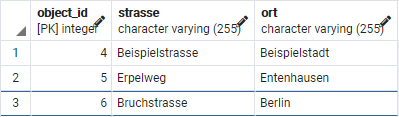
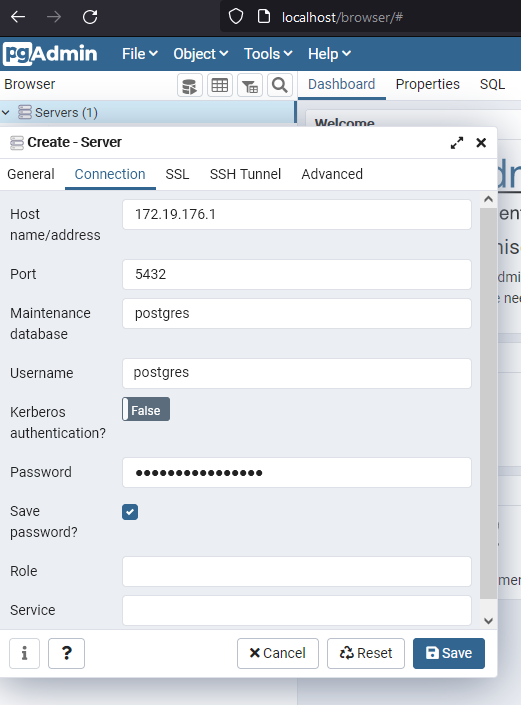
Mein Ziel war es, JPA konfigurativ ohne persistence.xml zu verwenden. Das habe ich nicht ganz geschafft, aber schon mal den Weg erarbeitet, wie es prinzipiell funktionieren könnte.
Hintergrund ist einfach der, dass ich in der persistence.xml die Konfiguration meiner Datenbank hinterlegen kann, aber wenn ich das war-File baue und auf den produktiven Server schiebe, dann möchte ich, dass diese Konfiguration durch die der produktiven Datenbank überschrieben werden kann.
persistence.xml
Die im vorherigen Post zu JPA sieht folgendermaßen aus:
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd"
version="2.2">
<persistence-unit name="myapp-persistence-unit">
<properties>
<!-- Configure a database connection in Java SE -->
<property name="javax.persistence.jdbc.driver" value="org.postgresql.Driver" />
<property name="javax.persistence.jdbc.url" value="jdbc:postgresql://127.0.0.1:5432/myapp" />
<property name="javax.persistence.jdbc.user" value="postgres" />
<property name="javax.persistence.jdbc.password" value="PASSWORD" />
<!-- Configure timeouts -->
<property name="javax.persistence.lock.timeout" value="100"/>
<property name="javax.persistence.query.timeout" value="100"/>
</properties>
</persistence-unit>
</persistence>
persistence.xml löschen
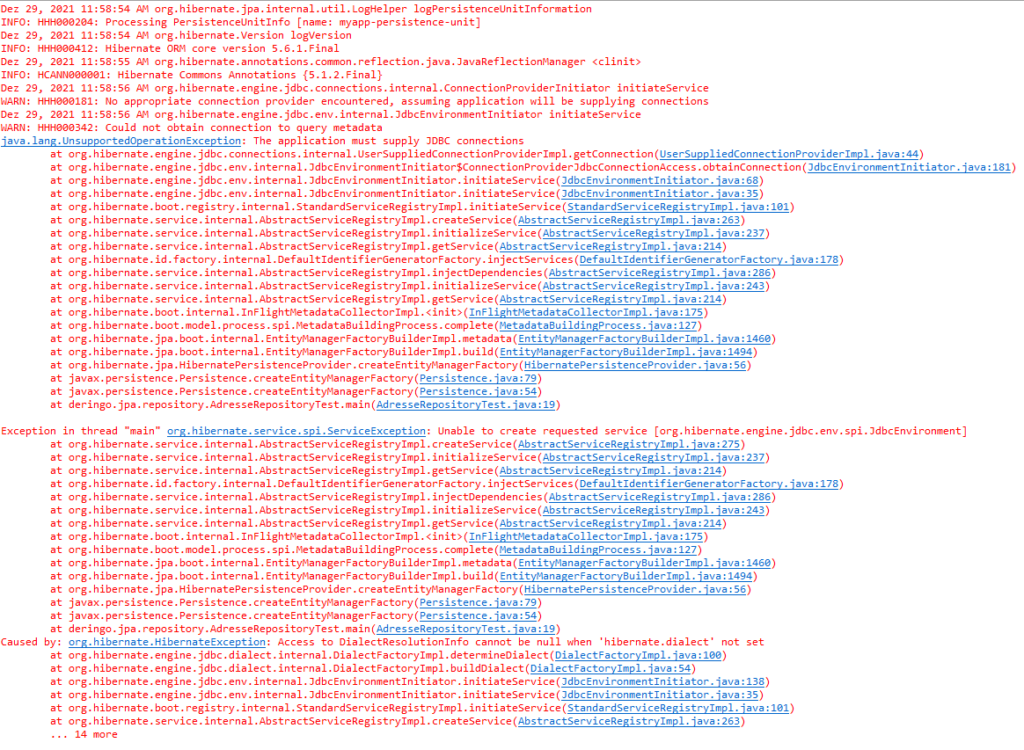
Der Versuch, die persistence.xml zu löschen führt zu einem Fehler:

persistence.xml minimal
Der einfachste Weg, diesen Fehler zum umgehen, ist eine minimale persistence.xml anzulegen:
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd"
version="2.2">
<persistence-unit name="myapp-persistence-unit">
<properties>
</properties>
</persistence-unit>
</persistence>
Wird der EntityManager wie bisher erzeugt, gibt es einen Fehler:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("myapp-persistence-unit");
Konfiguration im Java Code
Die ursprüngliche Konfiguration aus der persistence.xml wird jetzt im Java Code vorgenommen:
Properties properties = new Properties();
properties.put("javax.persistence.jdbc.driver", "org.postgresql.Driver");
properties.put("javax.persistence.jdbc.url", "jdbc:postgresql://127.0.0.1:5432/myapp");
properties.put("javax.persistence.jdbc.user", "postgres");
properties.put("javax.persistence.jdbc.password", "PASSWORD");
properties.put("javax.persistence.lock.timeout", "100");
properties.put("javax.persistence.query.timeout", "100");
Der EntityManager wird dann ganz einfach fehlerfrei wie folgt erzeugt:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("myapp-persistence-unit", properties);
DB Zugriff testen
Um den fehlerhaften Zugriff mit minimaler persistence.xml zu testen:
// Test 'broken' persistence.xml
Error error = assertThrows(NoClassDefFoundError.class, () -> {
AdresseRepository.getLastObjectID();
});
assertTrue(error != null);
Um den fehlerlosen Zugriff mit minimaler persistence.xml und Java Konfiguration zu testen:
Properties properties = new Properties();
properties.put("javax.persistence.jdbc.driver", "org.postgresql.Driver");
properties.put("javax.persistence.jdbc.url", "jdbc:postgresql://127.0.0.1:5432/myapp");
