Um Daten von einem bestimmten Webservice beziehen zu können, muss der Aufruf durch einen authentifizierten User erfolgen. Der Webservice steht im Intranet des Kunden und der Aufruf im Browser funktioniert ohne Authentifizierung, denn im Hintergrund wird der Windows User übermittelt.
Der Aufruf über Java funktioniert nicht, da kein User übermittelt wird.
Die Authentifizierung am Webservice erfolgt lt. Ansprechpartner durch eine Windows Authentifizierung, was technischer ausgedrückt NTLM sein sollte.
Test Projekt aufsetzen
Um den Zugang zu testen ohne dabei den ganzen Ballast der großen Anwendung mitschleppen zu müssen, wird ein neues Projekt zum Testen aufgesetzt.
Das Projekt wird auf Java 8 konfiguriert und kommt mit einer einzigen Abhängigkeit aus: Dem Apache HTTPClient 4.5
Der Code funktioniert, wirft aber noch eine WARNING mit aus:
Mai 30, 2022 4:15:35 PM org.apache.http.client.protocol.RequestTargetAuthentication process
WARNING: NEGOTIATE authentication error: No valid credentials provided (Mechanism level: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt))
200 OK
Response body: [{"Vkorg":"","VkorgDesc":"TEST Korea Limited"}]
Test 2
public static void test02() throws Exception {
PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager();
cm.setMaxTotal(18);
cm.setDefaultMaxPerRoute(6);
RequestConfig requestConfig = RequestConfig.custom()
.setSocketTimeout(30000)
.setConnectTimeout(30000)
.setTargetPreferredAuthSchemes(Arrays.asList(AuthSchemes.NTLM))
.setProxyPreferredAuthSchemes(Arrays.asList(AuthSchemes.BASIC))
.build();
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new NTCredentials(username, password, "", ""));
// Finally we instantiate the client. Client is a thread safe object and can be used by several threads at the same time.
// Client can be used for several request. The life span of the client must be equal to the life span of this EJB.
CloseableHttpClient httpclient = HttpClients.custom()
.setConnectionManager(cm)
.setDefaultCredentialsProvider(credentialsProvider)
.setDefaultRequestConfig(requestConfig)
.build();
HttpGet httpGet = new HttpGet(url);
// HttpClientContext is not thread safe, one per request must be created.
HttpClientContext context = HttpClientContext.create();
try ( CloseableHttpResponse response = httpclient.execute(httpGet, context) ) {
StatusLine statusLine = response.getStatusLine();
System.out.println(statusLine.getStatusCode() + " " + statusLine.getReasonPhrase());
String responseBody = EntityUtils.toString(response.getEntity(), StandardCharsets.UTF_8);
System.out.println("Response body: " + responseBody);
}
}
Der Code funktioniert und wirft keine Warnung mehr aus.
Ich hatte zuerst versucht, den Reverse Proxy über scale zu vervielfältigen, aber das funktionierte nicht, da jeder RP den selben Hostnamen zugewiesen bekommt. Laut Forenkommentaren soll man das Problem wohl mittels Scripte oder Docker Swarm lösen können, für dieses kleine Projekt war es hingegen völlig ausreichend, den Block für den RP zu duplizieren.
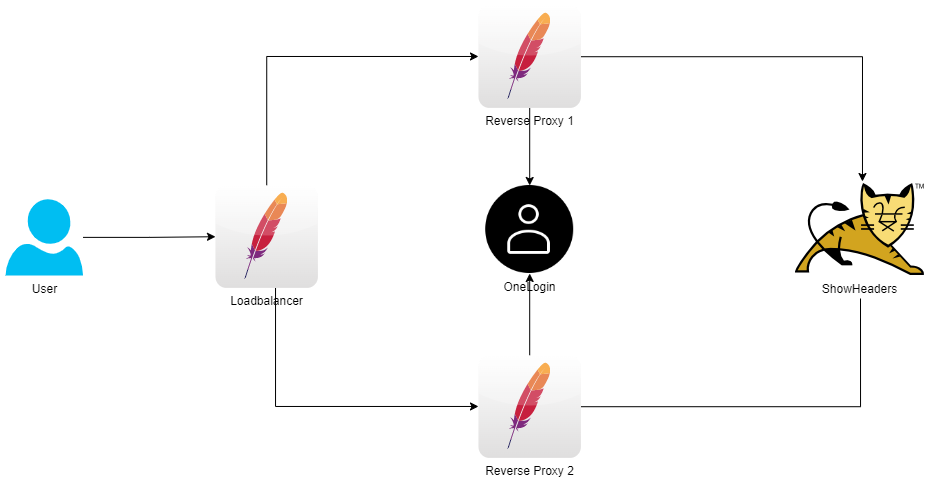
Load Balancer
Neu hinzugekommen ist der den beiden RPs vorgeschaltete Load Balancer.
Die Regel, nach der das Loadbalancing erfolgt, ist hier nicht relevant und wird nicht explizit gesetzt.
Der erste Versuch, bei dem die Anfragen abwechselnd auf den RPs verteilt werden funktioniert für die public Pages.
Der Login bei OneLogin funktioniert, aber nicht das öffnen der Seite. Anscheinend harmoniert der OneLogin Flow nicht mit diesem Setup, es scheint so, als ob die Antwort der Anfrage von RP1 an OneLogin von RP2 erhalten wird, dieser aber nichts damit anfangen kann und eine neue Authentifizierungsanfrage an OneLogin schickt, deren Antwort wiederum von RP1 erhalten wird , dieser aber nichts damit anfangen kann und eine neue Authentifizierungsanfrage an OneLogin schickt, deren Antwort wiederum von RP2 erhalten wird , dieser aber nichts damit anfangen kann und eine neue Authentifizierungsanfrage an OneLogin schickt, deren Antwort wiederum von RP1 erhalten wird, [...]
Es ist also notwendig, das wir immer auf dem selben RP landen. Das Load Balancing darf nur einmal am Anfang statt finden.
Um das zu erreichen, setzten wir einen Header, der die Route zum RP enthält und setzten die Session sticky.
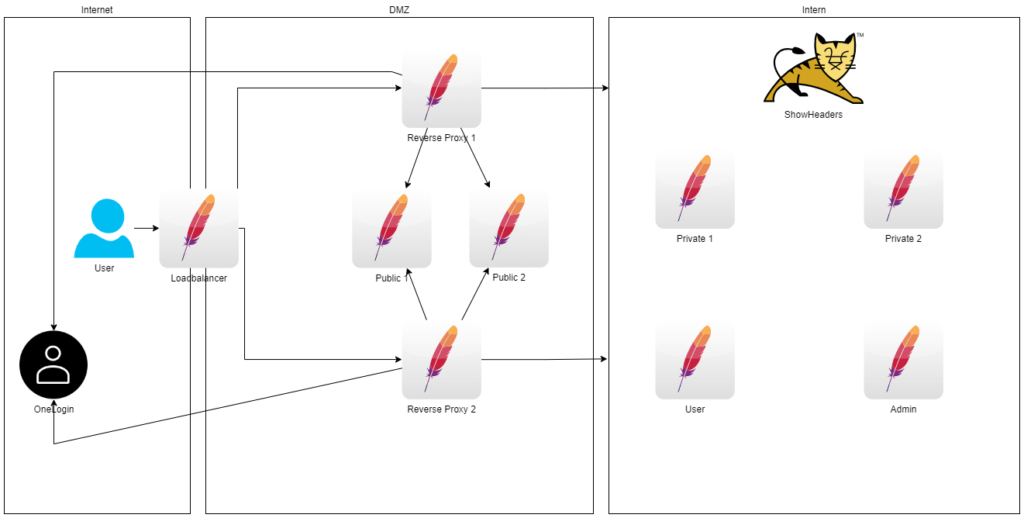
Im nächsten Schritt möchte ich verschiedene Netzwerke und Server verwenden.
Der User kommt aus dem Internet und geht über den Load Balancer in die DMZ, in der er über die RPs Zugang zu den Public Servern hat und nach Authentifizierung über OneLogin (Internet) gelangt er in das Interne Netz wo er Zugang auf den ShowHeaders und die Privaten Server hat.
Vorbereitet wird auch schon die Authorisierung über die RPs und OneLogin: Falls der Benutzer die Rolle user hat, bekommt er Zugang auf den User Server, falls er die Rolle admin hat, bekommt er Zugang auf den Admin Server.
In der Docker Compose Datei werden all die Server in der Services Sektion angelegt und den jeweiligen Netzwerken zugewiesen, in der darauf folgenden Networks Sektion definiert werden:
Das Public Netzwerk muss angelegt werden, anschließend kann Docker Compose gestartet werden:
docker network create public_network
docker-compose up
Test
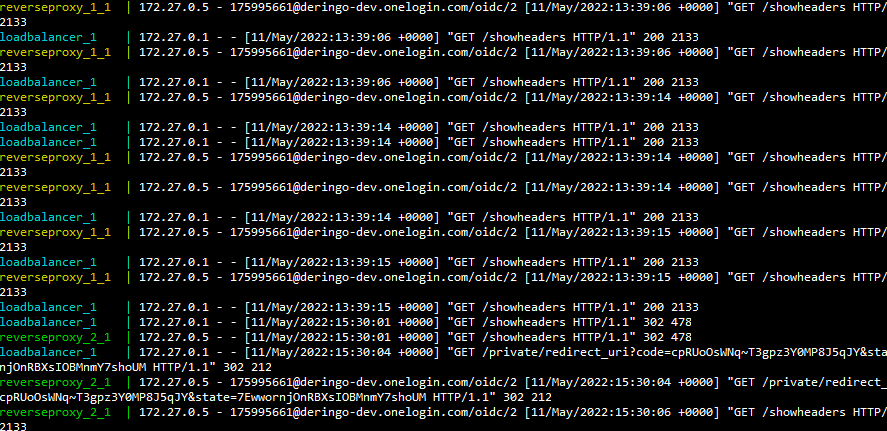
Wie zuvor: Über die Logausgaben in dem Terminalfenster, in dem Docker Compose gestartet wurde, kann man gut nachvollziehen, welche Server aufgerufen werden.
Vor dem Login werden über Load Balancer und RPs die Seiten der beiden Public Server angezeigt.
Nach dem Login werden auch die Private und ShowHeaders Seiten angezeigt.
Außerdem werden auch die Seiten der User und Admin Server angezeigt. Das sollte nur erfolgen, wenn der eingeloggte Benutzer auch die entsprechenden Rollen hat, wird aber momentan noch nicht abgefragt. Die Umsetzung wird weiter unten beschrieben, sobald ich herausgefunden habe, wie sie zu implementieren ist.
Der Zugang zu den Seiten der User und Admin Server soll nur mit entsprechenden Rollen erfolgen.
Die Implementierung ist noch offen.
UPDATE: Inzwischen konnte ich mit einem Experten für OneLogin sprechen und wurde aufgeklärt, dass es seitens OneLogin gar nicht vorgesehen ist, dass die Anwendungs-Rollen in OneLogin gepflegt werden.
Folglich kann keine Authorisierung durch den RP mit OneLogin erfolgen.
In dem Setup hat jeder eingeloggte Benutzer Zugriff auf alle privaten Seiten.
Jetzt wird das Setup erweitert, so dass es Seiten gibt, die für eingeloggte Benutzer verfügbar sind und Seiten, die nur für Administratoren verfügbar sind.
In OneLogin gibt es, soweit ich das sehen konnte, keine einzelnen Rechte, sondern nur Rollen.
