Domain
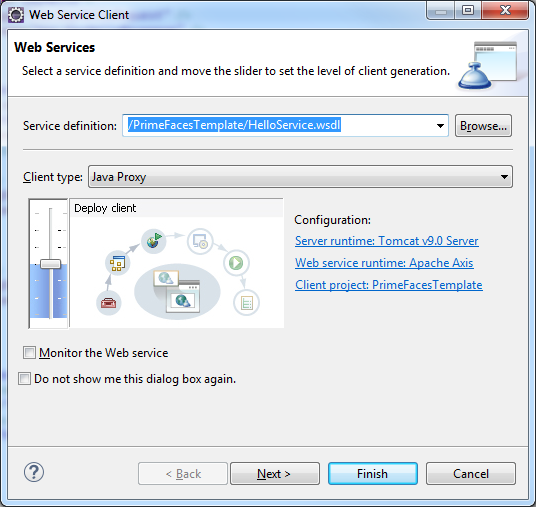
Für ein R&D-Projekt benötige ich eine eigene Domain. Diese soll möglichst günstig zu bekommen sein und das bei einem Anbieter, der eine Bezahlung über Bitcoin oä ermöglicht. Bei der Recherche bin ich dabei auf diesen Anbieter gestoßen: Porkbun
Das Projekt läuft unter dem Arbeitstitel: Dagobert Doge. Also suche ich nach einer entsprechenden Domain:
Es werden einige verfügbare Domains angezeigt:
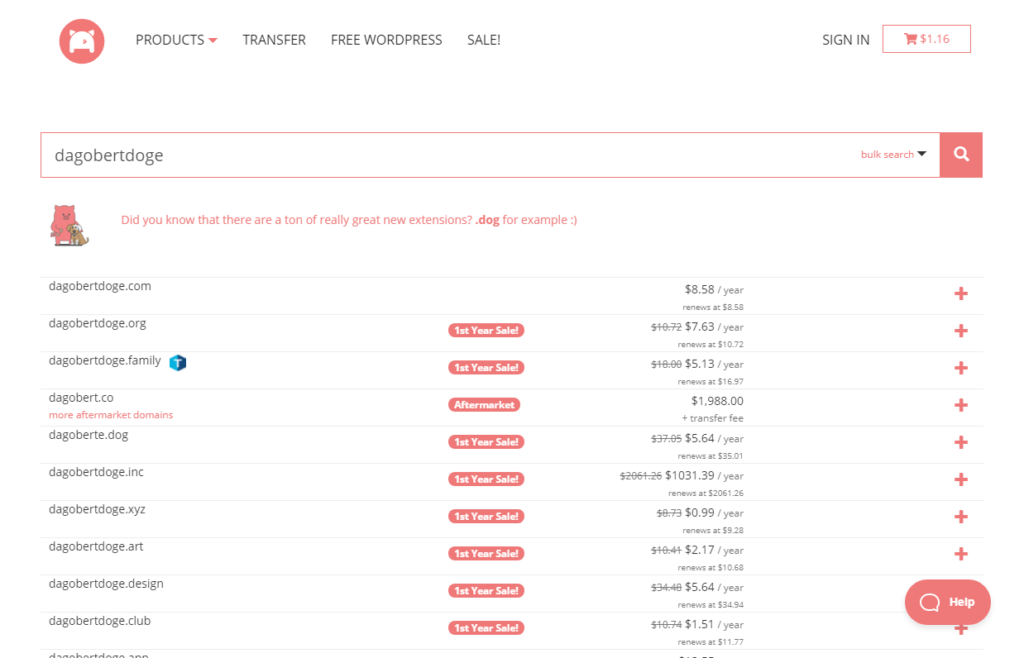
Ich entscheide mich für DagobertDoge.space. Klingt cool und kostet nur 1,16 $ im ersten Jahr:
