_id integer NOT NULL DEFAULT nextval('object_id_seq'::regclass),
vorname varchar(255),
nachname varchar(255),
CONSTRAINT person_pkey PRIMARY KEY (object_id)
);
CREATE TABLE adresse (
object_id integer NOT NULL DEFAULT nextval('object_id_seq'::regclass),
strasse varchar(255),
ort varchar(255),
CONSTRAINT adresse_pkey PRIMARY KEY (object_id)
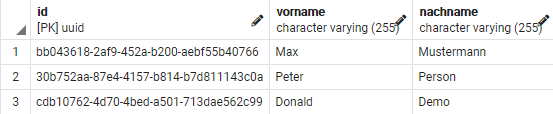
);INSERT INTO person (vorname, nachname) VALUES ('Max', 'Mustermann');
INSERT INTO person (vorname, nachname) VALUES ('Peter', 'Person');
INSERT INTO person (vorname, nachname) VALUES ('Donald', 'Demo');
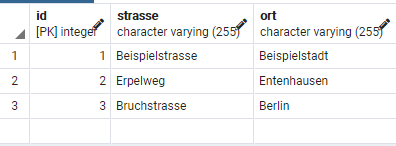
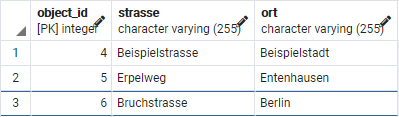
INSERT INTO adresse (strasse, ort) VALUES ('Beispielstrasse', 'Beispielstadt');
INSERT INTO adresse (strasse, ort) VALUES ('Erpelweg', 'Entenhausen');
INSERT INTO adresse (strasse, ort) VALUES ('Bruchstrasse', 'Berlin');Auf der Seite von Docker Compose bringe ich in Erfahrung, dass die aktuelle Version von Docker Compose 3.9 ist und erstelle schon mal die Datei:
version: "3.9" # optional since v1.27.0
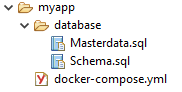
Ordernstrucktur:
Images starten
Bisher habe ich PostgreSQL und PGAdmin über folgende Kommandos gestartet:
docker run --name myapp-db -p 5432:5432 -e POSTGRES_PASSWORD=PASSWORD -d postgres:13.4-buster
docker run --name myapp-pgadmin -p 80:80 -e PGADMIN_DEFAULT_EMAIL=admin@admin.com -e PGADMIN_DEFAULT_PASSWORD=admin -d dpage/pgadmin4
Diese Kommandos werden in ein Docker-Compose Script transferiert:
version: "3.9" # optional since v1.27.0
services:
myapp-db:
image: postgres:13.5-bullseye
ports:
- "5432:5432"
environment:
- POSTGRES_PASSWORD=PASSWORD
myapp-pgadmin:
image: dpage/pgadmin4
ports:
- "80:80"
environment:
- PGADMIN_DEFAULT_EMAIL=admin@admin.com
- PGADMIN_DEFAULT_PASSWORD=adminJetzt können beide Images mit einem einfachen Befehl gestartet werden:
\myapp> docker-compose up Creating network "myapp_default" with the default driver Creating myapp_myapp-db_1 ... done Creating myapp_myapp-pgadmin_1 ... done Attaching to myapp_myapp-db_1, myapp_myapp-pgadmin_1
PGAdmin im Browser starten: http://localhost:80
Login wie bisher mit admin@admin.com / admin
Im nächsten Schritt gibt es bereits eine entscheidende Änderung:
Während bisher beide Container isoliert nebeneinander liefen und nur über den Host-Rechner kommunizieren konnten, wurde durch Docker-Compose automatisch beim Start ein Netzwerk ("myapp_default") angelegt, in dem beide Container laufen. Außerdem sind beide Container über ihren Servicenamen ("myapp-db" & "myapp-pgadmin") erreichbar.