Rollen anlegen
In OneLogin zwei Rollen anlegen:
user
admin
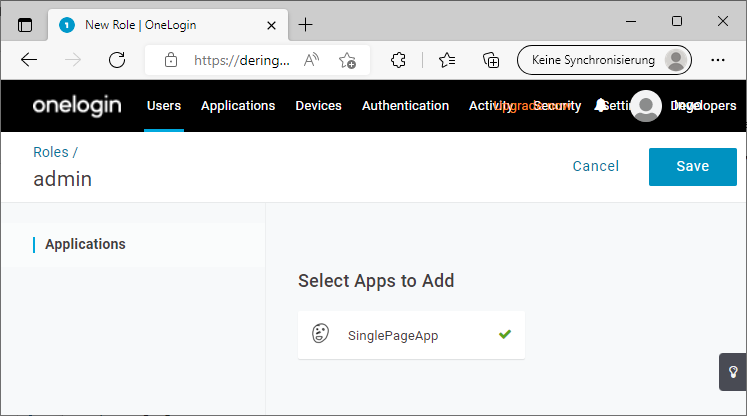
Dazu in der OneLogin Administration auf Users -> Roles -> New Role gehen und dort die Rollen anlegen, dabei direkt der App zuweisen.
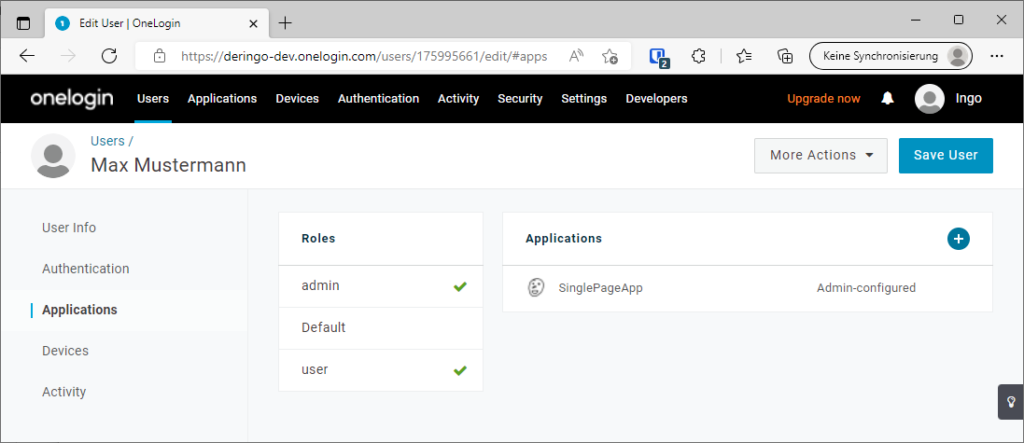
Unter Users -> Users -> User auswählen, dort unter Applications die Rollen hinzufügen:
Zu meiner Überraschung werden die Rollen von OneLogin nicht mit übergeben:
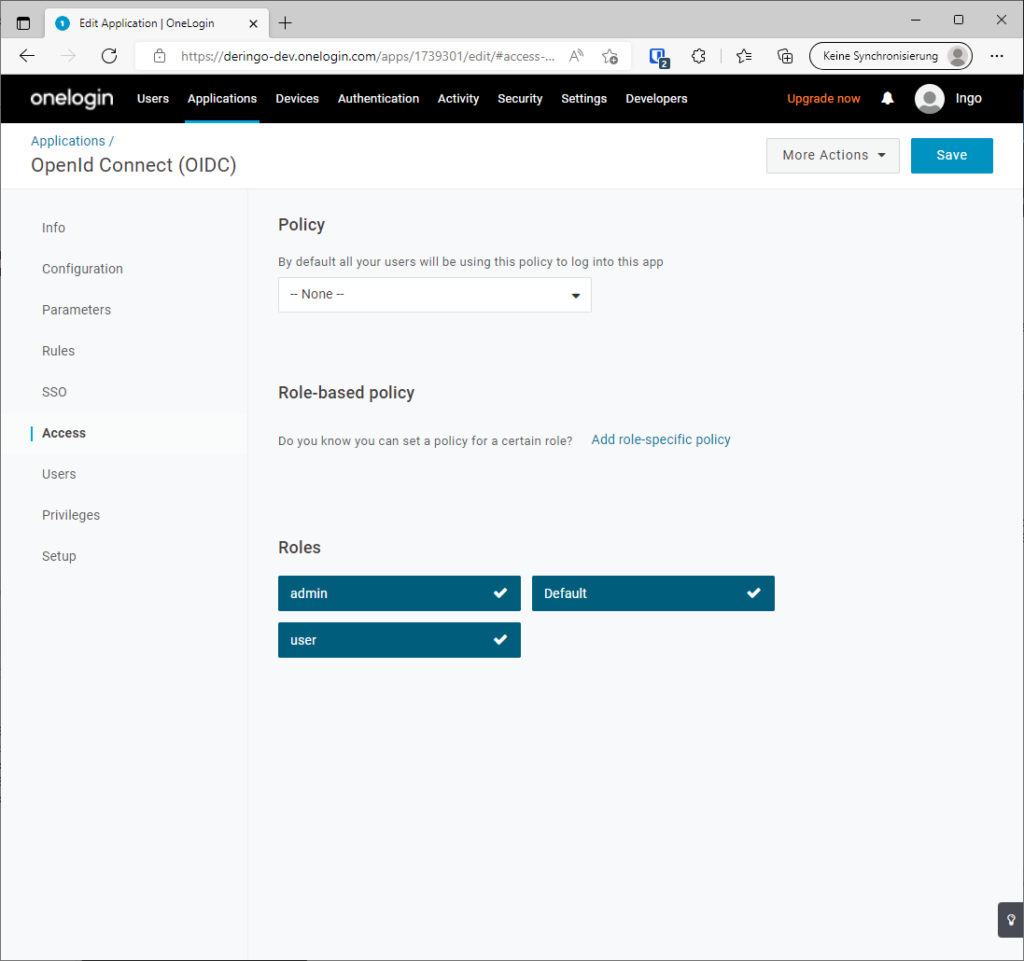
Auf Applications, Application auswählen, dort auf Access und role-specivic policy:
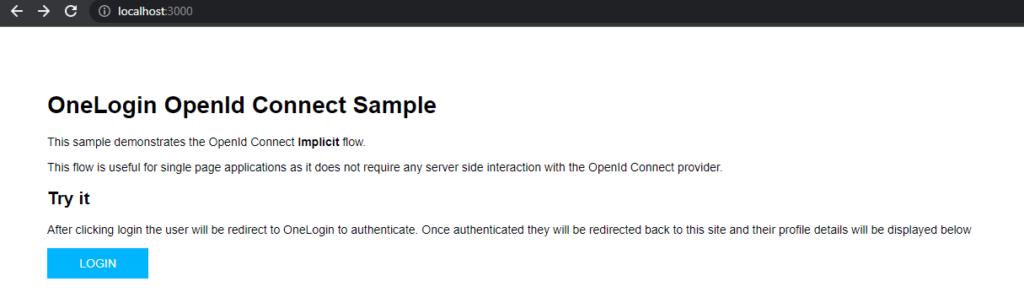
Im letzten Post habe ich mir OneLogin angeschaut und zwei Javascript Beispiele zum laufen gebracht.
In diesem Post möchte ich einen Reverse Proxy aufbauen, der eine öffentlich zugängliche Seite bereit stellt und eine private Seite nur für eingeloggte Mitglieder.
OneLogin
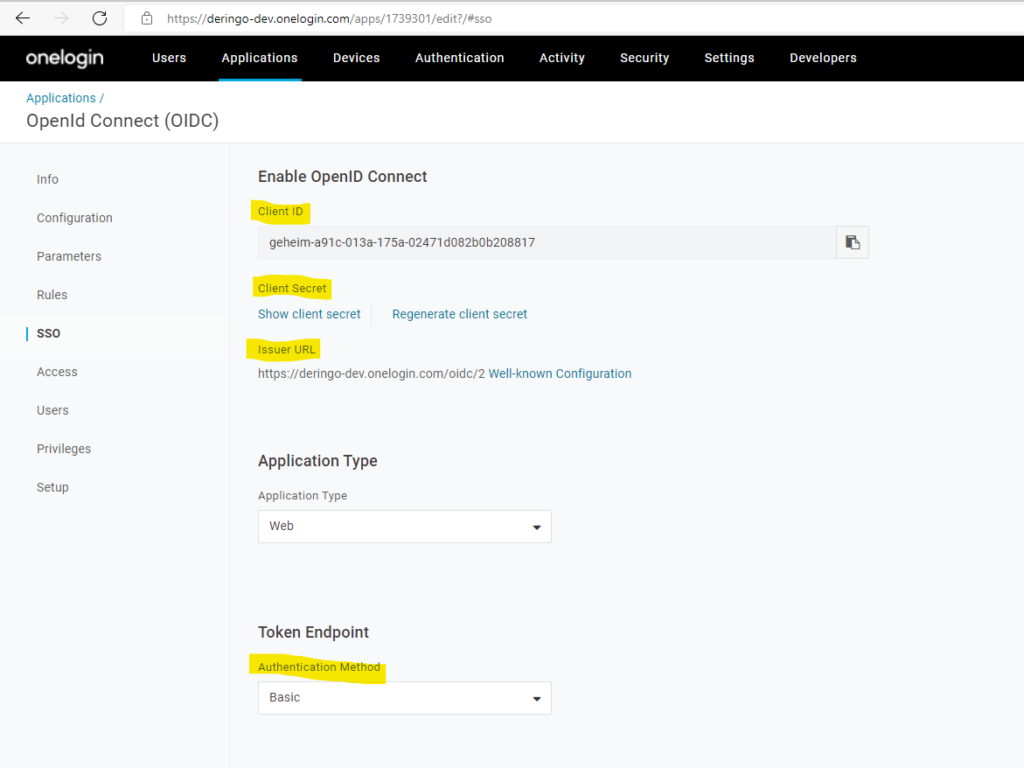
Auf der OneLogin Applications Seite sammle ich folgende Informationen ein, die später in der ReverseProxy Konfiguration benötigt werden:
Client ID
Client Secret
Issuer URL
Außerdem wird der Token Endpoint auf Basic gesetzt.
In der Configuration muss eine Redirect URI eingetragen werden, in diesem Fall: http://localhost/private/redirect_uri
Reverse Proxy
Den Reverse Proxy wird mit Docker aufgebaut.
Der Reverse Proxy wird eine Startseite bereit stellen und von dort auf eine öffentlich zugängliche Unterseite und einen geschützten Bereich verlinken.
In der ersten Version wird der geschützte Bereich lediglich eine weitere Unterseite sein.
In der zweiten Version wird ein weiterer geschützter Bereich mit der ShowHeaders App hinzugefügt.
In Eclipse habe ich zuerst das neue GitHub-Repository hinzugefügt und ausgechecked, dann händisch .project angelegt und konnte dann in Eclipse über Import das Project hinzufügen. Fühlt sich viel zu umständlich an, aber ich muss das zum Glück nicht so oft machen, als dass ich dem jetzt weiter auf dem Grund gehen müsste, wie das besser geht.
Es wird ein Docker Image angelegt, das wiederum über Docker-Compose gestartet wird, um Dateien des Filesystems einzubinden. Das ist für die Entwicklung leichter, am Ende könnte man natürlich alles in ein Image packen und starten.
Das Docker Image basiert auf dem offiziellen Apache HTTPD Image. Es wird mod_auth_openidc hinzugefügt, sowie ca-certificates um eine verschlüsselte Verbindung per HTTPS zum OneLogin-Server aufbauen zu können. Die Datei für den mod_auth_openidc muss noch an die richtige Stelle verschoben werden und ein Backup der originalen httpd.conf angelegt werden.
FROM httpd:2.4
RUN apt update && apt install -y \
libapache2-mod-auth-openidc \
ca-certificates
RUN cp /usr/lib/apache2/modules/mod_auth_openidc.so /usr/local/apache2/modules/
RUN mv conf/httpd.conf conf/container_httpd.conf
CMD ["httpd-foreground"]
Im Docker-Compose wird das Image gebaut und die HTML Seiten sowie Konfigurationsdateien eingebunden.
Dabei wird die Datei reverseproxy_httpd.conf als httpd.conf eingebunden und über diese Datei wird die zuvor gesicherte, originale httpd.conf und anschließend die reverseproxy.conf geladen. Das ist eine einfache Möglichkeit, die ursprüngliche Konfiguration zu erhalten. Für ein produktives Setup ist das vermutlich nicht die beste Wahl.