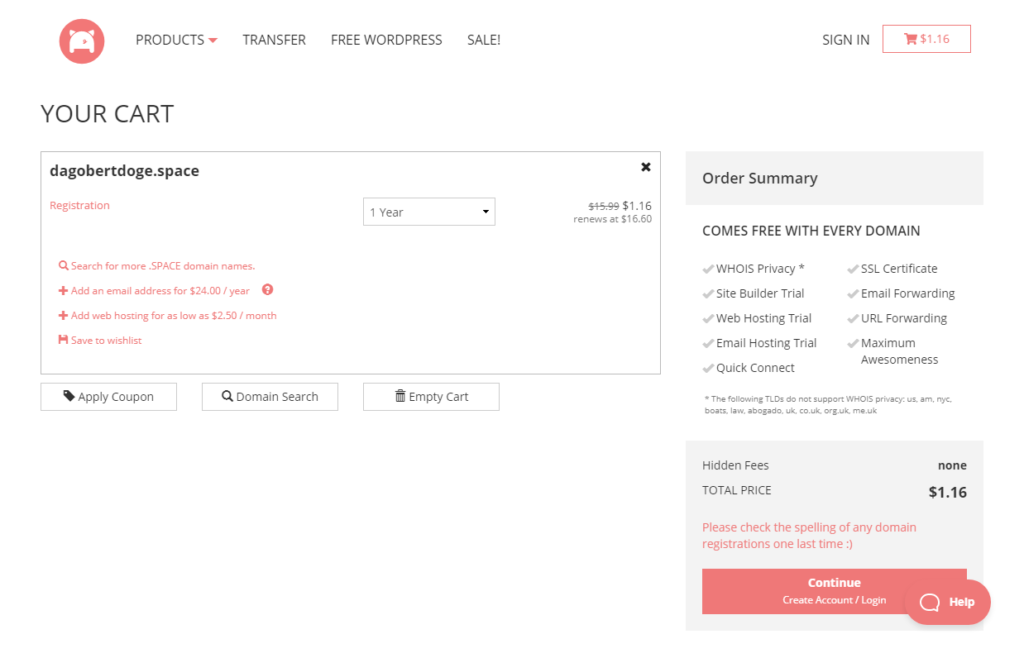
Registrieren, bezahlen und schon erscheint die Domain im Domain Management:
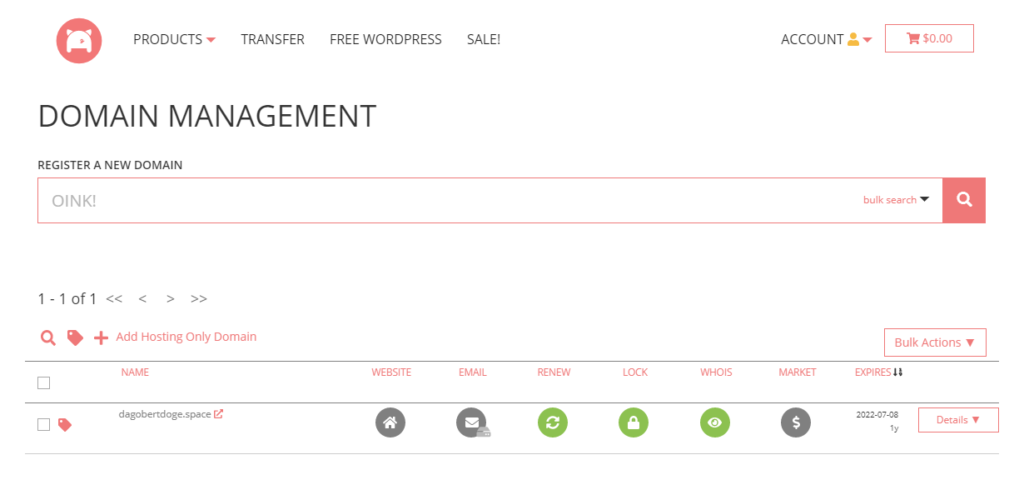
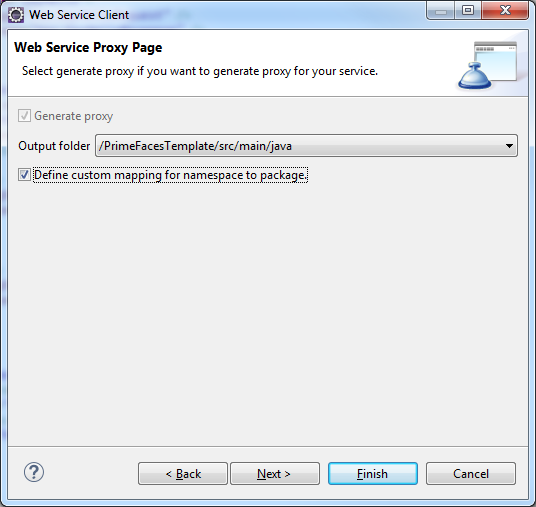
Die Einrichtung eines gehosteten Email Accounts wird in der Knowledge Base von Porkbun beschrieben. Der erste Monat ist kostenfrei.
Domain Management -> Email -> Option 1: Email Hosting -> Configure
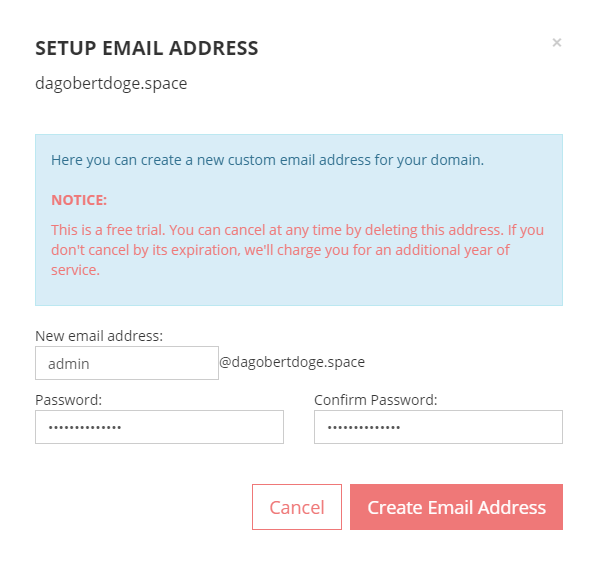
Nach dem einmonatigem Testzeitraum wird die Gebühr für ein ganzes Jahr eingezogen, also noch flugs einen Reminder zum rechtzeitigen Löschen angelegt.
