Bisher habe ich für den Datenbankzugriff mit einem proprietärem Framework gearbeitet, das ich jedoch für das aktuelle Projekt nicht verwenden kann. Bei der Wahl einer frei zugänglichen Alternative entschied ich mich für JPA, die Java/Jakarta Persistence API.
Die Datenbank
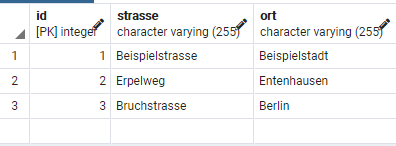
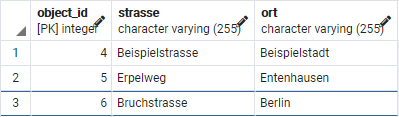
Als Datenbank benutze ich einfach das Setup aus meinem letzten Post.
Projekt Setup
Es wird ein neues Maven Projekt angelegt. Java Version 1.8.
Es wird die Javax Persistence API benötigt und eine Implementierung, hier: Hibernate. Als DB wird PostgreSQL verwendet, dazu wird der entsprechende Treiber benötigt.
Die pom.xml des Projekts:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>deringo</groupId>
<artifactId>jpa</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>JPATest</name>
<description>JPA Test Project</description>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<dependency>
<groupId>javax.persistence</groupId>
<artifactId>javax.persistence-api</artifactId>
<version>2.2</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.6.1.Final</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.postgresql/postgresql -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.2.18</version>
</dependency>
</dependencies>
</project>Verbindungsbeschreibung
Die benötigten Informationen für den Verbindungsaufbau mit der DB werden in der persistence.xml hinterlegt:
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd"
version="2.2">
<persistence-unit name="myapp-persistence-unit">
<properties>
<!-- Configure a database connection in Java SE -->
<property name="javax.persistence.jdbc.driver" value="org.postgresql.Driver" />
<property name="javax.persistence.jdbc.url" value="jdbc:postgresql://127.0.0.1:5432/myapp" />
<property name="javax.persistence.jdbc.user" value="postgres" />
<property name="javax.persistence.jdbc.password" value="PASSWORD" />
<!-- Configure timeouts -->
<property name="javax.persistence.lock.timeout" value="100"/>
<property name="javax.persistence.query.timeout" value="100"/>
</properties>
</persistence-unit>
</persistence>Java Klassen
Die beiden Tabellen Adresse und Person werden jeweils in eine Java Klasse überführt. Dabei handelt es sich um POJOs mit Default Constructor, (generierter) toString, hashCode und equals Methoden. Annotation als Entity und für die ID, die uA objectID heißen soll und nicht wie in der DB object_id.
package deringo.jpa.entity;
import java.io.Serializable;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Adresse implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "object_id")
private int objectID;
private String strasse;
private String ort;
public Adresse() {
// default constructor
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + objectID;
result = prime * result + ((ort == null) ? 0 : ort.hashCode());
result = prime * result + ((strasse == null) ? 0 : strasse.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Adresse other = (Adresse) obj;
if (objectID != other.objectID)
return false;
if (ort == null) {
if (other.ort != null)
return false;
} else if (!ort.equals(other.ort))
return false;
if (strasse == null) {
if (other.strasse != null)
return false;
} else if (!strasse.equals(other.strasse))
return false;
return true;
}
@Override
public String toString() {
return String.format("Adresse [objectID=%s, strasse=%s, ort=%s]", objectID, strasse, ort);
}
public int getObjectID() {
return objectID;
}
public void setObjectID(int objectID) {
this.objectID = objectID;
}
public String getStrasse() {
return strasse;
}
public void setStrasse(String strasse) {
this.strasse = strasse;
}
public String getOrt() {
return ort;
}
public void setOrt(String ort) {
this.ort = ort;
}
}Für den Zugriff auf die Tabellen werden die jeweiligen Repository Klassen angelegt.
package deringo.jpa.repository;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
import deringo.jpa.entity.Adresse;
public class AdresseRepository {
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("myapp-persistence-unit");
public static Adresse getAdresseById(int id) {
EntityManager em = emf.createEntityManager();
return em.find(Adresse.class, id);
}
}"Geschäftslogik" um zu testen, ob es funktioniert:
package deringo.jpa;
import deringo.jpa.entity.Adresse;
import deringo.jpa.repository.AdresseRepository;
public class TestMain {
public static void main(String[] args) {
int adresseID = 4;
Adresse adresse = AdresseRepository.getAdresseById(adresseID);
System.out.println(adresse);
}
}Test Driven
Den Zugriff über die Repositories (und später auch Service Klassen) habe ich Test Driven entwickelt mit JUnit. Zur Entwicklung mit JUnit hatte ich schon mal einen Post verfasst.