properties.put("javax.persistence.jdbc.user", "postgres");
properties.put("javax.persistence.jdbc.password", "PASSWORD");
properties.put("javax.persistence.lock.timeout", "100");
properties.put("javax.persistence.query.timeout", "100");
EntityManagerFactory emf = Persistence.createEntityManagerFactory("myapp-persistence-unit", properties);
String sequenceName = "public.object_id_seq";
String sql = "SELECT s.last_value FROM " + sequenceName + " s";
EntityManager em = emf.createEntityManager();
BigInteger value = (BigInteger)em.createNativeQuery(sql).getSingleResult();
assertNotNull(value);
Anderer Error Bugfix
Nach meiner Mittagspause hat sich der Test auf einmal anders verhalten und es wurde kein NoClassDefFoundError geschmissen, sondern ein ExceptionInInizlialisationError. Warum dem so ist 🤷♂️.
Beide Errors erweitern allerdings den LinkageError, also ist mein Test fix gefixt:
// Test 'broken' persistence.xml
Error error = assertThrows(LinkageError.class, () -> {
AdresseRepository.getLastObjectID();
});
assertTrue(error != null);
Available Settings
Die Konstanten der verfügbaren Einstellungen sind in der Klasse org.hibernate.cfg.AvailableSettings zu finden.
Dadurch lassen sich die Properties etwas eleganter setzen:
properties.put(org.hibernate.cfg.AvailableSettings.SHOW_SQL, Boolean.TRUE); // bzw. properties.put(AvailableSettings.SHOW_SQL, Boolean.TRUE); // oder import static org.hibernate.cfg.AvailableSettings.*; properties.put(SHOW_SQL, Boolean.TRUE);
Umsetzungsvorschlag
Am einfachsten lasse ich meine persistence.xml wie bisher, mit den Einstellungen der Entwicklungsdatenbank.
Einstellungen wie zB der JDBC Driver bleiben auf allen Systemen gleich. Lediglich die URL, Username und das Passwort werden sich ändern.
Diese Werte können als Umgebungsvariable gesetzt werden, zB in einem Docker-File oder im Tomcat, und dann die Werte der persistence.xml überschreiben.
Also wieder die komplette persistence.xml nutzen:
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd"
version="2.2">
<persistence-unit name="myapp-persistence-unit">
<properties>
<!-- Configure a database connection in Java SE -->
<property name="javax.persistence.jdbc.driver" value="org.postgresql.Driver" />
<property name="javax.persistence.jdbc.url" value="jdbc:postgresql://127.0.0.1:5432/myapp" />
<property name="javax.persistence.jdbc.user" value="postgres" />
<property name="javax.persistence.jdbc.password" value="PASSWORD" />
<!-- Configure timeouts -->
<property name="javax.persistence.lock.timeout" value="100"/>
<property name="javax.persistence.query.timeout" value="100"/>
</properties>
</persistence-unit>
</persistence>
Im Java Code könnte man dann die Werte überschreiben, beispielsweise für das Anzeigen der SQLs:
Properties properties = new Properties();
Optional.ofNullable(System.getenv(SHOW_SQL)).ifPresent( value -> properties.put(SHOW_SQL, value));
EntityManagerFactory emf = Persistence.createEntityManagerFactory("myapp-persistence-unit", properties);
Alternativ könnte man auch den Pfad zu einer Konfigurationsdatei auf dem Server setzen und dann von dort die Werte auslesen.