Die Variable ${PWD} ist unter Linux verfügbar, daher starte ich den Container unter Windows WSL.
Die Datei reverseproxy_httpd.conf (bzw. httpd.conf im Container) ist simpel aufgebaut und enthält nur die Includes zur ursprünglichen httpd.conf und zu unserer reverseproxy.conf:
# load original configuration first
Include conf/container_httpd.conf
# customized configuration
ServerName reverseproxy
Include conf/reverseproxy.conf
Apache HTTPD Konfiguration
Die in der OneLogin Seite eingesammelten Werte müssen entsprechend in die Konfiguration eingetragen werden.
Geschützt wird der Bereich, der unter /private liegt.
LoadModule proxy_module modules/mod_proxy.so
LoadModule xml2enc_module modules/mod_xml2enc.so
LoadModule proxy_html_module modules/mod_proxy_html.so
LoadModule proxy_connect_module modules/mod_proxy_connect.so
LoadModule proxy_http_module modules/mod_proxy_http.so
LoadModule auth_openidc_module modules/mod_auth_openidc.so
<VirtualHost *:80>
ServerAdmin deringo@github.com
DocumentRoot "/usr/local/apache2/htdocs"
ServerName localhost
## mod_auth_openidc
## https://github.com/zmartzone/mod_auth_openidc
#this is required by mod_auth_openidc
OIDCCryptoPassphrase a-random-secret-used-by-apache-oidc-and-balancer
OIDCProviderMetadataURL https://deringo-dev.onelogin.com/oidc/2/.well-known/openid-configuration
OIDCClientID geheim-a91c-013a-175a-02471d082b0b208817
OIDCClientSecret wirklich-ganz-geheim
# OIDCRedirectURI is a vanity URL that must point to a path protected by this module but must NOT point to any content
OIDCRedirectURI http://localhost/private/redirect_uri
# maps the email/prefered_username claim to the REMOTE_USER environment variable
OIDCRemoteUserClaim email
#OIDCRemoteUserClaim preferred_username
<Location /private>
AuthType openid-connect
Require valid-user
</Location>
</VirtualHost>
Im laufenden Docker Container den Apache neu durchstarten:
apachectl -t && apachectl restart
Testen
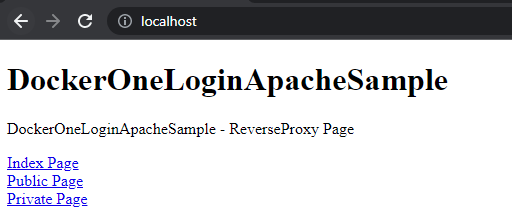
In einem neuen Browserfenster, im Inkognito Modus die Seite öffnen: http://localhost.
Der Link Index Page führt auf diese Index-Seite, der Public Page Link auf die öffentlich zugängliche Seite und Private Page auf die Seite, die nur für OneLogin User zugänglich ist.
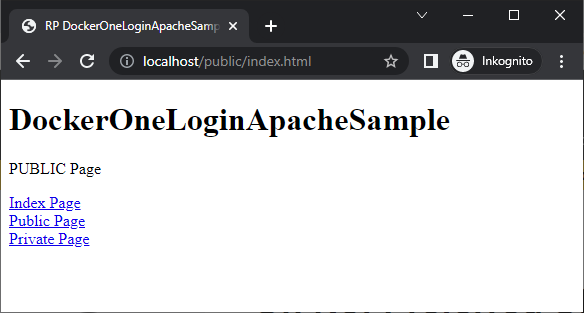
Die Public Page:
Die Private Page führt im ersten Schritt zum OneLogin Login:
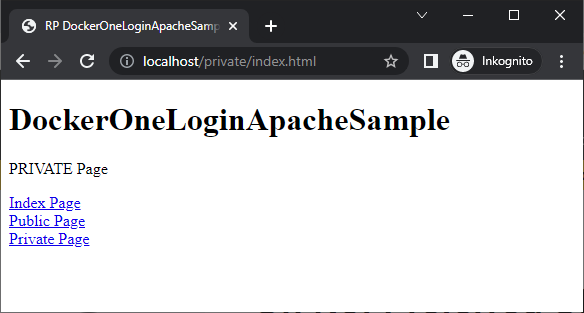
Erst nach erfolgreichem Login sehen wir die private Seite:
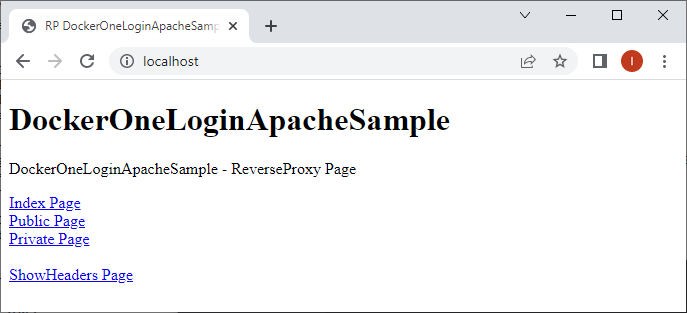
Reverse Proxy - mit ShowHeaders
Der Reverse Proxy schreibt einige Informationen in den Header, diese werden aber nur dem Server gesendet, der Client (zB unser Webbrowser) sieht davon nichts. Um sehen zu können, welche Informationen übermittelt werden, verwende ich eine kleine App, die nichts anderes macht, als die Header anzuzeigen, daher auch der Name ShowHeaders.
Bisher existierte noch kein Dockerfile für ShowHeaders, daher habe ich das für diesen Test entwickelt und hinzugefügt:
FROM tomcat:8.5-jdk8-openjdk-slim
RUN apt update && apt install -y \
maven
RUN git clone https://github.com/DerIngo/ShowHeaders.git
WORKDIR ShowHeaders
RUN mvn package
WORKDIR $CATALINA_HOME
RUN mv ShowHeaders/target/ROOT.war webapps
EXPOSE 8080
CMD ["catalina.sh", "run"]
ShowHeaders wird in die Docker Konfiguration mit aufgenommen:
Die OIDCRemoteUserClaim-Konfiguration scheint keinen Einfluss zu haben:
# maps the email/prefered_username claim to the REMOTE_USER environment variable
OIDCRemoteUserClaim email
#OIDCRemoteUserClaim preferred_username
Auf der ShowHeaders-Seite werden oidc_claim_email und oidc_claim_preferred_username angezeigt. Hingegen wird keine Header REMOTE_USER angezeigt.
Das Entfernen der OIDCRemoteUserClaim-Konfiguration hat auch keinen Einfluss auf die angezeigten Header.
Anscheinend macht diese Konfiguration nicht das, was ich erwartet hatte, daher entferne ich sie wieder. Weitere Recherchen dazu sind für diesen Test nicht notwendig, daher belasse ich es dabei.
Weitere Informationen zur Konfiguration des Mod Auth OpenIDC finden sich in der kommentierten Beispielkonfiguration auf GitHub.
GitHub
Die Dateien zu diesem Post sind im OneLogin-GitHub-Projekt unter version1 und version2 zu finden.
mkdir test
cd test
git clone https://github.com/onelogin/onelogin-oidc-node.git
cd '.\onelogin-oidc-node\2. Implicit Flow\'
npm install
--> npm ERR! Unexpected token '.'
Es kommt natürlich ein Fehler, da die Anwendung noch nicht konfiguriert ist:
Application in OneLogin anlegen
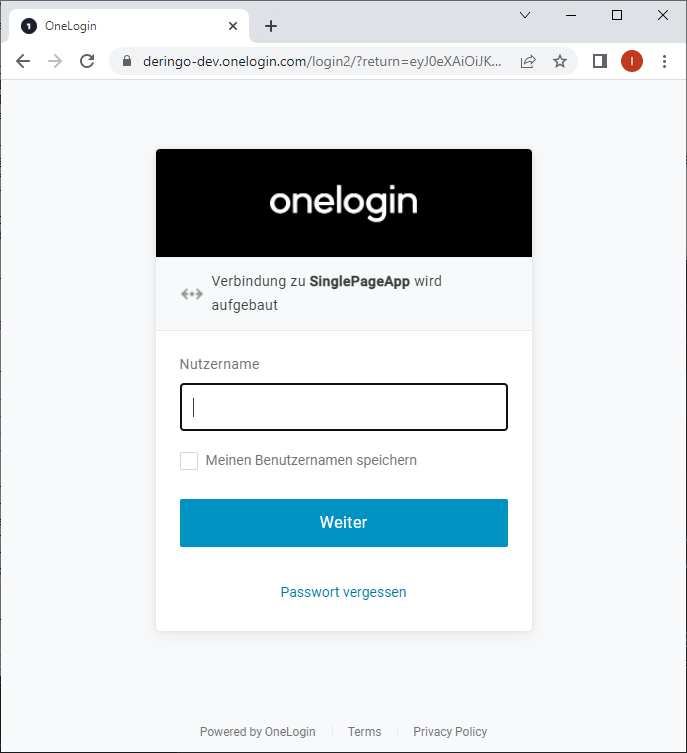
Auf der OneLogin Seite (https://deringo-dev.onelogin.com/) unter Applications auf Add gehen und eine OpenId Connect App anlegen.
Name, Beschreibung und (schnell gemaltes) Square Icon vergeben und speichern.
Im darauf folgenden Screen ist mein Square Icon leider nicht mehr vorhanden. Dafür steht dort aber ein Feld Tab, in dem etwas steht, was dort definitiv nicht stehen sollte (Name eines Kunden, woher kommt das denn??)
Ich ignoriere das erstmal und notiere mir die Client ID unter SSO.
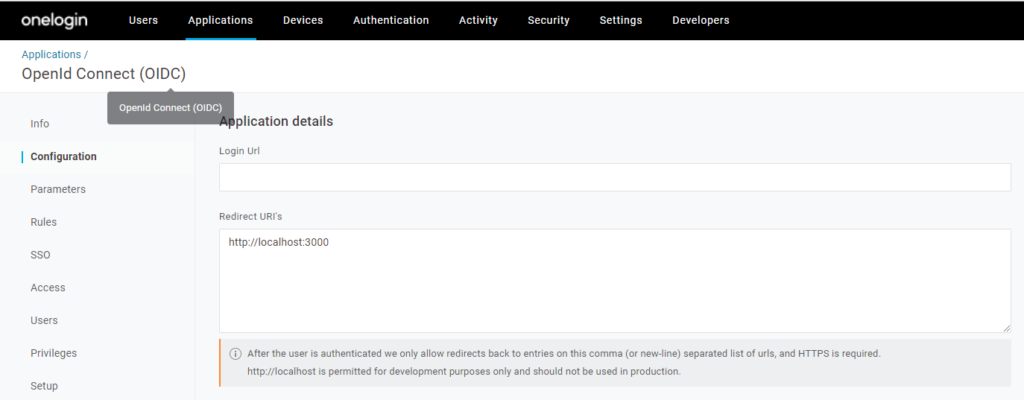
Ich muss noch die Redirect URI zu meiner App (http://localhost:3000) eintragen:
Anwendung konfigurieren
Die Client ID und meine OneLogin-Subdomain (deringo-dev) trage ich in der main.js ein.