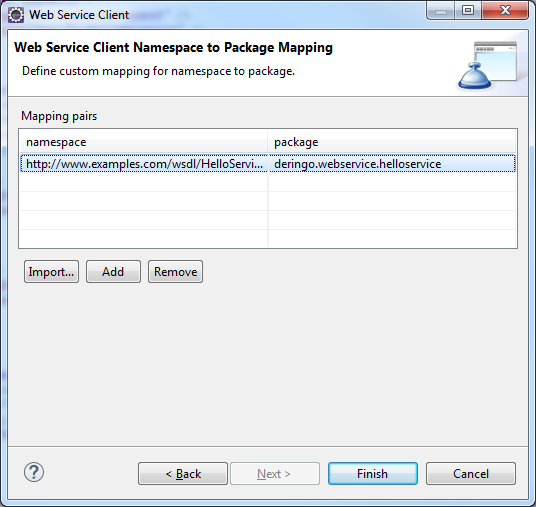
Anschließend werden die Email Configuration Settings angezeigt, sehr hilfeich. Außerdem eine DMARC Notice. Wenn man auf den Configure Button klickt, werden die Einstellungen automatisch vorgenommen. Was es mit DMARC genau auf sich hat muss ich bei Gelegenheit evaluieren.

Der Webmail Client präsentiert sich sehr aufgeräumt, nice:
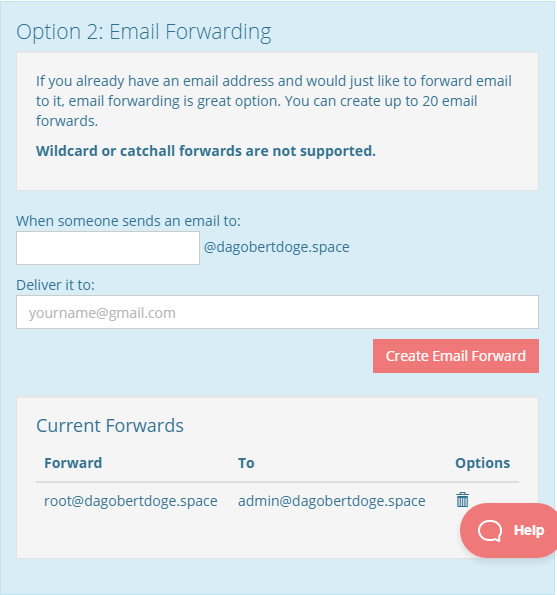
Alternativ wäre auch ein dauerhaft kostenfreies Email Forwarding möglich:
Website auf Github Pages