Dadurch muss nicht mehr die IP des Host-Rechners ermittelt werden (die sich manchmal ändert), sondern es kann der Name genommen werden:
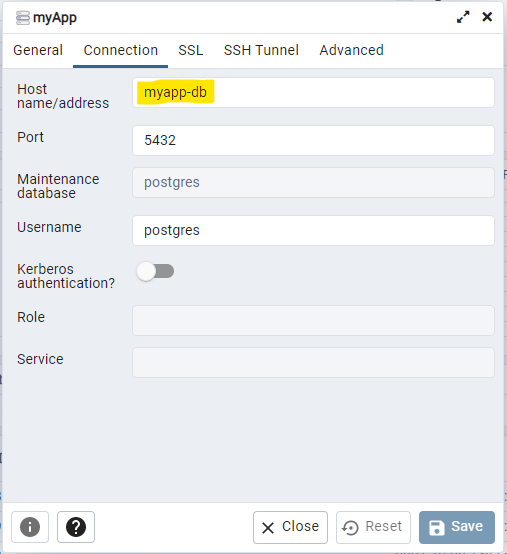
Datenbank erstellen
In der PostgreSQL Instanz muss jetzt eine Datenbank erzeugt werden, in der die Anwendungsdaten gespeichert werden.
Hierzu gehen wir in den DB Container.
Allerdings ist der Name anders als bisher: Es wurde der Verzeichnisname als Präfix davor und eine 1 (für die 1. und in unserem Fall einzige Instanz) als Postfix dahinter gehangen und so lautet der Name : myapp_myapp-db_1
docker exec -it myapp_myapp-db_1 bash
Im Container erzeugen wir die DB:
su postgres createdb myappdb exit
So war es zumindest bisher, einfacher geht es mit Docker-Compose und dem Setzten der Environment-Variablen POSTGRES_DB wodurch die DB automatisch angelegt und verwendet wird.
Sicherlich hätte ich das auch bisher im Docker Kommando so nehmen können, aber im letzten Post hatte ich es zum einen mit zwei DBs zu tun und zum anderen musste ich eh auf die Kommandozeile um die DBs einzuspielen.
version: "3.9"
services:
myapp-db:
image: postgres:13.5-bullseye
ports:
- "5432:5432"
environment:
- POSTGRES_PASSWORD=PASSWORD
- POSTGRES_DB=myappdb
myapp-pgadmin:
image: dpage/pgadmin4
ports:
- "80:80"
environment:
- PGADMIN_DEFAULT_EMAIL=admin@admin.com
- PGADMIN_DEFAULT_PASSWORD=adminDatenbank befüllen
Bisher war der Weg, die SQL-Dateien in den Container zu kopieren und von dort einzuspielen:
# Dateien in Container kopieren docker cp database/Masterdata.sql myapp_myapp-db_1:/tmp docker cp database/Schema.sql myapp_myapp-db_1:/tmp # In Container wechseln docker exec -it myapp_myapp-db_1 bash
Im Container SQLs einspielen:
su postgres psql myappdb < /tmp/Schema.sql psql myappdb < /tmp/Masterdata.sql exit
Einfacher geht es über Docker-Compose und den Mechanismus, dass PostgreSQL automatisch die Dateien importiert, die im Verzeichnis /docker-entrypoint-initdb.d/ liegen. Und zwar in alphabetischer Reihenfolge.
version: "3.9"
services:
myapp-db:
image: postgres:13.5-bullseye
ports:
- "5432:5432"
environment:
- POSTGRES_PASSWORD=PASSWORD
- POSTGRES_DB=myappdb
volumes:
- ./database/Schema.sql:/docker-entrypoint-initdb.d/1-Schema.sql
- ./database/Masterdata.sql:/docker-entrypoint-initdb.d/2-Masterdata.sql
myapp-pgadmin:
image: dpage/pgadmin4
ports:
- "80:80"
environment:
- PGADMIN_DEFAULT_EMAIL=admin@admin.com
- PGADMIN_DEFAULT_PASSWORD=adminPGAdmin Einstellungen persistieren
Während der Entwicklung öfters mal die DB platt macht und komplett neu aufsetzt: Mit Docker ist das schnell gemacht. Mit Docker-Compose sind es jetzt nur noch zwei Befehle:
# stop and remove stopped containers docker-compose down # start containers docker-compose up
Einen Nachteil gibt es allerdings: Die Einstellungen im PGAdmin gehen ebenfalls flöten und müssen neu eingegeben werden.