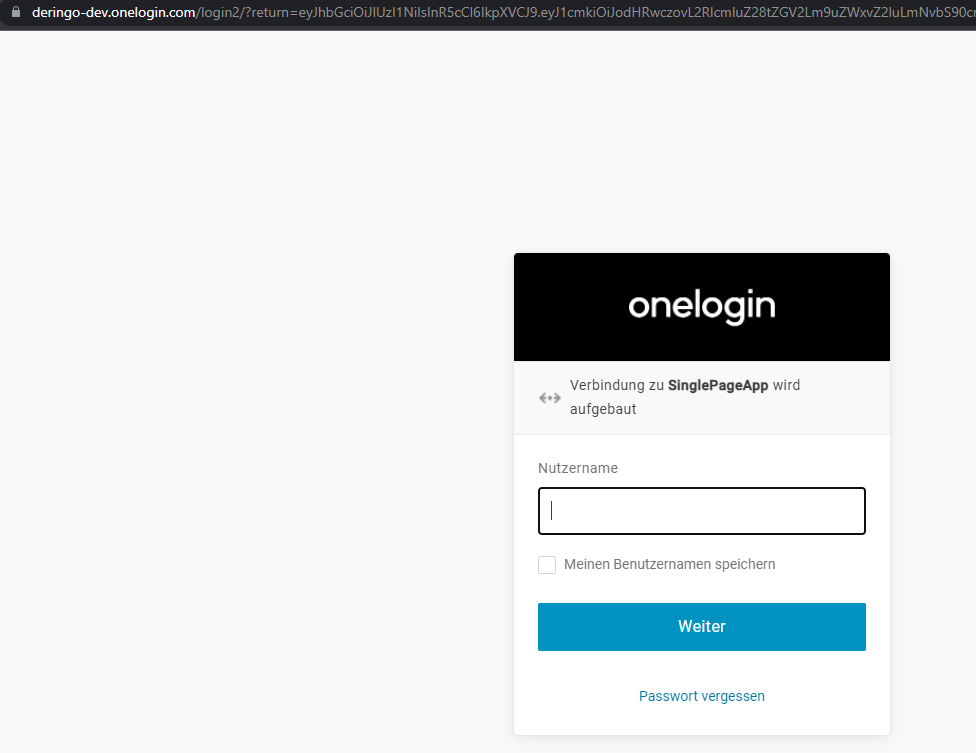
Ich kann mich mit meinen OneLogin-Developer-Zugangsdaten einloggen.
Das Ausloggen gestaltet sich bisher als unmöglich: Weder der Neustart des Servers, noch das Löschen des Local, bzw. Session Storages führt zum erneuten Login. Cookies sind keine gesetzt und können daher nicht gelöscht werden.
Über ein neues, anonymes Browserfenster lässt sich ein erneuter Login erzwingen.
Neuer User für die Beispielanwendung
Auf der OneLogin Seite (https://deringo-dev.onelogin.com/) unter Users auf New User gehen und einen neuen Benutzer anlegen.
Ein Passwort lässt sich anscheinend nicht über die OneLogin Seite für den Benutzer setzen. Für die Passwort-Wiederherstellung wird eine Email-Adresse benötigt, das ist zumindest der einzig wählbare Authentifizierungsfaktor. Ich muss meinem neuen Benutzer auch eine Email Adresse vergeben.
Das nachträgliche setzen der Email Adresse hat nicht funktioniert. Ich habe dann einen weiteren neuen Benutzer angelegt, diesmal ohne Username, dafür aber mit Email Adresse. Mit diesem Benutzer konnte ich dann das Passwort "Zurück"setzen lassen und mich anschließend einloggen.
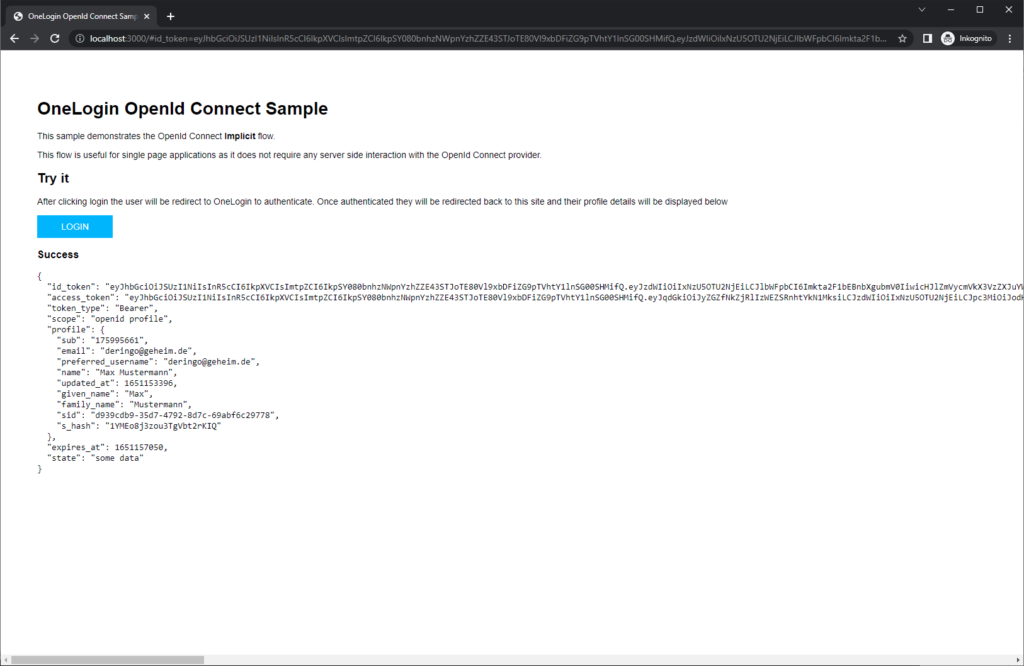
Der Login mit meinem Benutzer funktionierte problemlos.
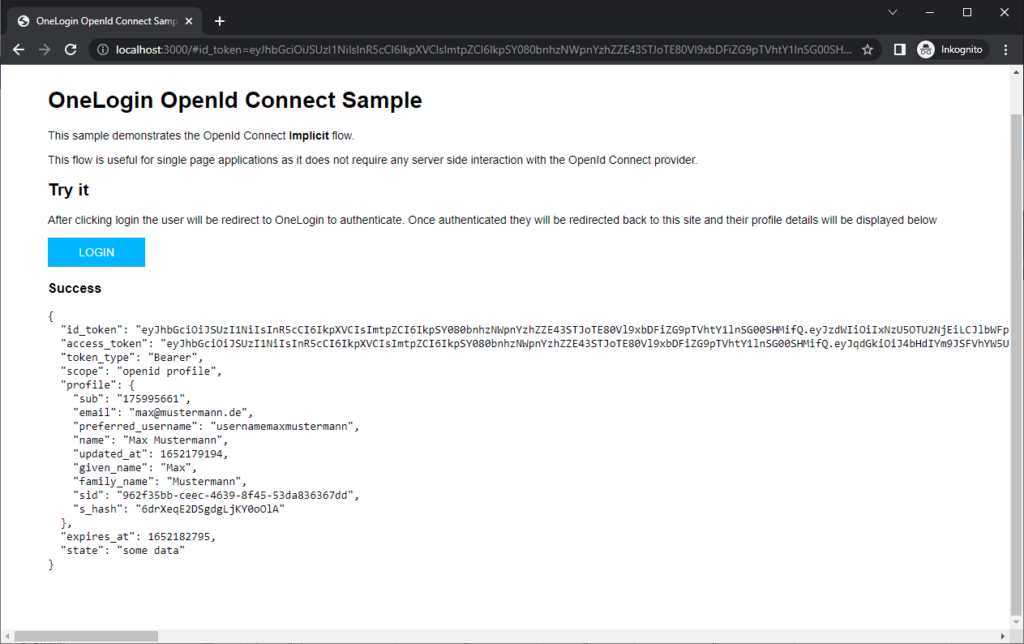
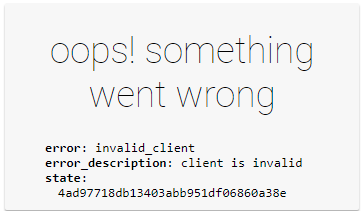
Allerdings wurden anschließend auf der Sample Seite NICHT die Benutzer Daten angezeigt.
Ein Blick in die Console des Browsers zeigt den Fehler:
Da die minified Version des oidc-client.js nicht sonderlich leserlich ist, lade ich die nicht-minified Version herunter und speichere sie neben der minified Version im Projekt ab.
In der Datei index.hbs wird das oidc-client Script importiert, also passe ich dort die Referenz an.
Aber auch das debuggen mit der nicht-minified Version brachte keinen weiteren Erkenntnisgewinn.
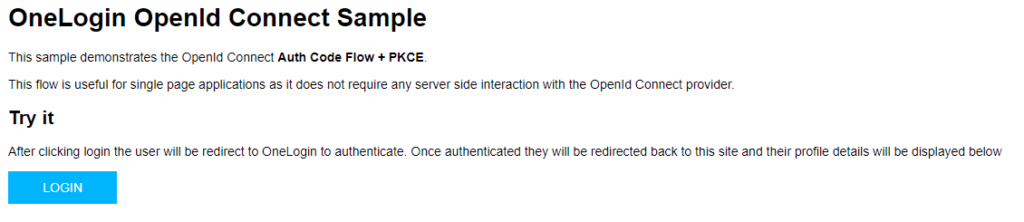
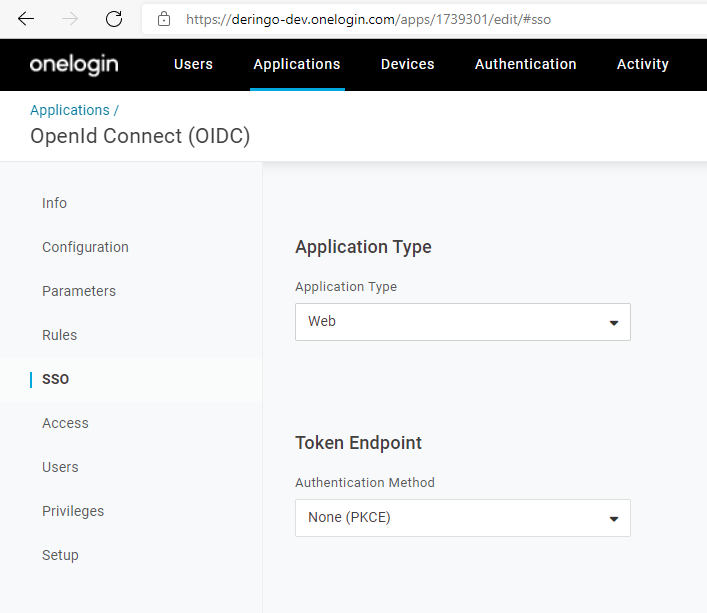
Die Lösung fand sich schließlich in der OneLogin Konfiguration: Im SSO Teil der Applikation musste der Token Endpoint auf "None (PKCE)" umgestellt werden.
Ich möchte im AWS Ökosystem bleiben und daher die Domain über Amazon Route 53 registrieren. Ansonsten hätte ich vielleicht einen anderen Anbieter gewählt, wie ich es schon für eine günstige Website gemacht hatte.
Wahl des Domainnamens
Das Projekt wird, zumindest auf meiner Infrastruktur, mutmaßlich nicht allzulange bestehen bleiben. Eine große Marktrecherche für einen tollen Namen brauche ich daher nicht, nur einprägsam sollte er sein.
Die wichtigste Anforderung ist ein günstiger Preis.
Die Preisübersicht auf der AWS Seite ist nicht sonderlich übersichtlich, eine "route 53 cheapest domain" zu googeln brachte aber auch nur den Link auf ein PDF zu Tage. In dem steht uA der "Registration and Renewal Price" und der ist für den TLD Namen "click" mit 3 Dollar am günstigsten.
Allerdings ist "click" nicht der beste Name im deutschsprachigen Raum: "Hey, besuch doch mal meine Seite meineApp.click" "Ich kann meineApp.klick nicht finden".
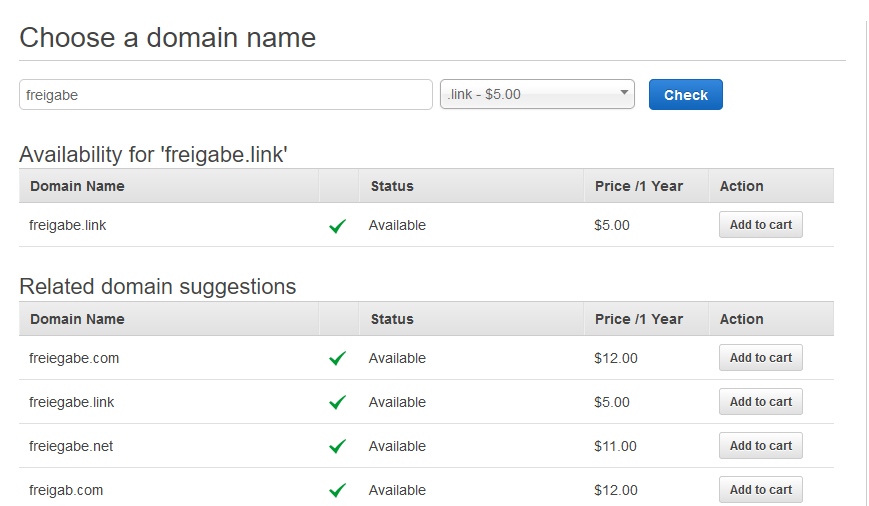
Der zweitgünstigste TLD Name mit 5 Dollar ist "link". "link" ist mir lieber als "click" und ist von der Preisdifferenz vertretbar.