Folgende Dependencies wurden der pom.xml hinzugefügt:
<!-- https://mvnrepository.com/artifact/org.junit.jupiter/junit-jupiter-api -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.8.1</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.hamcrest/hamcrest -->
<dependency>
<groupId>org.hamcrest</groupId>
<artifactId>hamcrest</artifactId>
<version>2.2</version>
<scope>test</scope>
</dependency>
package deringo.jpa.repository;
import static org.hamcrest.MatcherAssert.assertThat;
import static org.hamcrest.Matchers.is;
import static org.junit.jupiter.api.Assertions.assertNotNull;
import static org.junit.jupiter.api.Assertions.assertNull;
import org.junit.jupiter.api.Test;
import deringo.jpa.entity.Adresse;
public class AdresseRepositoryTest {
@Test
public void getAnmeldungById() {
int adresseID = 1;
Adresse adresse = AdresseRepository.getAdresseById(adresseID);
assertNull(adresse);
adresseID = 4;
adresse = AdresseRepository.getAdresseById(adresseID);
assertNotNull(adresse);
assertThat(adresse.getObjectID(), is(adresseID));
assertThat(adresse.getStrasse(), is("Beispielstrasse"));
assertThat(adresse.getOrt(), is("Beispielstadt"));
}
}
Projektstruktur
Query
Alle Adressen eines Ortes suchen:
public static List<Adresse> getAdresseByOrt(String ort) {
EntityManager em = emf.createEntityManager();
TypedQuery<Adresse> query = em.createQuery("SELECT a FROM Adresse a WHERE a.ort = :ort", Adresse.class);
query.setParameter("ort", ort);
return query.getResultList();
}Native Query
Um zB herauszufinden, wie die zuletzt vergebene ObjectID lautet, kann ein native Query verwendet werden:
public static int getLastObjectID() {
String sequenceName = "public.object_id_seq";
String sql = "SELECT s.last_value FROM " + sequenceName + " s";
EntityManager em = emf.createEntityManager();
BigInteger value = (BigInteger)em.createNativeQuery(sql).getSingleResult();
return value.intValue();
}
Kreuztabelle
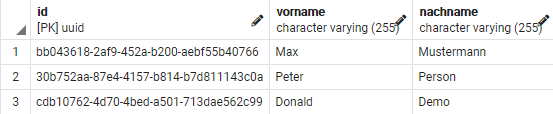
Nehmen wir mal an, eine Person kann mehrere Adressen haben und an eine Adresse können mehrere Personen gemeldet sein.
Um das abzubilden benötigen wir zunächst eine Kreuztabelle, die wir in der DB anlegen:
DROP TABLE IF EXISTS public.adresse_person;
CREATE TABLE public.adresse_person (
adresse_object_id integer NOT NULL,
person_object_id integer NOT NULL
);Solch eine Relation programmatisch anlegen:
public static void createAdressePersonRelation(int adresseId, int personId) {
String sql = "INSERT INTO adresse_person (adresse_object_id, person_object_id) VALUES (?, ?)";//, adresseId, personId);
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
em.createNativeQuery(sql)
.setParameter(1, adresseId)
.setParameter(2, personId)
.executeUpdate();
em.getTransaction().commit();
}Die Adresse zu einer Person(enID) lässt sich ermitteln:
public static Adresse getAdresseByPersonID(int personId) {
String sql = "SELECT adresse_object_id FROM adresse_person WHERE person_object_id = " + personId;
EntityManager em = emf.createEntityManager();
Integer adresseId;
try {
adresseId = (Integer)em.createNativeQuery(sql).getSingleResult();
} catch (NoResultException nre) {
return null;
}
return getAdresseById(adresseId.intValue());
}
Das funktioniert nur, solange die Person nur eine Adresse hat.
Das kann man so machen, schöner ist es aber über entsprechend ausmodellierte ManyToMany Beziehungen in den Entities.
Das Beispiel vervollständige ich hier erstmal nicht, da ich bisher es in meinem Projekt nur so wie oben beschrieben benötigte.