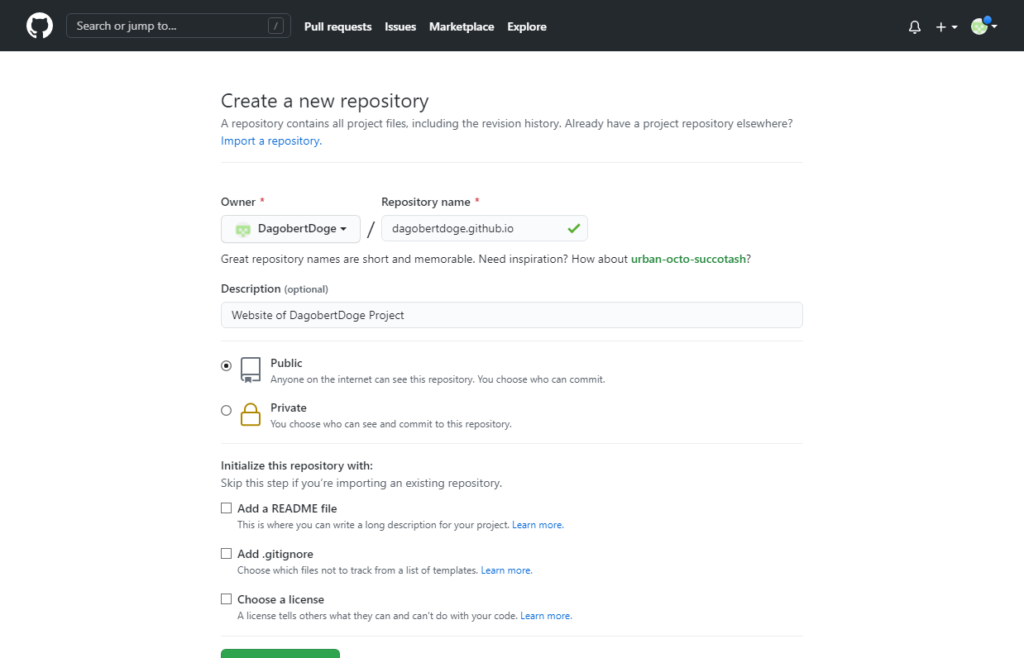
Die Website soll auf Github Pages gehostet werden. Das ist kostenfrei und über die üblichen Git Tools editierbar. Zumindest stelle ich mir das so vor, der Test kommt jetzt:
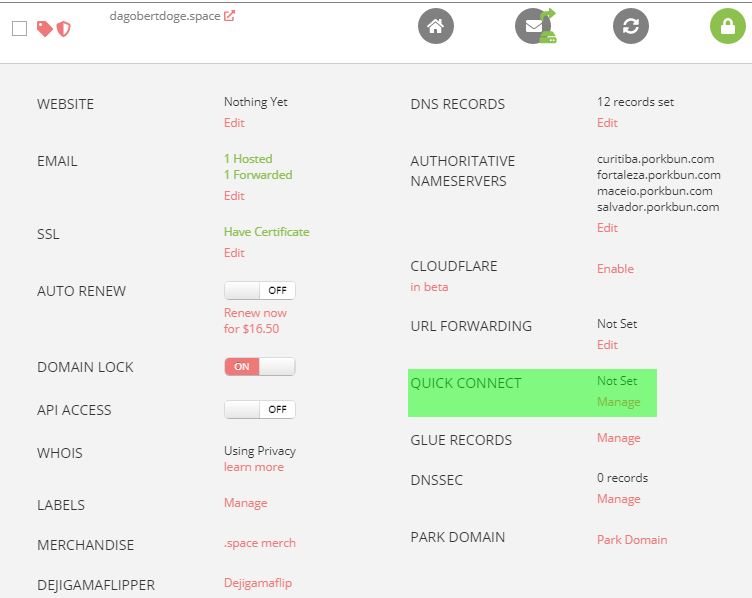
In den Details des Domain Managements -> Quick Connect -> Manage:
Github auswählen und einen neuen Account anlegen:

Auf I Need One klicken, schon öffnet sich GitHub in einem neuen Tab:
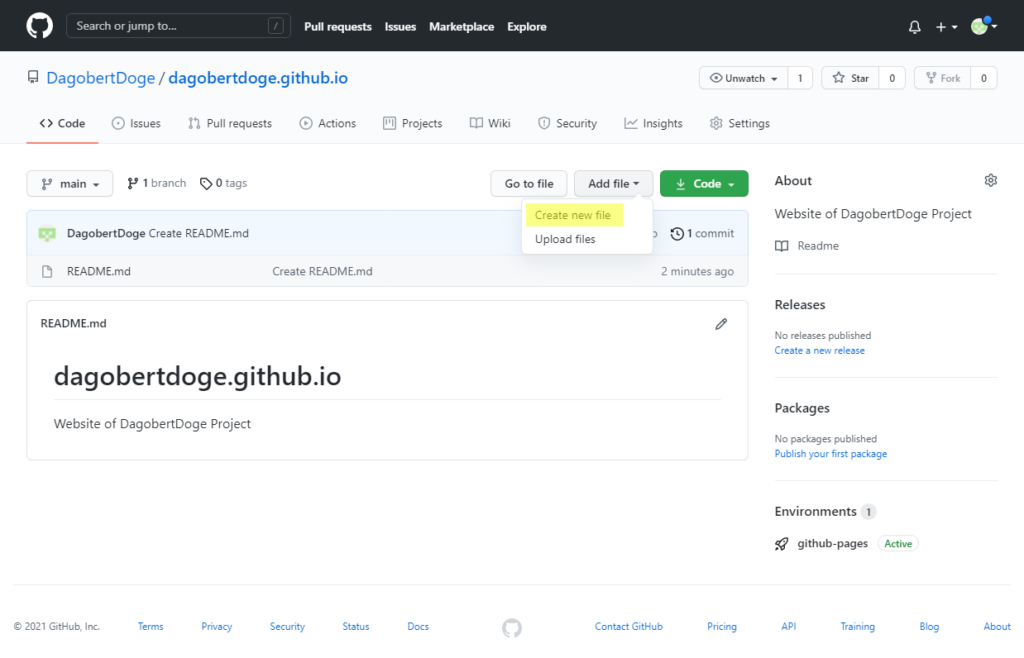
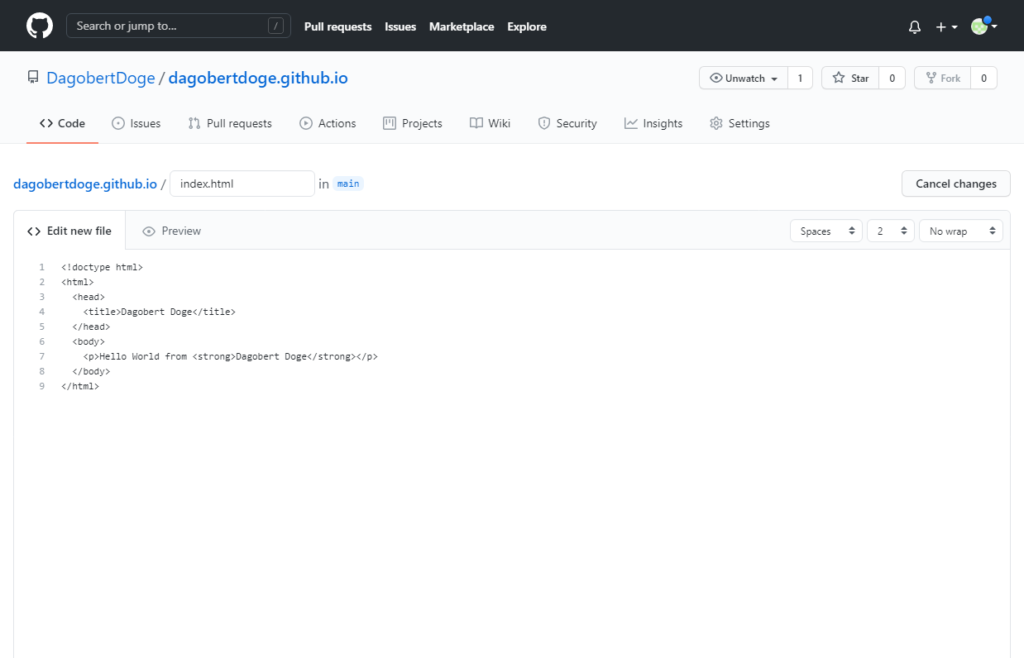
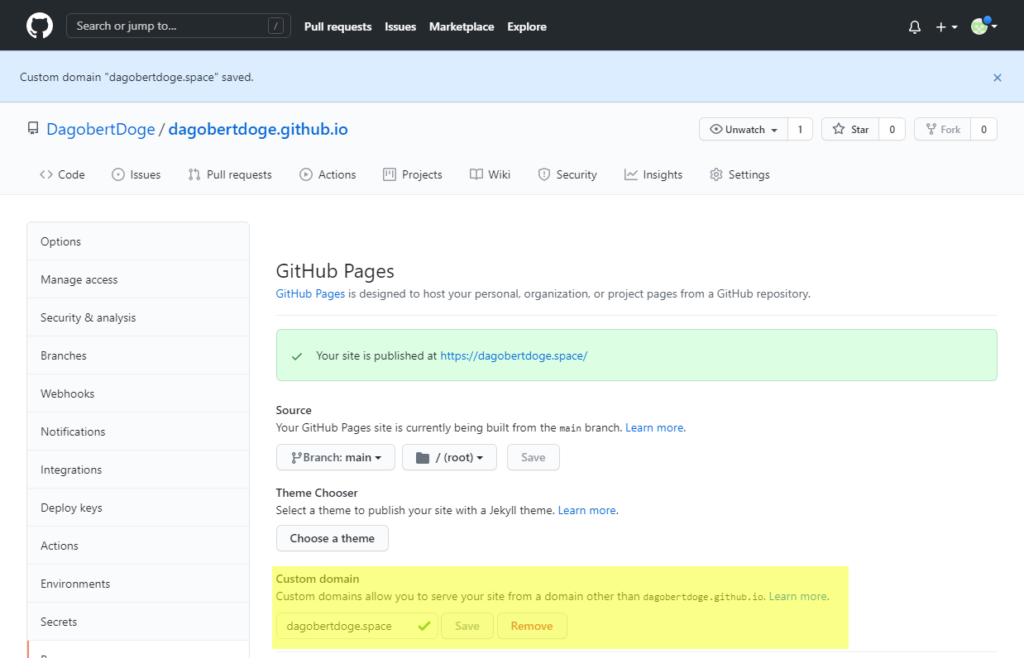