Nach kurzem Brainstorming habe ich mich dann für den Namen "freigabe" und der TLD "link", also http://freigabe.link entschieden.
Domainname registrieren
Auf die Seite des Dienstes Route 53 gehen und dort die "Domain registration" aufrufen und die gewünschte Domain eingeben:
Ab in den Shopping cart und ... im nächsten Schritt muss ich meine Daten eingeben? Hey Amazon, die habt ihr doch schon!
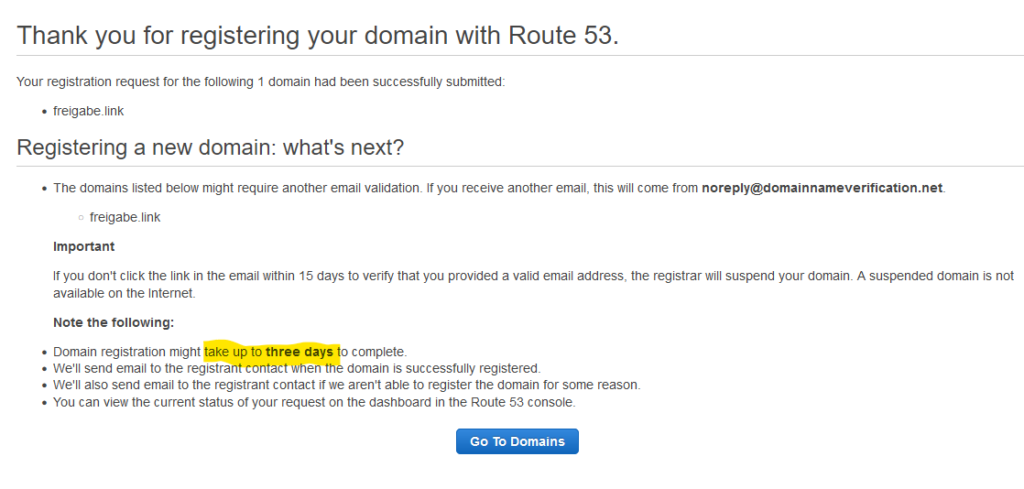
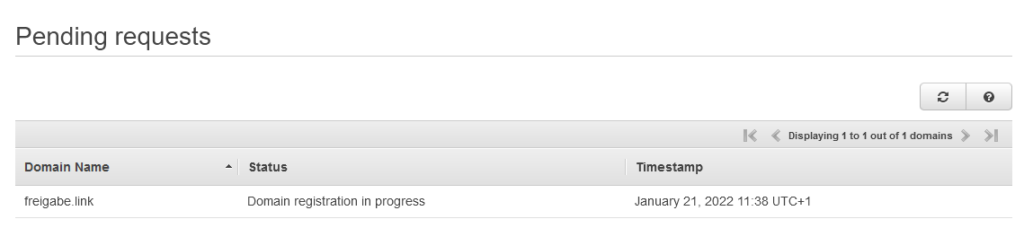
Anschließend wird die Domain auf mich registriert, was leider bis drei Tage dauern kann.
Bis zum Abschluss der Registrierung wird hier pausiert, anschließend geht es weiter mit der
Anbindung Domain Name an EC2
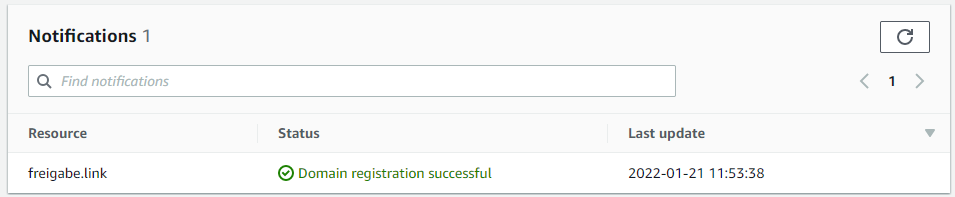
Die Registrierung der Domain war zum Glück bereits nach drei Stunden abgeschlossen und nicht erst nach drei Tagen. Negativ ist zu erwähnen, dass die 5 Dollar für den Domain Namen netto sind, also noch mal 19% USt hinzu kommen.
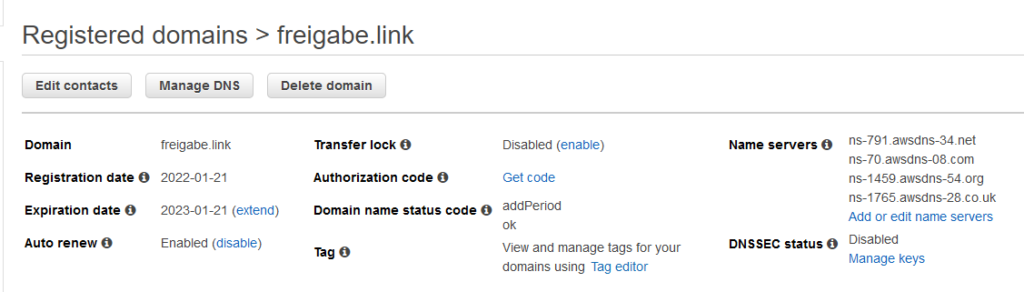
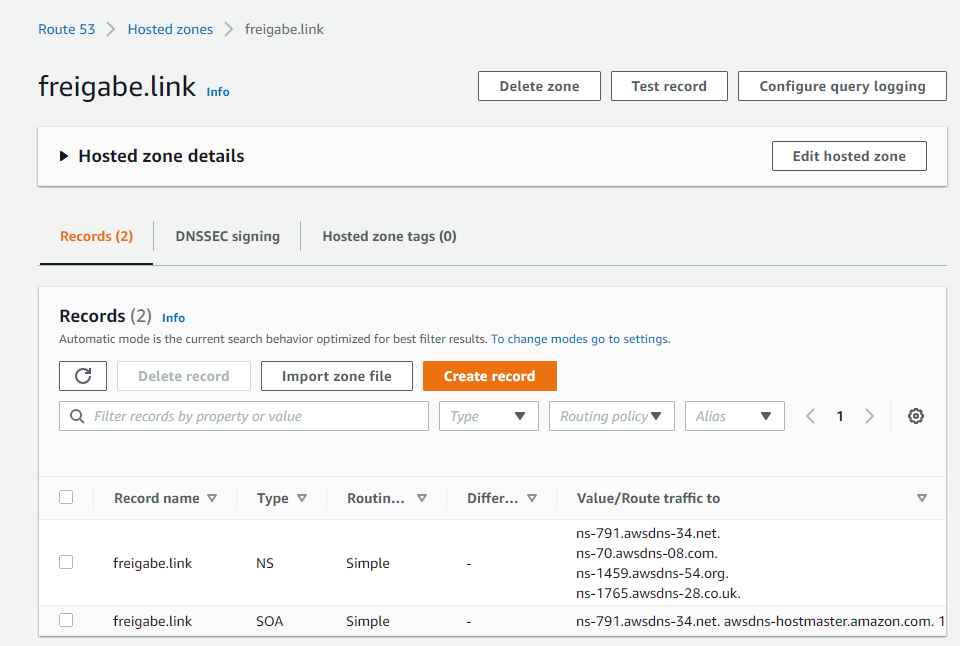
Auf der Route 53 Seite über Domains > Registered domains die Domain freigabe.link auswählen:
Über Manage DNS geht es in die Hosted zone der Domain:
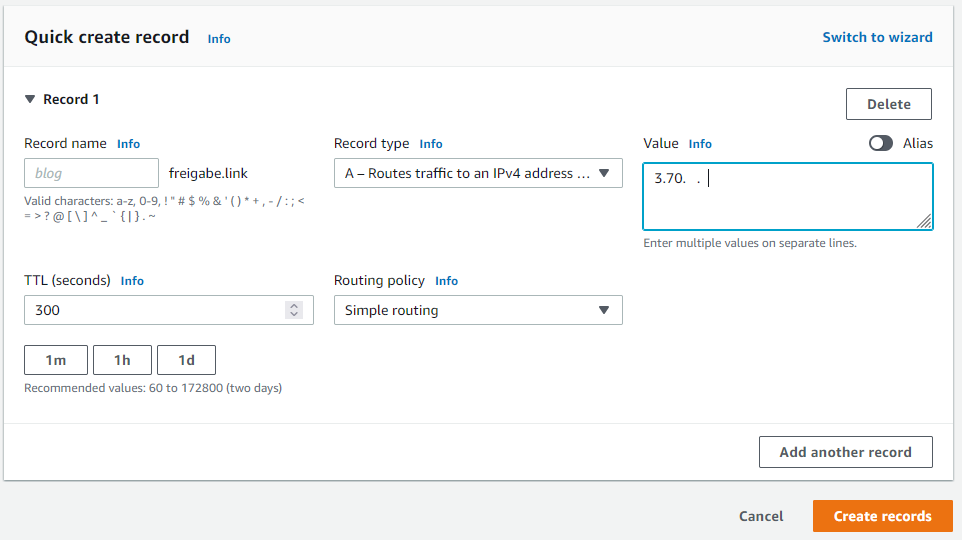
Über Create record wird der Eintrag gesetzt, dass der Domain Name auf die Public IP des EC2-Servers zeigen soll:
Nachdem ich den Web-Server gestartet hatte, funktionierte es auch sofort.
Der Web-Server war heruntergefahren. Ob ich das gestern noch gemacht hatte, weiß ich nicht mehr 100%ig. In dem Catalina Log vom Tomcat fand sich uA folgender Eintrag:
Invalid character found in the request target [/index.php?s=/Index/\think\app/invokefunction&function=call_user_func_array&vars[0]=md5&vars[1][]=HelloThinkPHP21 ]. The valid characters are defined in RFC 7230 and RFC 3986
Vielleicht gab es zu viele dieser Hacking Versuche?
Als nächstes kommt noch ein Reverse Proxy davor, der kann noch etwas Traffic vom Tomcat fern halten. Vielleicht werde ich aber auch noch eine WAF vor den Server setzen? Eine kurze Recherche zu dem Thema ergab allerdings, dass das nicht direkt möglich ist, sondern ein Application Load Balancer oder CloudFront zwischengeschaltet werden muss.
EMail
Ein Nebenschauplatz ist das Thema email, so dass ich Mails an diese Domain empfangen bzw. versenden kann.
Das Thema ist leider nicht ganz so simpel gelöst, wie ich es mir erhofft hatte. Einen simplen "AWS Mail Service", den man über Route 53 konfigurieren kann, gibt es nicht. Es gibt mit Amazon Workmail eine SaaS Lösung mit Focus auf Unternehmen und entsprechender Kostenstruktur.
Weiterhin wird Google Apps verschiedentlich empfohlen, aber auch das ist mit Kosten verbunden und wird nicht über die kostenfreien Angebote abgedeckt.
Eine SES / S3 Lösung deckt nur rudimentär den Bedarf, zB werden die Mails als Dateien auf einem S3 Bucket gespeichert. Da scheinen auch noch andere Konstellationen möglich zu sein, aber keine, die überzeugt.
Als kostenfreie WebMail-Lösung wird zB Zoho empfohlen. Eine Anleitung findet sich zB hier.
Es wäre natürlich auch möglich, einen eigenen WebMail-Server auf einem eigenen EC2 Server zu betreiben.