OneToMany
Wandeln wir obiges Beispiel mal ab: An einer Adresse können mehrere Personen gemeldet sein, aber eine Person immer nur an einer Adresse.
Wir fügen also der Person eine zusätzliche Spalte für die Adresse hinzu:
ALTER TABLE person ADD COLUMN adresse_object_id integer; -- UPDATE person SET adresse_object_id = 4
public class Person implements Serializable {
[...]
@ManyToOne
@JoinColumn(name="adresse_object_id")
private Adresse adresse;
[...]
}public class Adresse implements Serializable {
[..]
@OneToMany
@JoinColumn(name="adresse_object_id")
private List<Person> personen = new ArrayList<>();
[...]
}Anschließend noch die Getter&Setter, toString, hashCode&equals neu generieren und einen Test ausführen:
@Test
public void getAnmeldungById() {
int adresseID = 4;
adresse = AdresseRepository.getAdresseById(adresseID);
assertNotNull(adresse);
assertThat(adresse.getObjectID(), is(adresseID));
assertThat(adresse.getStrasse(), is("Beispielstrasse"));
assertThat(adresse.getOrt(), is("Beispielstadt"));
assertThat(adresse.getPersonen().size(), is(3));
}
Der Test funktioniert.
ABER: Folgende Zeile am Ende bewirkt einen StackOverflow Error:
public void getAnmeldungById() {
[...]
System.out.println(adresse);
}Das Problem ist die generierte toString-Methode in Person:
@Override
public String toString() {
return String.format("Person [objectID=%s, vorname=%s, nachname=%s, adresse=%s]", objectID, vorname, nachname,
adresse);
}
Es soll das Objekt adresse ausgegeben werden, in welchem in der toString-Methode das Objekt person ausgegeben werden soll, in welchem das Objekt adresse ausgegeben werden, in welchem in der toString-Methode das Objekt person ausgegeben werden soll, in welchem das Objekt adresse ... usw.
Als Lösung muss die toString-Methode von Person händisch angepasst werden, so dass nicht mehr das Objekt adresse, sondern lediglich dessen ID ausgegeben wird:
@Override
public String toString() {
return String.format("Person [objectID=%s, vorname=%s, nachname=%s, adresse=%s]", objectID, vorname, nachname,
adresse == null ? null : adresse.getObjectID());
}siehe auch: https://stackoverflow.com/questions/23973347/jpa-java-lang-stackoverflowerror-on-adding-tostring-method-in-entity-classes
Neuen Eintrag speichern
Adresse speichern:
public static void saveAdresse(Adresse adresse) {
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
if (adresse.getObjectID() == 0) {
em.persist(adresse);
} else {
em.merge(adresse);
}
em.getTransaction().commit();
}Testen:
@Test
public void saveNewAdresse() {
int objectID = AdresseRepository.getLastObjectID();
Adresse adresse = new Adresse();
adresse.setStrasse("neue Stasse");
adresse.setOrt("neuer Ort");
assertThat(adresse.getObjectID(), is(0));
AdresseRepository.saveAdresse(adresse);
assertThat(adresse.getObjectID(), is(objectID + 1));
assertThat(adresse.getOrt(), is("neuer Ort"));
adresse.setOrt("neuerer Ort");
AdresseRepository.saveAdresse(adresse);
assertThat(adresse.getObjectID(), is(objectID + 1));
assertThat(adresse.getOrt(), is("neuerer Ort"));
}Eintrag löschen
Man möchte meinen, dass der Code zum löschen einer Adresse wie folgt lautet:
public static void deleteAdresse(Adresse adresse) {
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
em.remove(adresse);
em.getTransaction().commit();
}Testen:
@Test
public void deleteAdresse() {
int adresseID = 8;
Adresse adresse = AdresseRepository.getAdresseById(adresseID);
assertNotNull(adresse);
AdresseRepository.deleteAdresse(adresse);
assertNull(adresse);
}Der Test schlägt fehl mit der Nachricht: "Removing a detached instance".
Das Problem besteht darin, dass die Adresse zuerst über einen EntityManager gezogen wird, aber das Löschen in einem anderen EntityManager, bzw. dessen neuer Transaktion, erfolgen soll. Dadurch ist die Entität detached und muss erst wieder hinzugefügt werden, um sie schließlich löschen zu können:
public static void deleteAdresse(Adresse adresse) {
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
em.remove(em.contains(adresse) ? adresse : em.merge(adresse));
em.getTransaction().commit();
}