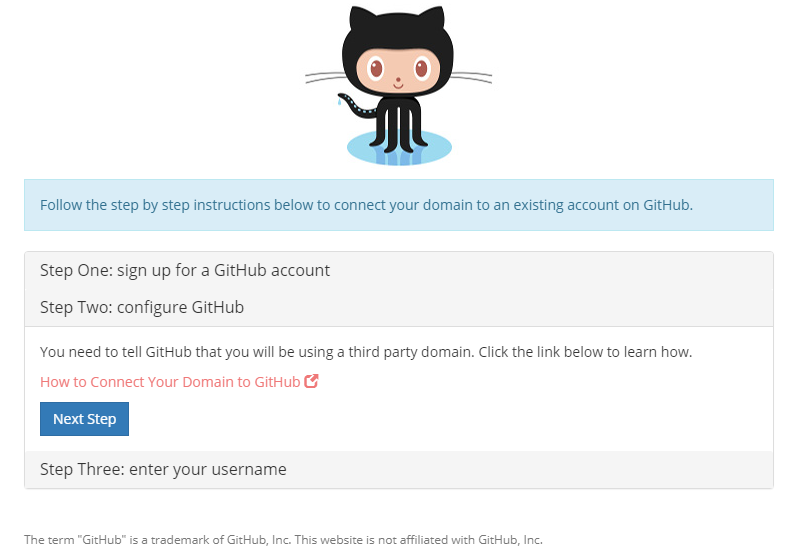
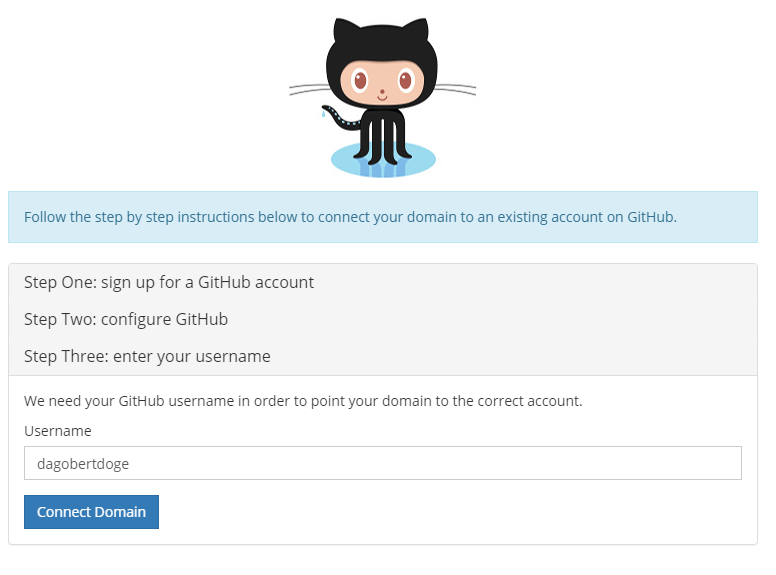

Und siehe da, wenn wir jetzt DagobertDoge öffnen, sehen wir:

Die Website - Ein Template
Die HelloWorld-Seite sieht maximal spartanisch aus, daher habe ich ein frei verfüg- und nutzbares Template für eine fancy Website gesucht und auf html DESIGN gefunden:
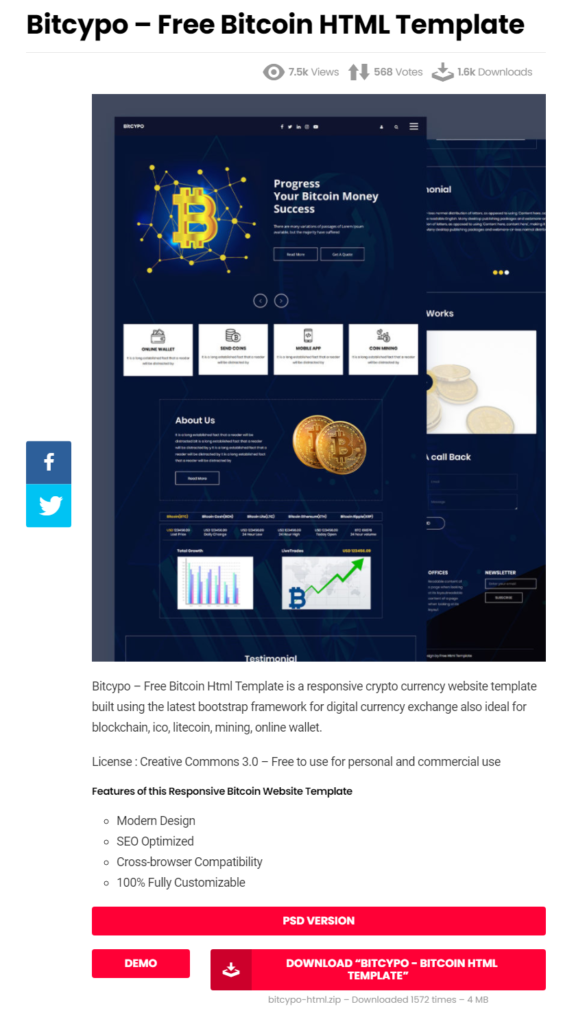
Die Website - Das Projekt
Das Git Projekt auf meinen Arbeitsrechner clonen:
cd [...]/workspace git clone https://github.com/DagobertDoge/dagobertdoge.github.io.git cd dagobertdoge.github.io
Die Dateien aus dem Bitcypo Template werden in das dagobertdoge.github.io Verzeichnis kopiert.
Git einrichten und Änderungen in das Repository übertragen:
git config user.email "admin@dagobertdoge.space" git config user.name "DagobertDoge" git add * git commit git push Username for 'https://github.com': DagobertDoge Password for 'https://DagobertDoge@github.com': xxx
Dann noch ein paar kleine Anpassungen im HTML und in einem Image & dann das ganze ins GitHub Repository pushen.