Als Mittelweg wäre auch ein weiter Docker Container auf dem vorhandenen EC2 Server möglich.
Jede Lösung ist mit mehr oder weniger Aufwand realisierbar, aber jede Lösung ist aufwändiger als meine momentane Motivation, oder aktueller Bedarf, und so setzte ich das erstmal auf die "wenn mal Zeit ist"-Liste.
In meinem letzten Blogeintrag habe ich eine geDockerte Anwendung auf einem Server mit Ubuntu 18 zum laufen gebracht. Aus verschiedenen Gründen war das aber nur ein Zwischenschritt, um zu testen, ob die Anwendung grundsätzlich in solch einer Umgebung lauffähig ist. Neben den beschriebenen Problemen gab es noch viele weitere, die gelöst werden mussten.
Als nächsten Schritt möchte ich die Anwendung in die AWS umziehen, immerhin bin ich ja inzwischen ein zertifizierter Cloud Practitioner.
AWS User
Mit dem Stammbenutzer einen neuen IAM Nutzer für die Anwendung anlegen. Dieser bekommt erstmal umfangreiche Rechte, was nicht best Practice ist und später sollte ich diese Rechte auf das unbedingt benötigte zurücksetzen.
EC2 Server
Die Anwendung soll erstmal mit dem Docker Setup auf einem EC2 Server laufen.
Mit dem neuen IAM Nutzer wechsele ich zuerst auf die Europa Zone ec-central-1.
Ich lege eine neue EC2 Server Instanz an, wobei ich als Sparfuchs nach "nur kostenloses Kontingent" filtere und ein AMI für Ubuntu Server 20.04 LTS (x64) und Typ t2.micro auswähle. Es wird ein neues Schlüsselpaar erzeugt und ich speichere den privaten Schlüssel.
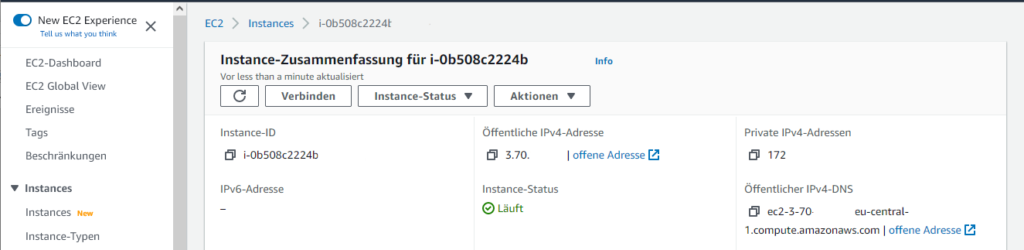
Über EC2 > Instances > Server-Instanz auswählen.
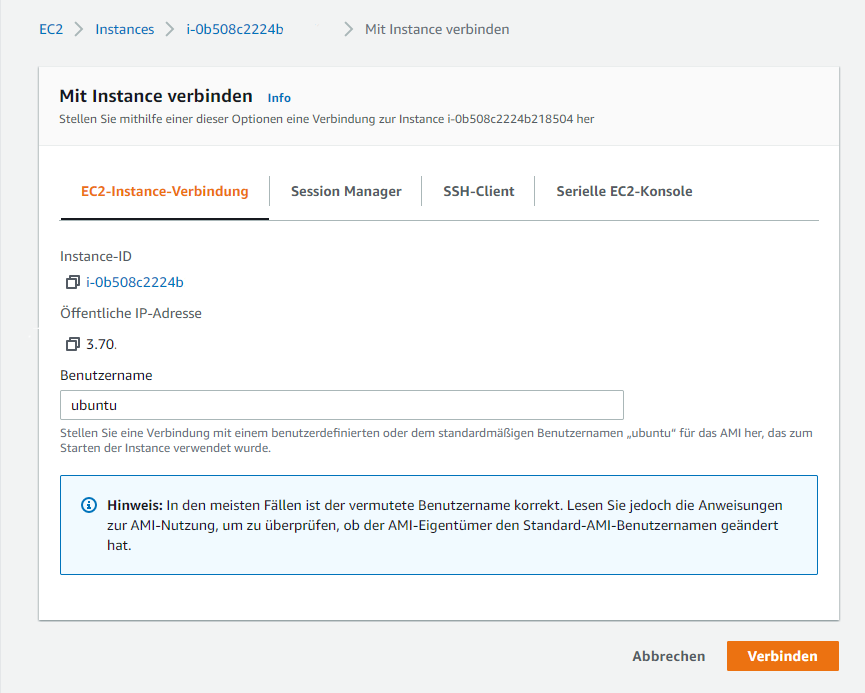
Über Verbinden lässt sich im Browser ein Terminal öffnen. Hier lässt sich aber auch am einfachsten die öffentliche IP und vor allem der Benutzername finden:
Ich habe allerdings nicht die Web Shell verwendet, sondern die Daten, sowie den privaten Schlüssel genommen, um eine Verbindung in WinSCP einzurichten. So kann ich später leicht die Daten auf den Server kopieren und per Klick eine PuTTY-Shell öffnen.
Port Freigabe
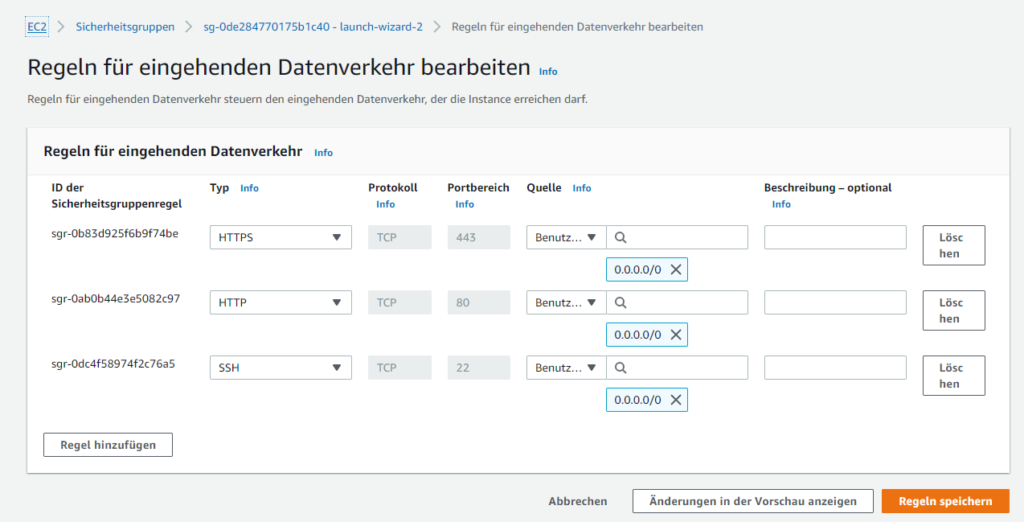
Standardmäßig ist für den Server nur Port 22 für SSH frei gegeben.
Weitere Ports, wie zB der benötigte HTTP Port 80 oder HTTPS 443, lassen sich über die AWS Management Console frei geben.
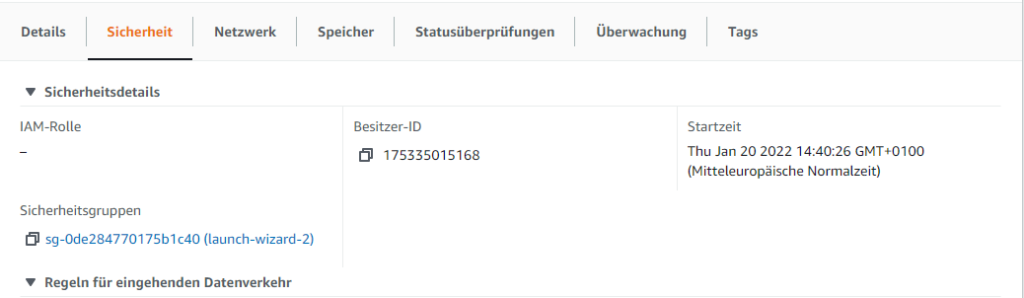
Die EC2-Server-Instanz auswählen und unter Sicherheit findet sich die Sicherheitsgruppe:
In der Sicherheitsgruppe können die Regeln für den eingehenden Datenverkehr erweitert werden. Dabei ist zu beachten, dass man weitere Regeln hinzufügen muss und nicht den bestehenden Typ SSH auf zB HTTP ändert und speichert, weil das diesen nur ändert und nicht als neue, weitere Regel hinzufügt. Dann kann man zwar die Seiten des Webservers bewundern, aber sich nicht mehr per SSH einloggen.
Server einrichten
Auf der Linux Konsole des EC2-Servers wird dieser eingerichtet, dazu wird Docker Compose installiert, was als Abhängigkeit Docker mitbringt.
apt list --upgradable
sudo apt update
sudo apt upgrade -y
sudo apt install docker-compose -y
sudo docker version # -> 20.10.7
sudo docker-compose version # -> 1.25.0
sudo service docker status # -> running
sudo docker run hello-world
Docker läuft und es werden die Daten der Anwendung auf den Server kopiert und anschließend über Docker Compose gestartet.
sudo docker-compose up
Leider führte das zu einem Fehler, wie er schon bei der Ubuntu 18 Installation aufgetreten ist. Das zuvor gewonnene Wissen kann ich jetzt zur schnellen Fehlerbehebung anwenden:
sudo apt-get remove docker-compose -y
sudo curl -L https://github.com/docker/compose/releases/download/v2.2.3/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
docker-compose --version
# Output:
-bash: /usr/bin/docker-compose: No such file or directory
# Lösung: neue Shell, zb per tmux, starten
# und dann nochmals testen
docker-compose --version
# Output:
Docker Compose version v2.2.3
Anschließend ließ sich die Anwendung per Docker Compose starten und per cURL, bzw. HTTPie, über localhost:80 und <öffentlicheIP>:80 aufrufen. Der Aufruf <öffentlicheIP>:80 vom Entwickler Laptop funktioniert auch.
Der Start dauerte etwas länger, die Webanwendung selbst ließ sich anschließend aber angenehm schnell bedienen. Zumindest als Test-Server scheint der "Gratis"-EC2-Server völlig auszureichen.
Ausblick
Auf dem kostenfreien Server laufen ein Tomcat Webserver, eine PostgreSQL Datenbank und PGAdmin und das, zumindest den ersten Tests nach, mit völlig ausreichender Performance.
Als nächstes möchte ich dem Docker Compose Konstrukt noch um einen Reverse Proxy erweitern, der eine (vermutlich nur selbstsignierte) verschlüsselte Verbindung per HTTPS anbietet und über Port 80 und 443 die Anwendung und den PGAdmin erreichbar macht. Außerdem soll es einen einfachen Authentifizierungs- und ggf. Authorisierungsmechanismus geben. Das wird mit einem Apache HTTP Server realisiert werden und sollte keinen besonderen Ressourcenbedarf haben.
Falls sich die Zeit findet, möchte ich das um Keycloak erweitern und den Zugriff auf Anwendung und PGAdmin erst nach erfolgreicher Authentifizierung und Authorisierung erlauben. Vielleicht ist das noch mit dem Apache HTTP Server realisierbar, ggf. werde ich aber auf zB Traefik umstellen. Bei dem Setup kann ich mir schon vorstellen, dass die Ressourcen des kleinen Server nicht mehr ausreichen und es zu spürbaren Performanceeinbrüchen kommen wird.
Eine ansprechendere URL, anstelle der generierten AWS URL, wäre wünschenswert.
Docker Compose Datei vom Entwicklungsrechner auf den Server kopieren, kleinere Anpassungen vornehmen und ausführen. So einfach habe ich es mir vorgestellt, aber es gab dann leider doch noch Herausforderungen zu bewältigen:
Docker Compose Updaten
Ich habe einen Server mit dem nicht mehr ganz taufrischen Ubuntu 18 am laufen und wollte dort ein Docker Compose Skript ausführen.