Die Lösung: Der PGAdmin Container bekommt ein persistentes Volume, das ein docker-compose down übersteht. Und wenn es doch mal neu aufgesetzt werden muss, ist das einfach über das -v Flag umsetzbar: docker-compose down -v
version: "3.9"
services:
myapp-db:
image: postgres:13.5-bullseye
ports:
- "5432:5432"
environment:
- POSTGRES_PASSWORD=PASSWORD
- POSTGRES_DB=myappdb
volumes:
- ./database/Schema.sql:/docker-entrypoint-initdb.d/1-Schema.sql
- ./database/Masterdata.sql:/docker-entrypoint-initdb.d/2-Masterdata.sql
myapp-pgadmin:
image: dpage/pgadmin4
ports:
- "80:80"
environment:
- PGADMIN_DEFAULT_EMAIL=admin@admin.com
- PGADMIN_DEFAULT_PASSWORD=admin
volumes:
- pgadminvolume:/var/lib/pgadmin
volumes:
pgadminvolume: {}DB Image mit Schema und Masterdata
An Schema und Stammdaten wird sich erstmal nichts ändern. Daher wäre es gut, wenn beim Neubau der Container die DB bereits mit Schema und Stammdaten gestartet wird und nicht diese erst aufbauen muss.
Das wird dadurch erreicht, dass ein Image gebaut wird, dass die PostgreSQL DB sowie Schema und Stammdaten enthält.
Im Verzeichnis database wird eine Datei Dockerfile angelegt. Dieses Dockerfile enthält die Informationen zum Bau des DB Images.
FROM postgres:13.5-bullseye ENV POSTGRES_PASSWORD PASSWORD ENV POSTGRES_DB myappdb COPY ./Schema.sql /docker-entrypoint-initdb.d/1-Schema.sql COPY ./Masterdata.sql /docker-entrypoint-initdb.d/2-Masterdata.sql
version: "3.9"
services:
myapp-db:
build: ./database
ports:
- "5432:5432"
myapp-pgadmin:
image: dpage/pgadmin4
ports:
- "80:80"
environment:
- PGADMIN_DEFAULT_EMAIL=admin@admin.com
- PGADMIN_DEFAULT_PASSWORD=admin
volumes:
- pgadminvolume:/var/lib/pgadmin
volumes:
pgadminvolume: {}Gestartet wird wie gewohnt:
docker-compose up
Sollte es erforderlich sein, das Image neu zu bauen, zB wenn ich das Schema verändert hat:
docker-compose up --build # or docker-compose build
UPDATE: Das war leider nix mit dem vorgefüllten Image
Das Dockerfile enthält zwar den Schritt die SQL Dateien in das Image zu kopieren. Es fehlt aber der Schritt, bei dem diese Dateien in die Datenbank hineinmigriert werden. Das geschieht wie zuvor auch erst beim Starten des Containers. Mein Ziel, einen Image zu haben, dass diese Daten bereits enthält, habe ich damit also leider nicht erreicht. Das Dockerfile enthält keine Informationen, die nicht zuvor auch schon im Docker Compose enthalten waren.
Da mich das herumkaspern mit diesem Problem heute den ganzen Tag gekostet und abgesehen vom Erkenntnisgewinn leider nichts gebracht hat, kehre ich zur Docker Compose Variante zurück, bei der die DB beim Starten des Containers gebaut wird. Für das Beispiel auf dieser Seite macht das praktisch gesehen keinen Unterschied, da die Scripte winzig sind. Für mein Projekt leider schon, da benötigt der Aufbau der DB ein paar Minuten. Für die Anwendungsentwicklung, bei der ich die DB alle paar Tage mal neu aufsetze, ist das durchaus OK. Für Tests, die mit einer frischen DB starten sollen, die am Ende weggeschmissen wird, ist das schon ein Problem.
Also Rückkehr zu Docker Compose, diesmal mit einem extra Volume für die DB. Das kann ich dann gezielt löschen.
version: "3.9"
services:
myapp-db:
image: postgres:13.5-bullseye
ports:
- "5432:5432"
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=PASSWORD
- POSTGRES_DB=myapp
volumes:
- postgresvolume:/var/lib/postgresql/data
- ./database/Schema.sql:/docker-entrypoint-initdb.d/1-Schema.sql
- ./database/Masterdata.sql:/docker-entrypoint-initdb.d/2-Masterdata.sql
myapp-pgadmin:
image: dpage/pgadmin4
ports:
- "80:80"
environment:
- PGADMIN_DEFAULT_EMAIL=admin@admin.com
- PGADMIN_DEFAULT_PASSWORD=admin
volumes:
- pgadminvolume:/var/lib/pgadmin
volumes:
postgresvolume: {}
pgadminvolume: {}Docker Befehle
# Create and start containers docker-compose up # Image neu bauen docker-compose up --build # or docker-compose build # Stop containers docker-compose stop # Start containers docker-compose start # Stop containers and remove them docker-compose down # Stop containers, remove them and remove volumes docker-compose down -v