Die Website - Das erste Resultat
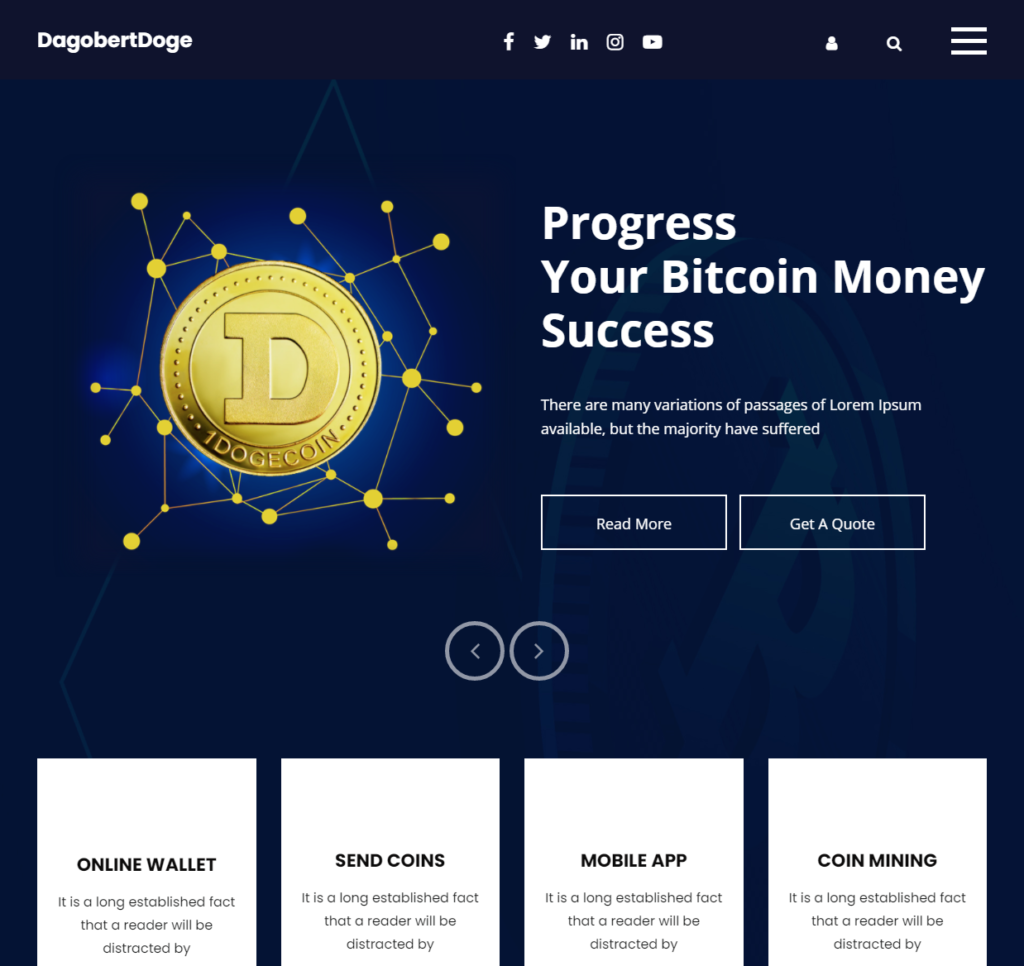
Whois
Eine Whois-Abfrage ergab, dass keinerlei persönlichen Informationen von mir im Whois Record eingetragen wurden. Ich brauche also keine Angst vor zB Spam haben.
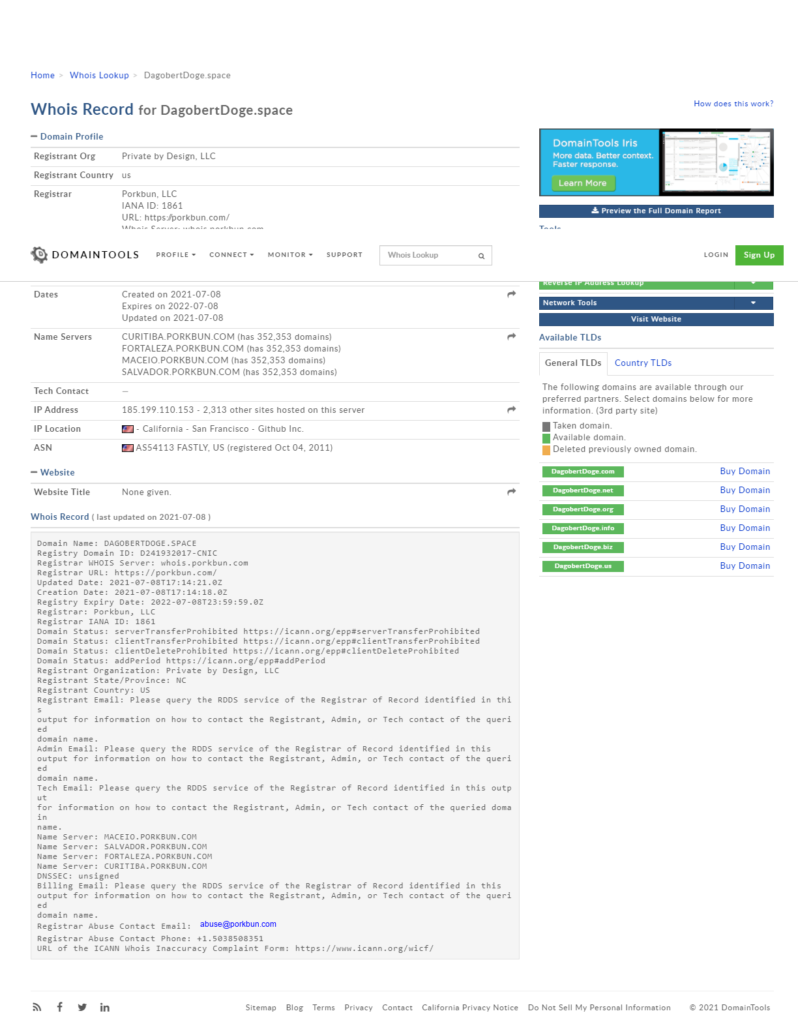
Abschluss
Die Etappenziele sind erreicht: Eine eigene Domain für schmales Geld, Webmail für zumindest einen Monat, danach wenigstens noch die Mailweiterleitung. Bei Gelegenheit sollte ich mal schauen, ob es nicht einen Dienst gibt, der einem gratis das Mailhosting übernimmt. Das müsste ja technisch möglich sein über einen entsprechenden Eintrag im MX Record.