Das Skript läuft auf meinem Entwicklungsrechner, aber auf dem Server wurde lediglich eine Fehlermeldung ausgegeben:
dockeruser@myServer:~/myproject$ docker-compose up
ERROR: Version in "./docker-compose.yml" is unsupported. You might be seeing this error because you're using the wrong Compose file version. Either specify a supported version (e.g "2.2" or "3.3") and place your service definitions under the `services` key, or omit the `version` key and place your service definitions at the root of the file to use version 1.
For more on the Compose file format versions, see https://docs.docker.com/compose/compose-file/
Wie sich herausstellte, war für Ubuntu 18 bei Docker Compose 1.17.1 Schluss und ich muss händisch upgraden:
Docker Compose entfernen:
sudo apt-get remove docker-compose
Die aktuelle Docker Compose Version ermitteln (heute: 2.2.3): https://github.com/docker/compose/releases
Auf dieser Seite kann man auch den direkten Link zum Download finden, falls es beim ausführen des nächsten Befehls zu Problemen kommt.
Beispielsweise ist die Versionsnummer v2.2.3, also mit einem kleinen "v" am Anfang und wenn das fehlt, schlägt der Download fehl.
So lautet der Link für mein Ubuntu: https://github.com/docker/compose/releases/download/v2.2.3/docker-compose-linux-x86_64
Looks like this is because it defaults to use the secretservice executable which seems to have some sort of X11 dependency for some reason. If you install and configure pass docker will use that instead which seems to solve the problem.
# substitute with the latest version
url=https://github.com/docker/docker-credential-helpers/releases/download/v0.6.4/docker-credential-pass-v0.6.4-amd64.tar.gz
# download and untar the binary
wget $url
tar -xzvf $(basename $url)
# move the binary to a dir in your $PATH
sudo mv docker-credential-pass /usr/local/bin
# verify it works
docker-credential-pass list
# cleanup
rm docker-credential-pass-v0.6.4-amd64.tar.gz
gpg: agent_genkey failed: Keine Berechtigung Schlüsselerzeugung fehlgeschlagen: Keine Berechtigung
Und eine Erklärung mit Lösungsvorschlag findet sich hier:
Expected behavior. Here's why. At the point of failure, gen-key is about to ask the user for a passphrase. For security purposes, rather than using stdin/stdout, it wants to directly open the controlling terminal for the session and use that handle to write the prompt and receive the passphrase. When you use su to switch to some other user, the owner of the controlling terminal device file does not change; it remains associated with the user who actually logged in (i.e. received a real terminal from getty or got a pty from telnet or ssh or whatever). That device file is protected mode 600, so it can't be opened by anyone else.
The solution is to sudo-chown the device file to the user-who-needs-to-gen-the-key before su'ing to that user. Create the key within the su'd environment, then exit back to the original environment. Then, finally, sudo-chown the terminal back to yourself.
Glücklicherweise geht es auch einfacher, indem man einfach das Programm tmux verwendet. 🙂
tmux
# create a gpg2 key
gpg2 --gen-key
# list key information
gpg2 -k
# Copy the key id (from the line labelled [uid]) and do
pass init "whatever key id you have"
Jetzt sollte der Docker Login funktionieren, aber:
Auch wieder kein neues Problem, dass zB bereits hier und hier diskutiert wurde.
mkdir ~/.docker
touch ~/.docker/config.json
# brachte jeweils keine Änderung
/usr/local/bin/docker-credential-pass
# Output:
-bash: /usr/local/bin/docker-credential-pass: Keine Berechtigung
# Erfolg kam mit diesem Befehl:
sudo chmod +x /usr/local/bin/docker-credential-pass
#Zumindest funktioniert dieser Aufruf:
docker-credential-pass list
# Ein weiterer Fehler ließ sich beheben durch:
export GPG_TTY=$(tty)
Ich musste die einzelnen Images per docker pull imagename ziehen, erst danach konnte ich docker-compose ausführen.
Die Konfiguration in Java war für mich jahrelang kein Problem, denn ich durfte mit einem Framework arbeiten, dass die Konfiguration sehr flexibel und komfortabel gelöst hat.
Beispielsweise konnte die URL für ein angebundenes System für die verschiedenen Stages ganz einfach in einer ini-Datei hinterlegt werden:
Diese ini-Datei ist Teil des Java Projekts und liegt im Classpath.
In der ini-Datei sind alle Informationen zu allen Stages zum OtherSystem gespeichert, was ich immer sehr übersichtlich und leicht zu pflegen fand.
Für die laufende Anwendung muss dann lediglich die Stage festgelegt werden, in welcher sie läuft und dann wird die Konfiguration passend zur Stage gezogen. Die Stage kann definiert werden über eine Konfiguration mit der Zuweisung über den HostName, eine System Property (zB im Tomcat definiert) oder über eine lokale Konfigurationsdatei.
Praktisch ist auch die Möglichkeit, über die lokale Konfigurationsdatei einzelne Konfigurationen überschreiben zu können. So ist es beispielsweise möglich, auf dem Entwicklerrechner in der DEV-Stage zu laufen, aber die Verbindung zur PROD DB zu konfigurieren um einen Bug zu reproduzieren.
Das Thema Sicherheit lasse ich bewusst außen vor, denn hier soll es einzig um die Konfiguration gehen.
Als ich dann ein Projekt in einem anderen Kundenkreis startete, und das propritäre Framework nicht mehr verwenden konnte, war ich schon sehr erstaunt, dass es anscheinend keine schlanke, flexible Möglichkeit der Konfiguration im Java SE Umfeld gibt.
Also muss ich selbst etwas basteln, etwas kleines, leichtgewichtiges und trotzdem flexibles.
Anforderung
Von dem Luxus, sämtliche Konfigurationen per Präfix in verschiedenen Dateien im Projekt zu hinterlegen, muss ich mich verabschieden. Statt dessen wird es eine Konfigurationsdatei im Projekt geben, deren Konfiguration dann von außen überschrieben werden muss. Beispielsweise mit den Datenbankverbindungsparametern auf dem PROD Server. Aufgrund der geringeren Komplexität des Projektes ist das aber durchaus ausreichend.
Die im Projekt hinterlegte Standard-Konfiguration soll über eine lokale Konfigurationsdatei überschrieben werden können. Dazu muss eine Umgebungsvariable (System Environment, bzw. System Property) "localconf" gesetzt werden, die auf diese Datei zeigt.
Außerdem sollen einzelne Konfigurationen über Umgebungsvariablen (System Environment, bzw. System Property) gesetzt werden können.
In den Umgebungsvariablen stehen sehr viele Konfigurationen, wie zB JAVA_HOME,TMP, user.name etc., welche nicht direkt mit der Anwendung zu tun haben. Ob diese Werte auch in unserer Anwendungskonfiguration aufgenommen werden sollen, wird über eine Property "config.includeSystemEnvironmentAndProperties" gesteuert.
Umsetzung
Zum Nachlesen dokumentiere ich hier ein paar Schritte aus dem Code, das Ganze soll später auch in einem GitHub Projekt landen.
Zuerst die Properties aus System Environment und System Properties sammeln:
// System Environment
Properties systemEnvironmentProperties = new Properties();
systemEnvironmentProperties.putAll(System.getenv());
// System Properties
Properties systemPropertiesProperties = new Properties();
systemPropertiesProperties.putAll(System.getProperties());
Die BaseProperties / Standard Properties aus dem ClassPath der Anwendung laden, sie müssen unter: /src/main/resources/application.properties gespeichert sein:
String basePropertiesFilename = "application.properties";
Properties baseProperties = new Properties();
try {
InputStream is = Config.class.getClassLoader().getResourceAsStream(basePropertiesFilename);
baseProperties.load(is);
} catch (Exception e) {
logger.error("Could not read {} from ClassLoader", basePropertiesFilename, e);
}
Falls LocalProperties geladen werden sollen, muss der Pfad zu der Datei in der Umgebungsvariablen "localconf" übergeben werden:
String localPropertiesProperty = "localconf";
Properties localProperties = new Properties();
logger.debug("----------------------------------------------------------------------------------");
logger.debug("LocalProperties Path from System Environment: {}", systemEnvironmentProperties.getProperty(localPropertiesProperty));
logger.debug("LocalProperties Path from System Properties: {}", systemPropertiesProperties.getProperty(localPropertiesProperty));
String localPropertiesPath = systemPropertiesProperties.getProperty(localPropertiesProperty) != null ? systemPropertiesProperties.getProperty(localPropertiesProperty) : systemEnvironmentProperties.getProperty(localPropertiesProperty);
if (localPropertiesPath == null) {
logger.debug("LocalProperties Path is not set, skip loading Local Properties");
} else {
logger.debug("Load LocalProperties from {}", localPropertiesPath);
try {
localProperties.load(new FileInputStream(localPropertiesPath));
} catch (Exception e) {
logger.error("Could not read {} from File", localPropertiesPath, e);
}
}
Sollen die Umgebungsvariablen auch übernommen werden:
String includeSystemEnvironmentAndPropertiesProperty = "config.includeSystemEnvironmentAndProperties";
String includeS = Stream.of(
systemPropertiesProperties.getProperty(includeSystemEnvironmentAndPropertiesProperty),
systemEnvironmentProperties.getProperty(includeSystemEnvironmentAndPropertiesProperty),
localProperties.getProperty(includeSystemEnvironmentAndPropertiesProperty),
baseProperties.getProperty(includeSystemEnvironmentAndPropertiesProperty))
.filter(Objects::nonNull)
.findFirst()
.orElse(null);
Boolean include = Boolean.parseBoolean(includeS);
Abschließend alle Properties mergen:
Properties mergedProperties = new Properties();
mergedProperties.putAll(baseProperties);
mergedProperties.putAll(localProperties);
if (include) {
mergedProperties.putAll(systemEnvironmentProperties);
mergedProperties.putAll(systemPropertiesProperties);
} else {
mergedProperties.forEach((key, value) -> {
value = systemEnvironmentProperties.getProperty((String)key, (String)value);
value = systemPropertiesProperties.getProperty((String)key, (String)value);
mergedProperties.setProperty((String)key, (String)value);
});
}
Beispiel
In dem vorherigen Post hatte ich die Konfigurierbarkeit von JPA EntityManagerFactory im Code so gelöst:
import static org.hibernate.cfg.AvailableSettings.SHOW_SQL;
Properties properties = new Properties();
Optional.ofNullable(System.getenv(SHOW_SQL)).ifPresent( value -> properties.put(SHOW_SQL, value));
Optional.ofNullable(System.getenv(JPA_JDBC_URL)).ifPresent( value -> properties.put(JPA_JDBC_URL, value));
Optional.ofNullable(System.getenv(JPA_JDBC_USER)).ifPresent( value -> properties.put(JPA_JDBC_USER, value));
Optional.ofNullable(System.getenv(JPA_JDBC_PASSWORD)).ifPresent( value -> properties.put(JPA_JDBC_PASSWORD, value));
EntityManagerFactory emf = Persistence.createEntityManagerFactory("myapp-persistence-unit", properties);
Das lässt sich jetzt einfacher über die Config lösen:
Zuletzt kochte die Log4J Lücke hoch, so dass man sich mit dem Thema Logging auseinander setzen musste.
Mich betraf der Bug nicht besonders, nach eingehender Analyse stellte sich heraus, dass keines meiner im Betrieb befindlichen Projekte Log4J verwendet. Ein Paar Projekte, die ich jahrelang betreuen durfte, waren betroffen, aber für die bin ich nicht mehr verantwortlich und war nur beratend tätig und habe meine Einschätzung und Handlungsempfehlung abgegeben.
Allerdings trägt das grade in der Entwicklung, aber noch nicht in Betrieb gegangene, Projekt Log4J in sich, so dass das Thema vor dem GoLive angegangen werden muss.
Java Logging
Einen sehr schönen, pragmatischen Einstieg in Java Util Logging habe ich auf Java Code Geeks gefunden.
