Angenommen, wir haben eine Tabelle mit Personen:
CREATE TABLE person (
vorname varchar(255),
nachname varchar(255)
);
Diese Personen sollen alle eine eindeutige ID bekommen und diese soll automatisch beim Einfügen generiert werden.
Sequenz
Dazu kann man eine Sequenz anlegen und aus dieser die ID befüllen:
CREATE SEQUENCE person_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
CREATE TABLE person (
id integer NOT NULL DEFAULT nextval('person_id_seq'::regclass),
vorname varchar(255),
nachname varchar(255),
CONSTRAINT person_pkey PRIMARY KEY (id)
);
Anschließend ein paar Personen hinzufügen:
INSERT INTO person (vorname, nachname) VALUES ('Max', 'Mustermann');
INSERT INTO person (vorname, nachname) VALUES ('Peter', 'Person');
INSERT INTO person (vorname, nachname) VALUES ('Donald', 'Demo');
Und anzeigen lassen:
SELECT * FROM person;

Identity
Da es etwas lästig ist, immer für jede Tabelle jeweils eine eigene Sequenz anlegen und mit der ID verknüpfen zu müssen, wurde die Frage an mich herangetragen, ob es da nicht soetwas wie autoincrement gäbe, wie man es von MySQL kennen würde.
Nach kurze Recherche fand sich, dass es soetwas natürlich auch für PostgreSQL gibt und zwar seit der Version 10 als "IDENTITY".
CREATE TABLE adresse (
id int GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
strasse varchar(255),
ort varchar(255)
);
Anschließend ein paar Adressen hinzufügen:
INSERT INTO adresse (strasse, ort) VALUES ('Beispielstrasse', 'Beispielstadt');
INSERT INTO adresse (strasse, ort) VALUES ('Erpelweg', 'Entenhausen');
INSERT INTO adresse (strasse, ort) VALUES ('Bruchstrasse', 'Berlin');
Und anzeigen lassen:
SELECT * FROM adresse;
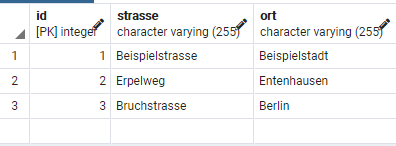
Der Vorteil der Identity, was man so auf den ersten Blick sieht, ist also, dass man sich etwas stumpfe Tipparbeit spart und keine Sequenz anlegen, mit der ID verknüpfen und die ID als Primary Key definieren muss.
Eine Betrachtung der Unterschiede zwischen SEQUENCE und IDENTITY habe ich leider nicht finden können.
Vermutlich gibt es da keine großen technischen Unterschiede, die IDENTITY scheint mir eine anonyme SEQUENCE zu sein.
Object ID Sequenz
Die IDENTITY kann man nur für einen TABLE nutzen, die SEQUENCE könnte man für mehrere Tabellen nutzen und so eine datenbankweite eindeutige ID verwenden.
Beispielsweise eine eindeutige Object ID Sequenz anlegen und für die Tabellen Person und Adresse verwenden:
CREATE SEQUENCE object_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
CREATE TABLE person (
object_id integer NOT NULL DEFAULT nextval('object_id_seq'::regclass),
vorname varchar(255),
nachname varchar(255),
CONSTRAINT person_pkey PRIMARY KEY (object_id)
);
CREATE TABLE adresse (
object_id integer NOT NULL DEFAULT nextval('object_id_seq'::regclass),
strasse varchar(255),
ort varchar(255),
CONSTRAINT adresse_pkey PRIMARY KEY (object_id)
);
Anschließend ein paar Personen und Adressen hinzufügen:
INSERT INTO person (vorname, nachname) VALUES ('Max', 'Mustermann');
INSERT INTO person (vorname, nachname) VALUES ('Peter', 'Person');
INSERT INTO person (vorname, nachname) VALUES ('Donald', 'Demo');
INSERT INTO adresse (strasse, ort) VALUES ('Beispielstrasse', 'Beispielstadt');
INSERT INTO adresse (strasse, ort) VALUES ('Erpelweg', 'Entenhausen');
INSERT INTO adresse (strasse, ort) VALUES ('Bruchstrasse', 'Berlin');
Und anzeigen lassen:
SELECT * FROM person; SELECT * FROM adresse;

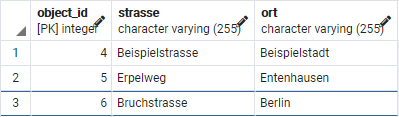
Wie man sehen kann, wurde die ID fortlaufend über beide Tabellen vergeben. Dadurch erhält man eine datenbankweit eindeutige, fortlaufende ID.
UUID
Und weil ich grade schon dabei bin: Seit Version 13 bringt PostgreSQL auch standartmäßig die Möglichkeit einer UUID mit.
Eine UUID ist ein Universally Unique Identifier.
Manchmal, typischerweise in Zusammenhang mit Microsoft, wird auch der Ausdruck GUID Globally Unique Identifier verwendet.
SELECT * FROM gen_random_uuid ();
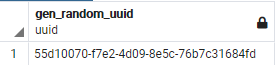
UUIDs sind ebenfalls datenbankweit (und darüber hinaus) eindeutig. Allerdings sind die IDs nicht mehr fortlaufend.
UUIDs sind etwas langsamer als Sequenzen und verbrauchen etwas mehr Speicher.
Das Beispiel von vorhin:
CREATE TABLE person (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
vorname varchar(255),
nachname varchar(255)
);
CREATE TABLE adresse (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
strasse varchar(255),
ort varchar(255)
);
Anschließend ein paar Personen und Adressen hinzufügen:
INSERT INTO person (vorname, nachname) VALUES ('Max', 'Mustermann');
INSERT INTO person (vorname, nachname) VALUES ('Peter', 'Person');
INSERT INTO person (vorname, nachname) VALUES ('Donald', 'Demo');
INSERT INTO adresse (strasse, ort) VALUES ('Beispielstrasse', 'Beispielstadt');
INSERT INTO adresse (strasse, ort) VALUES ('Erpelweg', 'Entenhausen');
INSERT INTO adresse (strasse, ort) VALUES ('Bruchstrasse', 'Berlin');
Und anzeigen lassen:
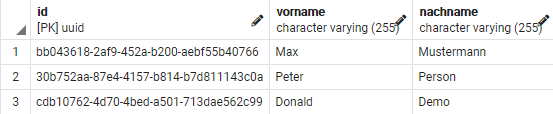
SELECT * FROM person; SELECT * FROM adresse;

One reply on “PostgreSQL IDs”
[…] die SQL-Daten werde ich auf den Artikel PostgreSQL IDs zurückgreifen und daraus zwei Scripte machen, eines für das Schema der DB und eines mit den […]