Das Repository für den Code der Website und sogar das Hosting der (statischen) Seite gibt es for free.
Ein Template für die erste Version der Website gibt es auch for free.
Nachtrag: Basic authentication deprecation
Nach dem Checkin in GitHub erreichte mich diese EMail:
Hi @DagobertDoge,
You recently used a password to access the repository at DagobertDoge/dagobertdoge.github.io with git using git/2.20.1.
Basic authentication using a password to Git is deprecated and will soon no longer work. Visit https://github.blog/2020-12-15-token-authentication-requirements-for-git-operations/ for more information around suggested workarounds and removal dates.
Thanks,
The GitHub TeamFür die Verwendung über die Konsole benötige ich also einen personal access token, sonst ist bald Schluß mit Lustig.
Der Anleitung folgend auf das Profil Photo klicken -> Settings -> Developer Settings -> Personal access tokens -> Generate a personal access token:
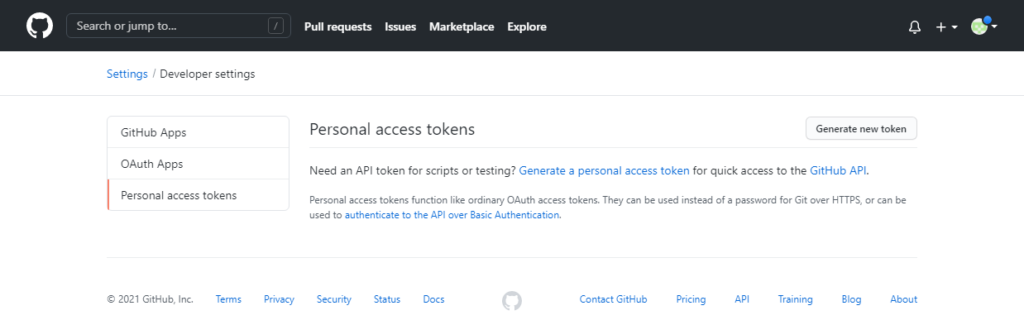
Generate new token with descriptive name and permissions. To use your token to access repositories from the command line, select repo.
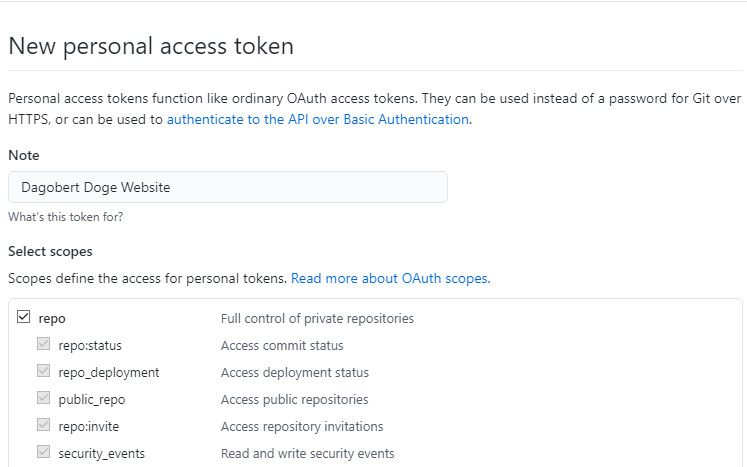
Es wird ein Personal access token generiert und angezeigt. Dieser ist unbedingt zu notieren, denn er kann nicht noch einmal angezeigt werden.
"Once you have a token, you can enter it instead of your password when performing Git operations over HTTPS."
Damit ich nicht bei jedem Commit etc. den Username & Token eingeben muss, aktiviere ich das Caching der Credentials:
# Set git to use the credential memory cache $ git config --global credential.helper cache # Set the cache to timeout after 1 hour (setting is in seconds) $ git config --global credential.helper 'cache --timeout=3600'
Git kann jetzt wie zuvor verwendet werden. Beim ersten Befehl muss einmalig Username & Token eingegeben werden, diese werden für die darauffolgende Stunde gecached.