Das einfachste Beispiel, um einen Ausgabe auf der Console zu erhalten:
package deringo.jpa;
import java.util.logging.Logger;
public class TestMain {
public static void main(String[] args) throws Exception {
Logger logger = Logger.getLogger(TestMain.class.getName());
logger.warning("Dies ist nur ein Test!");
}
}
Ein paar Code Beispiele:
package deringo.jpa;
import java.util.logging.ConsoleHandler;
import java.util.logging.Handler;
import java.util.logging.Level;
import java.util.logging.Logger;
public class TestMain {
public static void main(String[] args) throws Exception {
Logger logger = Logger.getLogger(TestMain.class.getName());
logger.warning("Dies ist nur ein Test!");
// Warnung wird ausgegeben, Fine nicht
logger.fine("Eine fine Nachricht. 1");
logger.warning("Eine warnende Nachricht. 1");
// Das Level des Loggers auf ALL setzen
logger.setLevel(Level.ALL);
// Trotzdem: Warnung wird ausgegeben, Fine nicht
logger.fine("Eine fine Nachricht. 2");
logger.warning("Eine warnende Nachricht. 2");
// Einen Handler für den Logger definieren, der Handler Level wird auf ALL gesetzt
Handler consoleHandler = new ConsoleHandler();
consoleHandler.setLevel(Level.ALL);
logger.addHandler(consoleHandler);
// Warnung wird ausgegeben, Fine wird ausgegeben
// ABER: Warnung wird doppelt ausgegeben
logger.fine("Eine fine Nachricht. 3");
logger.warning("Eine warnende Nachricht. 3");
}
}
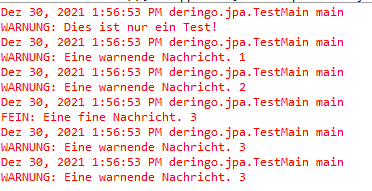
Überraschend ist erstmal, dass die dritte Ausgabe, zumindest für die Warnung, doppelt erscheint.
Die Erklärung ist, dass es noch einen Root Logger gibt, welcher der Parent des TestMain Loggers ist. Standardmäßig gibt ein Logger seine Einträge an den Parent Logger weiter. Bzw. an die Handler des Parent Loggers. Der Root Logger hat die ersten Logs ausgegeben, als der TestMain Logger noch gar keinen Handler hatte, der die Log Einträge verarbeiten konnte.
Wird die Weitergabe an den Parent Handler deaktiviert, wird nicht mehr doppelt geloggt:
package deringo.jpa;
import java.util.logging.ConsoleHandler;
import java.util.logging.Handler;
import java.util.logging.Level;
import java.util.logging.Logger;
public class TestMain {
public static void main(String[] args) throws Exception {
Logger logger = Logger.getLogger(TestMain.class.getName());
// Warnung wird ausgegeben, Fine nicht
logger.fine("Eine fine Nachricht. 1");
logger.warning("Eine warnende Nachricht. 1");
// Nicht an Parent Handler weiter reichen
logger.setUseParentHandlers(false);
// Warnung wird NICHT mehr ausgegeben, Fine ebenfalls nicht
logger.fine("Eine fine Nachricht. 2");
logger.warning("Eine warnende Nachricht. 2");
// Eigenen Handler definieren
Handler consoleHandler = new ConsoleHandler();
consoleHandler.setLevel(Level.ALL);
logger.addHandler(consoleHandler);
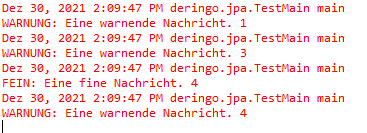
// Warnung wird ausgegeben, Fine wird NICHT ausgegeben
// Warnung wird NICHT doppelt ausgegeben
logger.fine("Eine fine Nachricht. 3");
logger.warning("Eine warnende Nachricht. 3");
// Das Level des Loggers auf ALL setzen
logger.setLevel(Level.ALL);
// Warnung wird ausgegeben, Fine wird ausgegeben
// Warnung wird NICHT doppelt ausgegeben
logger.fine("Eine fine Nachricht. 4");
logger.warning("Eine warnende Nachricht. 4");
}
}
Java Logging - Konfiguration per Datei
Möchte man die Konfiguration des Java Util Loggers nicht per Code, wie oben, vornehmen, sondern per Datei findet sich ein guter Einstieg auf Wikibooks.
Davon abgeleitet meine Konfigurationsdatei logging.properties, die ich in src/main/resources abgelegt habe:
# Der ConsoleHandler gibt die Nachrichten auf std.err aus
#handlers= java.util.logging.ConsoleHandler
# Alternativ können weitere Handler hinzugenommen werden. Hier z.B. der Filehandler
handlers= java.util.logging.FileHandler, java.util.logging.ConsoleHandler
# Festlegen des Standard Loglevels
.level= INFO
############################################################
# Handler specific properties.
# Describes specific configuration info for Handlers.
############################################################
# Die Nachrichten in eine Datei im Benutzerverzeichnis schreiben
java.util.logging.FileHandler.pattern = d:/java%%u.log
java.util.logging.FileHandler.limit = 50000
java.util.logging.FileHandler.count = 1
java.util.logging.FileHandler.formatter = java.util.logging.XMLFormatter
java.util.logging.FileHandler.level = ALL
# Zusätzlich zu den normalen Logleveln kann für jeden Handler noch ein eigener Filter
# vergeben werden. Das ist nützlich wenn beispielsweise alle Nachrichten auf der Konsole ausgeben werden sollen
# aber nur ab INFO in das Logfile geschrieben werden soll.
java.util.logging.ConsoleHandler.level = ALL
java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter
############################################################
# Extraeinstellungen für einzelne Logger
############################################################
# Für einzelne Logger kann ein eigenes Loglevel festgelegt werden.
deringo.jpa.TestMain.level = FINEST
Leider funktionierte es nicht. Es wird nach wie vor die originale logging.properties von Java genommen, die im Java Installationsverzeichnis $JAVA_HOME/jre unterhalb des lib Verzeichnises liegt, bzw. ab Java 9 in $JAVA_HOME/conf. Vgl. Mkyong
Falls nicht die Original-logging.properties-Datei benutzt werden soll, kann über die System-Property java.util.logging.config.file die stattdessen zu verwendende Datei angegeben werden.
Wie das praktisch geht, kann bei Mkyong nachgesehen werden.
Ich habe folgenden Code verwendet:
package deringo.jpa;
import java.util.logging.Logger;
public class TestMain {
public static void main(String[] args) throws Exception {
String path = TestMain.class.getClassLoader().getResource("logging.properties").getFile();
System.setProperty("java.util.logging.config.file", path);
Logger logger = Logger.getLogger(TestMain.class.getName());
// Warnung wird ausgegeben, Fine wird ausgegeben
// Beides auf der Console und in der Datei D:/java0.log
logger.fine("Eine fine Nachricht. 1");
logger.warning("Eine warnende Nachricht. 1");
}
}
Es wird in der Console und der definierten Datei geloggt.
Warum die logging.properties des Projektes nicht standartmäßig anstelle der Java logging.properties gezogen wird, kann ich mir nicht erklären.
SLF4J
SLF4J ist kein Logging Framework, sondern eine Fassade vor der eigentlichen Implementierung. Man kann also im Code mit SLF4J loggen und SLF4J leitet das dann an das gewählte Framework, zB Java Util Logging oder Log4J weiter. So kann man das Logging Framework austauschen ohne den Code anfassen zu müssen.
Ob das jemals jemand vor dem Log4J Bug gemacht hat lasse ich mal dahingestellt, mir gefällt aber das eingebaute Templating, bzw. Parameterisierung, von SLF4J:
Object entry = new SomeObject();
logger.debug("The entry is {}.", entry);
package deringo.jpa.repository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SLF4JTest {
public static void main(String[] args) {
Logger logger = LoggerFactory.getLogger(SLF4JTest.class);
logger.info("Hallo Welt!");
}
}
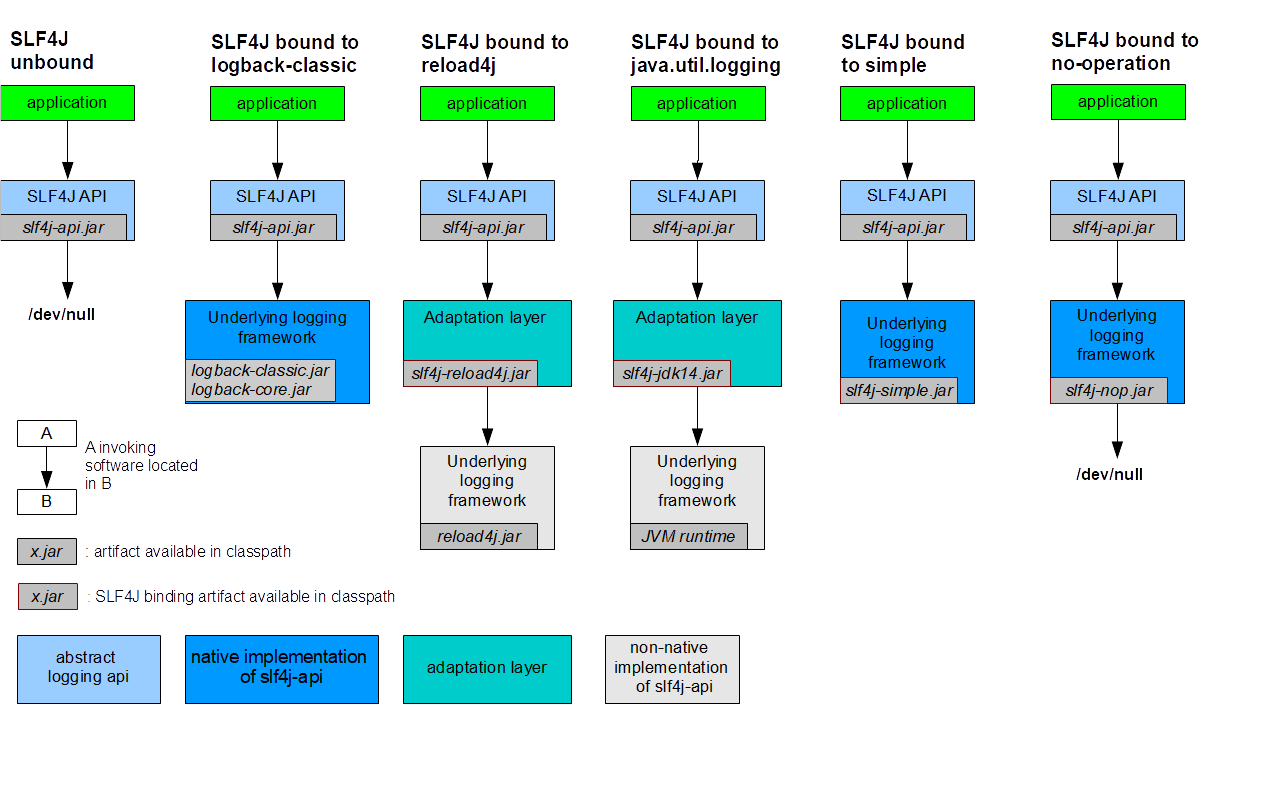
Folgende Grafik aus dem SLF4J Manual zeigt, dass nach /dev/null geloggt wurde:
Es wird also eine Logging Framework Implementierung benötigt.
Ich entscheide mich für das Java Util Logging Framework, denn dieses ist in Java bereits enthalten und ich muss keine weitere Bibliothek, wie zB Log4J, in mein Projekt einbinden.
Es kommt also eine weitere Maven Abhängigkeit hinzu:
package deringo.jpa.repository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SLF4JTest {
public static void main(String[] args) {
Logger logger = LoggerFactory.getLogger(SLF4JTest.class);
logger.info("Hallo Welt!");
}
}
Führt jetzt zu folgender Ausgabe:
Äquivalent zu dem Code Beispiel zu Java Util Logging - Konfiguration per Datei weiter oben, führt folgender Code zusätzlich zu einem Logging in einer Datei:
package deringo.jpa.repository;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SLF4JTest {
public static void main(String[] args) {
String path = SLF4JTest.class.getClassLoader().getResource("logging.properties").getFile();
System.setProperty("java.util.logging.config.file", path);
Logger logger = LoggerFactory.getLogger(SLF4JTest.class);
logger.info("Hallo Welt!");
}
}